







Linux Kernel代码版本v5.15.110。
目录
KVM-DEBUGFS
DST.1 概述
kvm通过/sys/kernel/debug/kvm输出统计数据,其分为三层:kvm、vm和vcpu;参考:

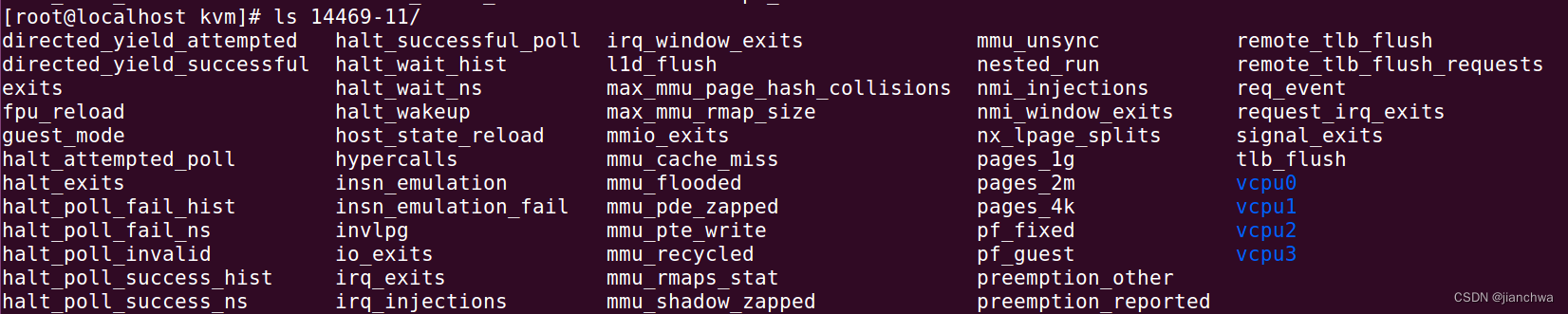

参考kvm代码,看下这几个目录都是在什么时候创建的,
vmx_init()
-> kvm_init()
-> kvm_init_debug()
---
kvm_debugfs_dir = debugfs_create_dir("kvm", NULL);
for (i = 0; i < kvm_vm_stats_header.num_desc; ++i) {
pdesc = &kvm_vm_stats_desc[i];
if (kvm_stats_debugfs_mode(pdesc) & 0222)
fops = &vm_stat_fops;
else
fops = &vm_stat_readonly_fops;
debugfs_create_file(pdesc->name, kvm_stats_debugfs_mode(pdesc), kvm_debugfs_dir, (void *)(long)pdesc->desc.offset, fops);
}
for (i = 0; i < kvm_vcpu_stats_header.num_desc; ++i) {
pdesc = &kvm_vcpu_stats_desc[i];
if (kvm_stats_debugfs_mode(pdesc) & 0222)
fops = &vcpu_stat_fops;
else
fops = &vcpu_stat_readonly_fops;
debugfs_create_file(pdesc->name, kvm_stats_debugfs_mode(pdesc), kvm_debugfs_dir, (void *)(long)pdesc->desc.offset, fops);
}
---
KVM_CREATE_VM
kvm_dev_ioctl_create_vm()
-> kvm_create_vm_debugfs()
---
for (i = 0; i < kvm_vm_stats_header.num_desc; ++i) {
pdesc = &kvm_vm_stats_desc[i];
...
debugfs_create_file(pdesc->name, kvm_stats_debugfs_mode(pdesc),
kvm->debugfs_dentry, stat_data, &stat_fops_per_vm);
}
for (i = 0; i < kvm_vcpu_stats_header.num_desc; ++i) {
pdesc = &kvm_vcpu_stats_desc[i];
...
