








 本文围绕决策大模型展开,介绍其是新一代人工智能底层技术,可赋能智能体和具身机器人决策。探讨从生成到决策的范式转变,分析决策模型发展出的两种范式,即基于大语言模型的LLM agent和端到端强化学习范式,最后提及两者可能在具身智能方向融合。
本文围绕决策大模型展开,介绍其是新一代人工智能底层技术,可赋能智能体和具身机器人决策。探讨从生成到决策的范式转变,分析决策模型发展出的两种范式,即基于大语言模型的LLM agent和端到端强化学习范式,最后提及两者可能在具身智能方向融合。
决策大模型:新一代人工智能的底层技术
引言
决策智能正不断发展,不应局限于以往思维。本文基于决策大模型论坛张伟楠老师的内容,深入探讨决策大模型这一新一代人工智能的底层技术。
决策大模型概述
决策大模型作为新一代人工智能的底层技术,能够赋能智能体(AI agent)在数字世界做出有效决策,也能助力具身机器人在物理世界实现有效决策。它不仅推动了智能体在复杂环境中的自主决策能力,还为多领域应用提供了新的技术思路。