debugfs_create_file(pdesc->name, kvm_stats_debugfs_mode(pdesc),
kvm->debugfs_dentry, stat_data,
&stat_fops_per_vm);
}
ret = kvm_arch_create_vm_debugfs(kvm);
-> debugfs_create_file("mmu_rmaps_stat", 0644, kvm->debugfs_dentry, kvm, &mmu_rmaps_stat_fops);
---
KVM_CREATE_VCPU
kvm_vm_ioctl_create_vcpu()
-> kvm_create_vcpu_debugfs()
---
snprintf(dir_name, sizeof(dir_name), "vcpu%d", vcpu->vcpu_id);
debugfs_dentry = debugfs_create_dir(dir_name,
vcpu->kvm->debugfs_dentry);
kvm_arch_create_vcpu_debugfs(vcpu, debugfs_dentry);
---
debugfs_create_file("guest_mode", 0444, debugfs_dentry, vcpu,
&vcpu_guest_mode_fops);
debugfs_create_file("tsc-offset", 0444, debugfs_dentry, vcpu,
&vcpu_tsc_offset_fops);
if (lapic_in_kernel(vcpu))
debugfs_create_file("lapic_timer_advance_ns", 0444,
debugfs_dentry, vcpu,
&vcpu_timer_advance_ns_fops);
if (kvm_has_tsc_control) {
debugfs_create_file("tsc-scaling-ratio", 0444,
debugfs_dentry, vcpu,
&vcpu_tsc_scaling_fops);
debugfs_create_file("tsc-scaling-ratio-frac-bits", 0444,
debugfs_dentry, vcpu,
&vcpu_tsc_scaling_frac_fops);
}
---
---
其中比较值得注意的点是,无论kvm级还是vm级,都是用到了下面两个全局变量,也就是说,他们有部分的接口是相同的;区别在于,在统计值的时候,kvm级别的接口会遍历每一个vm,参考如下代码:
kvm_vm_stats_desc
kvm_vcpu_stats_desc
stat_fops_per_vm
-> kvm_stat_data_get
-> kvm_get_stat_per_vm()
stat_fops_per_vm
-> kvm_stat_data_get
-> kvm_get_stat_per_vm()
---
*val = *(u64 *)((void *)(&kvm->stat) + offset);
---
-> kvm_get_stat_per_vcpu()
---
kvm_for_each_vcpu(i, vcpu, kvm)
*val += *(u64 *)((void *)(&vcpu->stat) + offset);
---
vm_stat_fops
-> vm_stat_get()
---
list_for_each_entry(kvm, &vm_list, vm_list) {
kvm_get_stat_per_vm(kvm, offset, &tmp_val);
*val += tmp_val;
}
---
这里的offset定义来自
kvm_vm_stat_desc和kvm_vcpu_stat_desc的定义中的宏,参考其中的一个,
#define VCPU_STATS_DESC(stat, type, unit, base, exp, sz, bsz) \
{ \
{ \
STATS_DESC_COMMON(type, unit, base, exp, sz, bsz), \
.offset = offsetof(struct kvm_vcpu_stat, stat) \
}, \
.name = #stat, \
}
DST.2 VM-Exit
下面看下debug接口中,几个关于vm-exit的统计指标。
- exits,所有的vm-exit的数量,
vcpu_enter_guest() --- ++vcpu->stat.exits; --- - io_exits,pio指令导致的vm-exit,
handle_io() //EXIT_REASON_IO_INSTRUCTION --- ++vcpu->stat.io_exits; --- - irq_exits,外部中断导致的vm-exit,
handle_external_interrupt() // EXIT_REASON_EXTERNAL_INTERRUPT --- ++vcpu->stat.irq_exits; --- Note: irq has been handled by vmx_handle_exit_irqoff() before enter into vmx_handle_exit() halt_exits kvm_emulate_halt() //EXIT_REASON_HLT -> kvm_vcpu_halt() -> __kvm_vcpu_halt() --- ++vcpu->stat.halt_exits; --- - signal_exits,因信号导致的vm-exit;发送信号使,如果任务处于runnig状态,会发送resched ipi,
vcpu_run() --- for (;;) { vcpu->arch.at_instruction_boundary = false; if (kvm_vcpu_running(vcpu)) { r = vcpu_enter_guest(vcpu); } ... if (__xfer_to_guest_mode_work_pending()) { r = xfer_to_guest_mode_handle_work(vcpu); -> xfer_to_guest_mode_work() -> kvm_handle_signal_exit() //_TIF_SIGPENDING --- vcpu->run->exit_reason = KVM_EXIT_INTR; vcpu->stat.signal_exits++; --- ... } } --- send_signal() -> __send_signal() -> complete_signal() -> signal_wake_up() -> signal_wake_up_state() --- if (!wake_up_state(t, state | TASK_INTERRUPTIBLE)) kick_process(t); ---
irq_window_exits
什么事irq_window ? 参考SDM 3 33.2 INTERRUPT HANDLING IN VMX OPERATION
When set to 1, the “interrupt-window exiting” VM-execution control (Section 24.6.2) causes VM exits when guest RFLAGS.IF is 1 and no other conditions block external interrupts. A VM exit occurs at the beginning of any instruction at which RFLAGS.IF = 1 and on which the interruptibility state of the guest would allow delivery of an interrupt. For example: when the guest executes an STI instruction, RFLAGS = 1, and if at the completion of next instruction the interruptibility state masking due to STI is removed; a VM exit occurs if the “interrupt-window exiting” VM-execution control is 1. This feature allows a VMM to queue a virtual interrupt to the guest when the guest is not in an interruptible state.
为了保证GuestOS在解除禁止中断后,KVM能够第一时间进行中断注入,Intel-vmx会让Guest在Enable中断时发生vm-exit,这就是irq-window-exit;参考相关指标的统计方式:
handle_external_interrupt() //EXIT_REASON_INTERRUPT_WINDOW
---
// Make it to recheck whether need to inject interrupt
kvm_make_request(KVM_REQ_EVENT, vcpu);
++vcpu->stat.irq_window_exits;
---
nmi_window_exits is similar with irq_window_exitsio_exits在handle_io()中进行了计数,所以,它代表的是所有io_exit;但是mmio_exit,有所不同,参考代码:
//内核态的MMIO处理在这里进行
emulator_read_write_onepage()
---
/*
* Is this MMIO handled locally?
*/
handled = ops->read_write_mmio(vcpu, gpa, bytes, val);
if (handled == bytes)
return X86EMUL_CONTINUE;
...
frag = &vcpu->mmio_fragments[vcpu->mmio_nr_fragments++];
...
return X86EMUL_CONTINUE;
---
如果内核态已经把MMIO处理完了,则直接返回,mmio_needed不会被设置
emulator_read_write()
---
vcpu->mmio_nr_fragments = 0;
...
rc = emulator_read_write_onepage(addr, val, bytes, exception,
vcpu, ops);
if (rc != X86EMUL_CONTINUE)
return rc;
if (!vcpu->mmio_nr_fragments)
return rc;
...
vcpu->mmio_needed = 1;
....
---
mmio_needed如果被设置了,则增加mmio_exits,同时rc = 0
x86_emulate_instruction()
---
if (ctxt->have_exception) {
...
} else if (vcpu->arch.pio.count) {
...
} else if (vcpu->mmio_needed) {
++vcpu->stat.mmio_exits;
...
r = 0;
vcpu->arch.complete_userspace_io = complete_emulated_mmio;
} else if (r == EMULATION_RESTART)
goto restart;
else
r = 1;
---
而vcpu_enter_guest()的返回值如果为0,它会返回用户态qemu
vcpu_run()
---
for (;;) {
if (kvm_vcpu_running(vcpu)) {
r = vcpu_enter_guest(vcpu);
} else {
r = vcpu_block(kvm, vcpu);
}
if (r <= 0)
break;
...
}
---
综上,mmio_exits代表的是返回用户态的mmio_exits ...
DST.3 Preemption
有关kvm vcpu被抢占,有两个指标,preemption_reported和preemption_other;我们看下代码:
__schedule()
-> context_switch()
-> prepare_task_switch
-> fire_sched_out_preempt_notifiers()
-> kvm_sched_out() // set vcpu->preempted to be true if it is on_rq
-> kvm_arch_vcpu_put()
-> kvm_steal_time_set_preempted()
---
if (!vcpu->arch.at_instruction_boundary) {
vcpu->stat.preemption_other++;
return;
}
vcpu->stat.preemption_reported++;
---
那么这两个指标有什么区别呢?参考指标引入的commit comment,
KVM: x86: do not report a vCPU as preempted outside instruction boundaries
[ Upstream commit 6cd88243c7e03845a450795e134b488fc2afb736 ]
If a vCPU is outside guest mode and is scheduled out, it might be in the
process of making a memory access. A problem occurs if another vCPU uses
the PV TLB flush feature during the period when the vCPU is scheduled
out, and a virtual address has already been translated but has not yet
been accessed, because this is equivalent to using a stale TLB entry.
To avoid this, only report a vCPU as preempted if sure that the guest
is at an instruction boundary. A rescheduling request will be delivered
to the host physical CPU as an external interrupt, so for simplicity
consider any vmexit *not* instruction boundary except for external
interrupts.
......
VM-Exit可以分成两种:
- 在指令完成之后发生的,比如中断引起的;
- 在指令执行过程中发生的,比如MMIO;
对于第二种情况,与pv tlb flush发生在一起时,会导致stale tlb entry问题;pv tlb flush的原理简单来说就是:
- kvm_steal_time_set_preempt()设置该vcpu KVM_VCPU_PREEMPTED标记
- guest kernel在发送tlb flush的时候,如果发现这个vcpu设置了KVM_VCPU_PREEMPTED,就知道了它被preempt了,于是,给它设置一个KVM_VCPU_FLUSH_TLB标记
- vcpu再被调度回来的时候,即record_steal_time(),会检查KVM_VCPU_FLUSH_TLB标记,如果设置了, 就会主动做一次tlb flush
如果没有pv tlb flush,这过程是这样的:
- 发送tlb flush的vcpu因为发送ipi发生vm-exit,参考native_flush_tlb_multi();
- 通过lapic模拟,给目标vcpu注入ipi中断;
- 等目标vcpu回来的时候,触发中断,并执行tlb flush操作
那么为什么pv tlb flush就有stable tlb entry的问题呢?
这里有两个点:
第一,没有pv tlb flush时,执行tlb flush操作是在vcpu返回后的中断上下文里,这可以此时之前的指令一定已经完成了;参考SDM 3 6.6 PROGRAM OR TASK RESTART
To allow the restarting of program or task following the handling of an exception or an interrupt, all exceptions (except aborts) are guaranteed to report exceptions on an instruction boundary. All interrupts are guaranteed to be taken on an instruction boundary.
第二,我们先看下tlb flush使用的场景:
ptep_clear_flush()
---
pte = ptep_get_and_clear(mm, address, ptep);
if (pte_accessible(mm, pte))
flush_tlb_page(vma, address);
---在执行完pte_clear_flush()之后,就不会有进程可以再通过这个VA访问到这个PA;但是如果我们回到pv tlb flush的场景:
kvm_flush_tlb_multi()
---
for_each_cpu(cpu, flushmask) {
src = &per_cpu(steal_time, cpu);
state = READ_ONCE(src->preempted);
if ((state & KVM_VCPU_PREEMPTED)) {
if (try_cmpxchg(&src->preempted, &state,
state | KVM_VCPU_FLUSH_TLB))
__cpumask_clear_cpu(cpu, flushmask);
}
}
native_flush_tlb_multi(flushmask, info);
---
在kvm_flush_tlb_multi()执行完的时候,被preempt的vcpu还没有执行tlb flush;这个要等到vcpu的thread被调度回来;如果,此时原来被中断的执行继续执行,可能访问到的就是老的PA;与此对应的是,对于非pv tlb flush的场景,flush_tlb_multi()会一直等待被preempt的vcpu thread被调度然后进入ipi的处理路径并执行完tlb flush。
综上,问题的症结在于没有执行完的指令;
对此,社区的处理方式是:标记出instruction boundary的场景,然后只给这种场景标记KVM_VCPU_PREEMPT,
vcpu_run()
---
vcpu->arch.at_instruction_boundary = false;
if (kvm_vcpu_running(vcpu)) {
r = vcpu_enter_guest(vcpu);
-> vmx_handle_exit_irqoff()
-> handle_external_interrupt_irqoff()
---
u32 intr_info = vmx_get_intr_info(vcpu);
unsigned int vector = intr_info & INTR_INFO_VECTOR_MASK;
gate_desc *desc = (gate_desc *)host_idt_base + vector;
...
handle_interrupt_nmi_irqoff(vcpu, gate_offset(desc));
vcpu->arch.at_instruction_boundary = true;
---
}
---
kvm_steal_time_set_preempted()
---
static const u8 preempted = KVM_VCPU_PREEMPTED;
...
if (!vcpu->arch.at_instruction_boundary) {
vcpu->stat.preemption_other++;
return;
}
vcpu->stat.preemption_reported++;
if (!copy_to_user_nofault(&st->preempted, &preempted, sizeof(preempted)))
vcpu->arch.st.preempted = KVM_VCPU_PREEMPTED;
---
只有在at_instruction_boundary时,才标记vcpu为KVM_VCPU_PREEMPTED,如此pv flush tlb才会生效;目前,只有外部中断导致的vm-exit才有at_instruction_boundary=true;这个也是符合preempt的情况的,抢占都是通过向目标CPU发送IPI实现的。
不过,这种涉及是否有点矫枉过正呢?KVM_VCPU_PREEMPTED可不光pv flush tlb在用,参考下面两个例子:
available_idle_cpu()
---
if (!idle_cpu(cpu))
return 0;
if (vcpu_is_preempted(cpu))
return 0;
return 1;
---
__mutex_lock_common()
-> mutex_optimistic_spin()
-> mutex_can_spin_on_owner()
---
if (need_resched())
return 0;
rcu_read_lock();
owner = __mutex_owner(lock);
/*
* As lock holder preemption issue, we both skip spinning if task is not
* on cpu or its cpu is preempted
*/
if (owner)
retval = owner->on_cpu && !vcpu_is_preempted(task_cpu(owner));
rcu_read_unlock();
---
-> mutex_spin_on_owner()
---
rcu_read_lock();
while (__mutex_owner(lock) == owner) {
/*
* Use vcpu_is_preempted to detect lock holder preemption issue.
*/
if (!owner->on_cpu || need_resched() ||
vcpu_is_preempted(task_cpu(owner))) {
ret = false;
break;
}
...
cpu_relax();
}
rcu_read_unlock();
---
DST.4 IRQ
有三个指标:irq_injections、nmi_injections和req_events,参考代码:
inject_pending_event()
-> vmx_inject_nmi()
---
++vcpu->stat.nmi_injections;
---
-> vmx_inject_irq()
---
++vcpu->stat.irq_injections;
---
vcpu_enter_guest()
---
if (kvm_check_request(KVM_REQ_EVENT, vcpu) || req_int_win ||
kvm_xen_has_interrupt(vcpu)) {
++vcpu->stat.req_event;
...
}
---
参考__apic_accept_irq()和vmx_delivery_posted_interrupt(),我们可以知道,在有apicv的情况下,不应该存在irq_injections,但是事实上却并非如此;

这是为什么?
参考代码:
vmx_vcpu_run()
---
if (likely(!vmx->exit_reason.failed_vmentry))
vmx->idt_vectoring_info = vmcs_read32(IDT_VECTORING_INFO_FIELD);
vmx_complete_interrupts(vmx);
-> __vmx_complete_interrupts(&vmx->vcpu, vmx->idt_vectoring_info, VM_EXIT_INSTRUCTION_LEN, IDT_VECTORING_ERROR_CODE)
---
idtv_info_valid = idt_vectoring_info & VECTORING_INFO_VALID_MASK;
...
if (!idtv_info_valid)
return;
kvm_make_request(KVM_REQ_EVENT, vcpu);
vector = idt_vectoring_info & VECTORING_INFO_VECTOR_MASK;
type = idt_vectoring_info & VECTORING_INFO_TYPE_MASK;
switch (type) {
...
case INTR_TYPE_EXT_INTR:
kvm_queue_interrupt(vcpu, vector, type == INTR_TYPE_SOFT_INTR);
break;
default:
break;
}
---
---
这里的IDT_VECTORING_INFO_FIELD,参考SDM 3 24.9.3 Information for VM Exits That Occur During Event Delivery;
Additional information is provided for VM exits that occur during event delivery in VMX non-root operation.1 This information is provided in the following fields:
这是一个vm-exit中断的event delivery;
通过kprobe也验证了这一点:
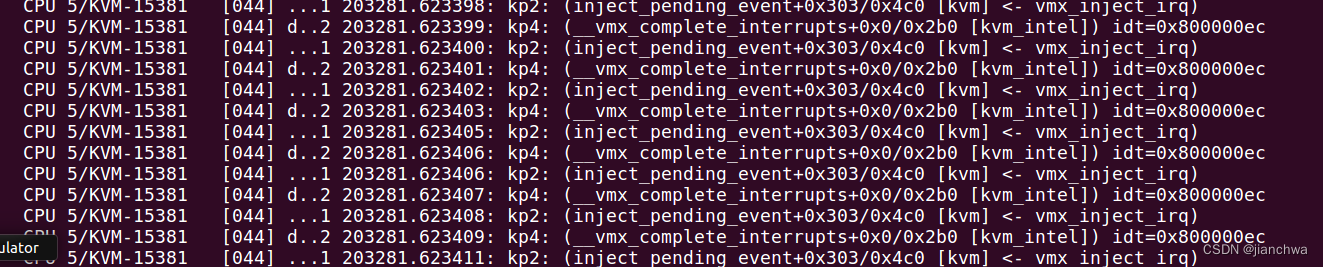
在这里,我们可以继续深入,是什么导致的vm-exit during event delivery ? 继续通过kprobe追踪:
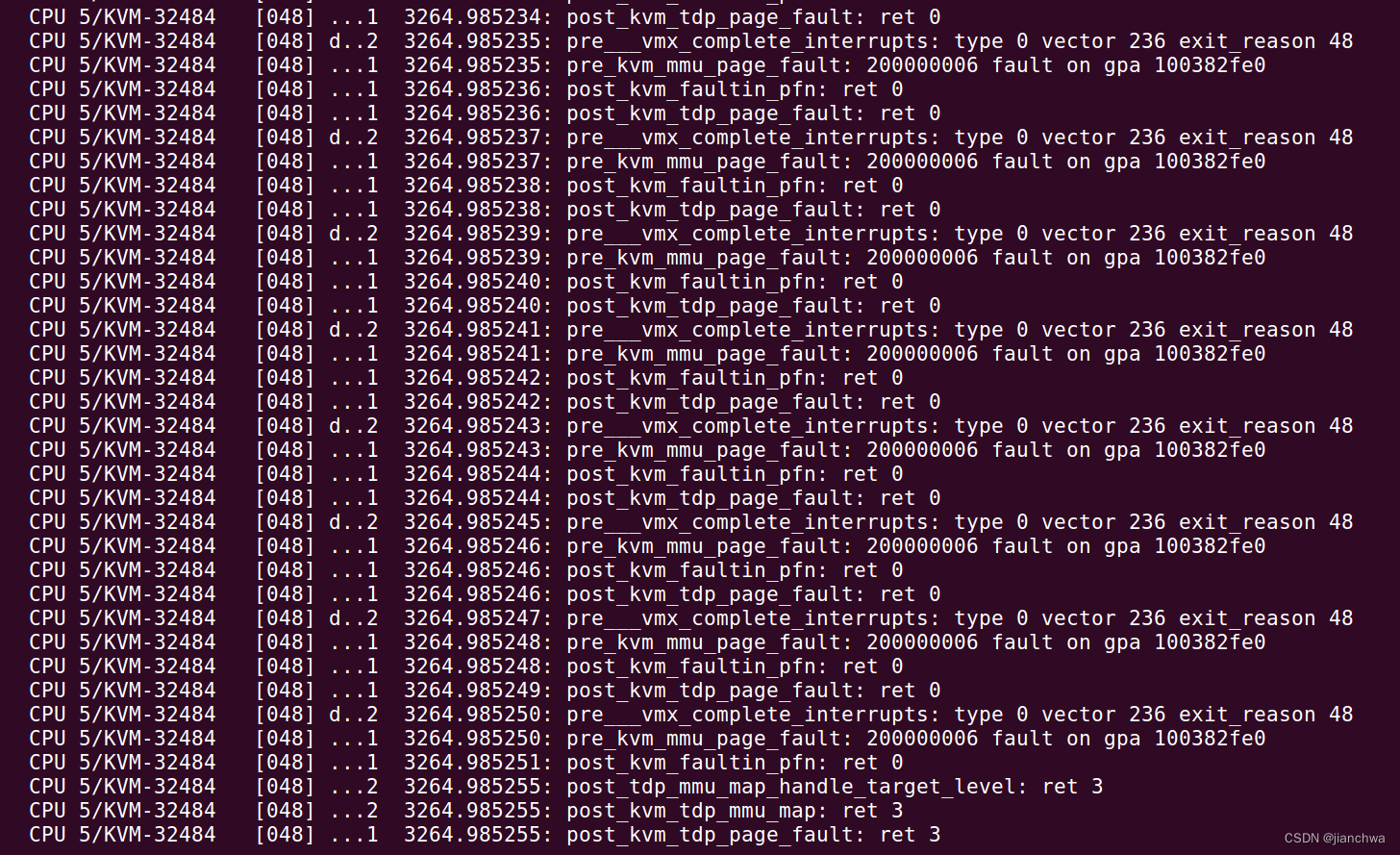
Note: 上图的被追踪的函数都是根据结果逐渐加上去的
我们首先看下是什么导致了vm-exit ?exit_reason 48是EPT Violation;为什么event delivery会导致ept violation vm-exit ? 通过链接

也就是CPU在保存被中断的任务的信息时,需要访问一段栈,那么这个栈是?
参考Intel SDM 6.12.1 Exception- or Interrupt-Handler Procedures:
When the processor performs a call to the exception- or interrupt-handler procedure:
- If the handler procedure is going to be executed at a numerically lower privilege level, a stack switch occurs. When the stack switch occurs:
- The segment selector and stack pointer for the stack to be used by the handler are obtained from the TSS for the currently executing task. On this new stack, the processor pushes the stack segment selector and stack pointer of the interrupted procedure.
- The processor then saves the current state of the EFLAGS, CS, and EIP registers on the new stack (see Figures 6-4).
- If an exception causes an error code to be saved, it is pushed on the new stack after the EIP value.
- If the handler procedure is going to be executed at the same privilege level as the interrupted procedure:
- The processor saves the current state of the EFLAGS, CS, and EIP registers on the current stack (see Figures 6-4).
- If an exception causes an error code to be saved, it is pushed on the current stack after the EIP value
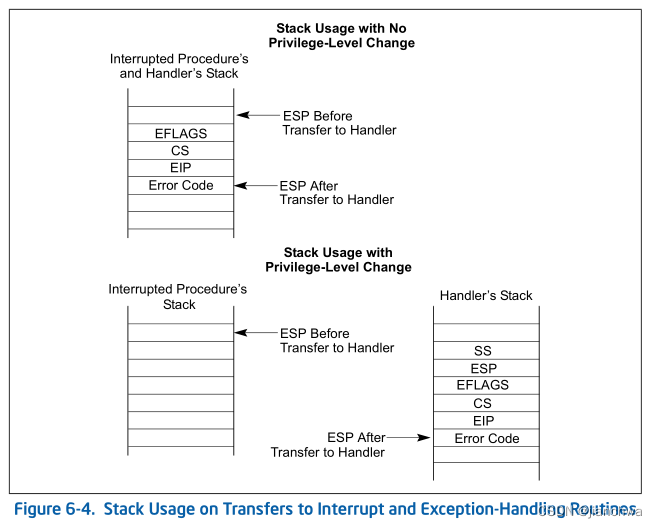
通过以上,我们得出,它应该是内核栈;任务的内核栈是per-task的,这也可以解释vm-exit during event delivery会重复发生。
注: 图中的vector 236是LOCAL_TIMER_VECTOR,参考arch/x86/include/asm/irq_vectors.h
在追踪这个vm-exit时,看到同一个gpa会重复发生多次,这是因为之前的几次都失败了,kvm_tdp_page_fault()返回值是0,RET_PF_RETRY;这个返回值会导致kvm重新进入guest,并且重复vm-exit,直到成功,如上图所示。失败的原因有多重,比如页表的更新是通过cmpxchg操作完成的,这个可能会失败;但是,这里并不是因为这个,参考上图中的追踪的结果,
kvm_tdp_page_fault()
-> direct_page_fault()
---
r = RET_PF_RETRY;
...
if (!is_noslot_pfn(pfn) && mmu_notifier_retry_hva(vcpu->kvm, mmu_seq, hva))
goto out_unlock;
...
---那么,是谁一直在更新mmu notifier ? 通过kprobe得到如下:
[ 6044.784433] CPU: 2 PID: 28822 Comm: CPU 3/KVM Kdump: loaded Tainted: G OE --------- --- 5.14.0-1.0.38.midea.x86_64 #1
[ 6044.784435] Hardware name: Inspur NF5280M5/YZMB-00882-104, BIOS 4.1.13 01/16/2020
[ 6044.784436] Call Trace:
[ 6044.784437] ? kvm_mmu_notifier_invalidate_range_start+0x1/0x2f0 [kvm]
[ 6044.784473] ? kvm_mmu_notifier_invalidate_range_start+0x5/0x2f0 [kvm]
[ 6044.784509] dump_stack_lvl+0x34/0x44
[ 6044.784512] pre_kvm_mmu_notifier_invalidate_range_start+0xf/0x2e [kvm_debug]
[ 6044.784514] pre_handler_kretprobe+0x8f/0x160
[ 6044.784517] kprobe_ftrace_handler+0x116/0x230
[ 6044.784520] 0xffffffffc0ce60c8
[ 6044.784522] ? kvm_flush_remote_tlbs+0xa0/0xa0 [kvm]
[ 6044.784558] ? kvm_mmu_notifier_invalidate_range_start+0x1/0x2f0 [kvm]
[ 6044.784594] kvm_mmu_notifier_invalidate_range_start+0x5/0x2f0 [kvm]
[ 6044.784630] mn_hlist_invalidate_range_start+0x4c/0xc0
[ 6044.784633] change_pmd_range.isra.0+0x335/0x3b0
[ 6044.784636] change_p4d_range+0x17a/0x240
[ 6044.784638] change_protection_range+0x116/0x1b0
[ 6044.784641] change_prot_numa+0x15/0x30
[ 6044.784642] task_numa_work+0x1b4/0x300
[ 6044.784646] task_work_run+0x5c/0x90
[ 6044.784648] xfer_to_guest_mode_handle_work+0xcd/0xd0
[ 6044.784649] vcpu_run+0x1e7/0x230 [kvm]
[ 6044.784693] kvm_arch_vcpu_ioctl_run+0xd9/0x610 [kvm]
[ 6044.784736] kvm_vcpu_ioctl+0x252/0x650 [kvm]
[ 6044.784771] ? __seccomp_filter+0x45/0x590
[ 6044.784774] __x64_sys_ioctl+0x82/0xb0
[ 6044.784776] do_syscall_64+0x3b/0x90
[ 6044.784779] entry_SYSCALL_64_after_hwframe+0x44/0xae
[ 6044.784781] RIP: 0033:0x7f75d289ac6btask_numa_work()是numa balance的函数,具体参考:Linux 内存管理_workingset内存_jianchwa的博客-CSDN博客详解Linux内核纷繁复杂的内存管理,未完待续https://blog.csdn.net/home19900111/article/details/123272047?spm=1001.2014.3001.5502
DST.5 Yield
这两个指标是directed_yield_attempted和directed_yield_successful;
attempted即是进入kvm_sched_yield()的次数,successful是进入后执行yield_to()成功的次数;参考代码,看下kvm_sched_yield()的调用场景:
Guest:
__pv_queued_spin_unlock_slowpath()
-> smp_store_release(&lock->locked, 0)
-> pv_kick(node->cpu)
-> kvm_kick_cpu()
---
apicid = per_cpu(x86_cpu_to_apicid, cpu);
kvm_hypercall2(KVM_HC_KICK_CPU, flags, apicid);
---
Hypervisor:
kvm_emulate_hypercall()
---
case KVM_HC_KICK_CPU:
if (!guest_pv_has(vcpu, KVM_FEATURE_PV_UNHALT))
break;
// Wake up the target cpu
kvm_pv_kick_cpu_op(vcpu->kvm, a0, a1);
kvm_sched_yield(vcpu, a1);
ret = 0;
break;
---
// Kick the vcpu if it is in block state
kvm_pv_kick_cpu_op()
-> kvm_irq_delivery_to_apic() // APIC_DM_REMRD
...
-> __apic_accept_irq()
---
case APIC_DM_REMRD:
result = 1;
vcpu->arch.pv.pv_unhalted = 1;
kvm_make_request(KVM_REQ_EVENT, vcpu);
kvm_vcpu_kick(vcpu);
break;
---
kvm_sched_yield()
-> yield_to()
---
...
yielded = curr->sched_class->yield_to_task(rq, p);
-> yield_to_task_fair()
-> set_next_buddy(se) // Set target task as next buddy of its cfs_rq
// so it can be picked up by pick_next_entity() even if it has higher vruntime
...
// yield the cpu of itself ?
if (yielded > 0)
schedule();
---
Guest:
kvm_smp_send_call_func_ipi()
---
native_send_call_func_ipi(mask);
/* Make sure other vCPUs get a chance to run if they need to. */
for_each_cpu(cpu, mask) {
if (vcpu_is_preempted(cpu)) {
kvm_hypercall1(KVM_HC_SCHED_YIELD, per_cpu(x86_cpu_to_apicid, cpu));
break;
}
}
---
Hypervisor:
kvm_emulate_hypercall()
---
case KVM_HC_SCHED_YIELD:
if (!guest_pv_has(vcpu, KVM_FEATURE_PV_SCHED_YIELD))
break;
kvm_sched_yield(vcpu, a0);
ret = 0;
break;
---
从代码上看,这个功能是为了让出本cpu,给其他任务运行;但是,这个功能明显在单核上更有效。
DBG.6 TLB Flush
先看下tlb_flush这个指标,它包含下面三个路径:
KVM_REQ_TLB_FLUSH
kvm_vcpu_flush_tlb_all()
-> vmx_flush_tlb_all()
-> ept_sync_global()
-> __invept(VMX_EPT_EXTENT_GLOBAL, 0, 0);
KVM_REQ_TLB_FLUSH_GUEST/KVM_VCPU_FLUSH_TLB
kvm_vcpu_flush_tlb_guest()
-> vmx_flush_tlb_guest()
-> vpid_sync_context((vmx_get_current_vpid(vcpu))
-> vpid_sync_vcpu_single()
-> __invvpid(VMX_VPID_EXTENT_SINGLE_CONTEXT, vpid, 0);
KVM_REQ_TLB_FLUSH_CURRENT
kvm_vcpu_flush_tlb_current()
-> ept_sync_context(construct_eptp(vcpu, root_hpa, mmu->shadow_root_level))
-> __invept(VMX_EPT_EXTENT_CONTEXT, eptp, 0)invept和invvpid有什么区别?
参看Intel SDM 3 28.3.2 Creating and Using Cached Translation Information
Guest-physical mappings may be created. They are derived from the EPT paging structures referenced (directly or indirectly) by bits 51:12 of the current EPTP. These 40 bits contain the address of the EPT-PML4- table. (the notation EP4TA refers to those 40 bits). Newly created guest-physical mappings are associated with the current EP4TA.
Combined mappings may be created. They are derived from the EPT paging structures referenced (directly or indirectly) by the current EP4TA. If CR0.PG = 1, they are also derived from the paging structures referenced (directly or indirectly) by the current value of CR3. They are associated with the current VPID, the current PCID, and the current EP4TA
GPA->HPA mapping tlb cache的标识符是EP4TA,也就是ept的指针;invept的参数中就包含ept指针,它清除的就包括带有对应的EPT4TA的GPA->HAP mapping。
GVA->HPA的mapping tlb cache标识符比较多,它包括了VPID、PCID和EP4TA;
VPID,virtual-processor identifier,参考Intel SDM 3 24.6.12 Virtual-Processor Identifier (VPID) 是vmcs中的一个16-bit的域;它与每个vcpu绑定;可参考vmx_create_vcpu() -> allocate_vpid();
PCID,process-context identifier,参考Intel SDM 4.10.1 Process-Context Identifiers (PCIDs),
Process-context identifiers (PCIDs) are a facility by which a logical processor may cache information for multiple linear-address spaces. The processor may retain cached information when software switches to a different linear-address space with a different PCID;A PCID is a 12-bit identifier. The current PCID is the value of bits 11:0 of CR3
PCID是每cpu的,从Linux内核的工作过程,可以参考函数switch_mm_irqs_off(),可以看到里面的数据结构都是per-cpu的。
由此我们可以得出:EP4TA指代的是一个VM,VPID可以指代一个vcpu,PCID则代表的是GuestOS里面的进程。
参考SDM 3 28.3.3.1 Operations that Invalidate Cached Mappings
Operations that architecturally invalidate entries in the TLBs or paging-structure caches independent of VMX operation (e.g., the INVLPG and INVPCID instructions) invalidate linear mappings and combined mappings. They are required to do so only for the current VPID (but, for combined mappings, all EP4TAs)
注:在开启ept时,kvm不会拦截invpg和invpcid
Execution of the INVEPT instruction invalidates guest-physical mappings and combined mappings. Invalidation is based on instruction operands, called the INVEPT type and the INVEPT descriptor. Two INVEPT types are currently defined:
- Single-context. If the INVEPT type is 1, the logical processor invalidates all guest-physical mappings and combined mappings associated with the EP4TA specified in the INVEPT descriptor. Combined mappings for that EP4TA are invalidated for all VPIDs and all PCIDs. (The instruction may invalidate mappings associated with other EP4TAs.)
- All-context. If the INVEPT type is 2, the logical processor invalidates guest-physical mappings and combined mappings associated with all EP4TAs (and, for combined mappings, for all VPIDs and PCIDs).
Execution of the INVVPID instruction invalidates linear mappings and combined mappings. Invalidation is based on instruction operand, called the INVVPID type and the INVVPID descriptor.
注: invvpid并不清理GPA->HPA mapping
另外两个与tlb flush有关的指标是remote_tlb_flush_requests和remote_tlb_flush;它们来自函数:
kvm_flush_remote_tlbs()
---
++kvm->stat.generic.remote_tlb_flush_requests;
if (!kvm_arch_flush_remote_tlb(kvm)
|| kvm_make_all_cpus_request(kvm, KVM_REQ_TLB_FLUSH))
++kvm->stat.generic.remote_tlb_flush;
---
要做的就是清理掉所有的ept tlb,这个操作是不是有点overkill呢?
那么,那么些操作会触发kvm_flush_remote_tlbs()呢?
参考函数__kvm_handle_hva_range()和kvm_mmu_notifier_invalidate_range_start();
DST.6 Page Count
这里有三个指标,pages_4k、pages_2m和pages_1g,它们代表的是在ept中建立mapping的page的数量;参考代码:
kvm_tdp_mmu_map()
-> tdp_mmu_map_handle_target_level()
-> tdp_mmu_set_spte_atomic()
-> tdp_mmu_set_spte_atomic_no_dirty_log()
-> __handle_changed_spte()
-> kvm_update_page_stats()
kvm给guestos供应内存是thin-provision,只有guestos访问了该段内存之后,参会在kvm申请内存建立mapping;所以,我们可能会看见,在虚拟机内的内存使用量大于这里的计数的情况。page_2m和page_1g需要在开启thp。
DST.7 Other
还有其他指标,参考下面的代码:
insn_emulation/insn_emulation_fail
x86_decode_emulated_instruction()
---
r = x86_decode_insn(ctxt, insn, insn_len, emulation_type);
++vcpu->stat.insn_emulation;
---
hypercalls
kvm_emulate_hypercall()
---
++vcpu->stat.hypercalls;
---
handle_invlpg() //EXIT_REASON_INVLPG
-> kvm_mmu_invlpg()
---
kvm_mmu_invalidate_gva(vcpu, vcpu->arch.walk_mmu, gva, INVALID_PAGE);
++vcpu->stat.invlpg;
---
pf_fixed
tdp_mmu_map_handle_target_level()
---
/*
* Increase pf_fixed in both RET_PF_EMULATE and RET_PF_FIXED to be
* consistent with legacy MMU behavior.
*/
if (ret != RET_PF_SPURIOUS)
vcpu->stat.pf_fixed++;
---
另外,指标中有个guest_mode代表的是nest模式















 1634
1634











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









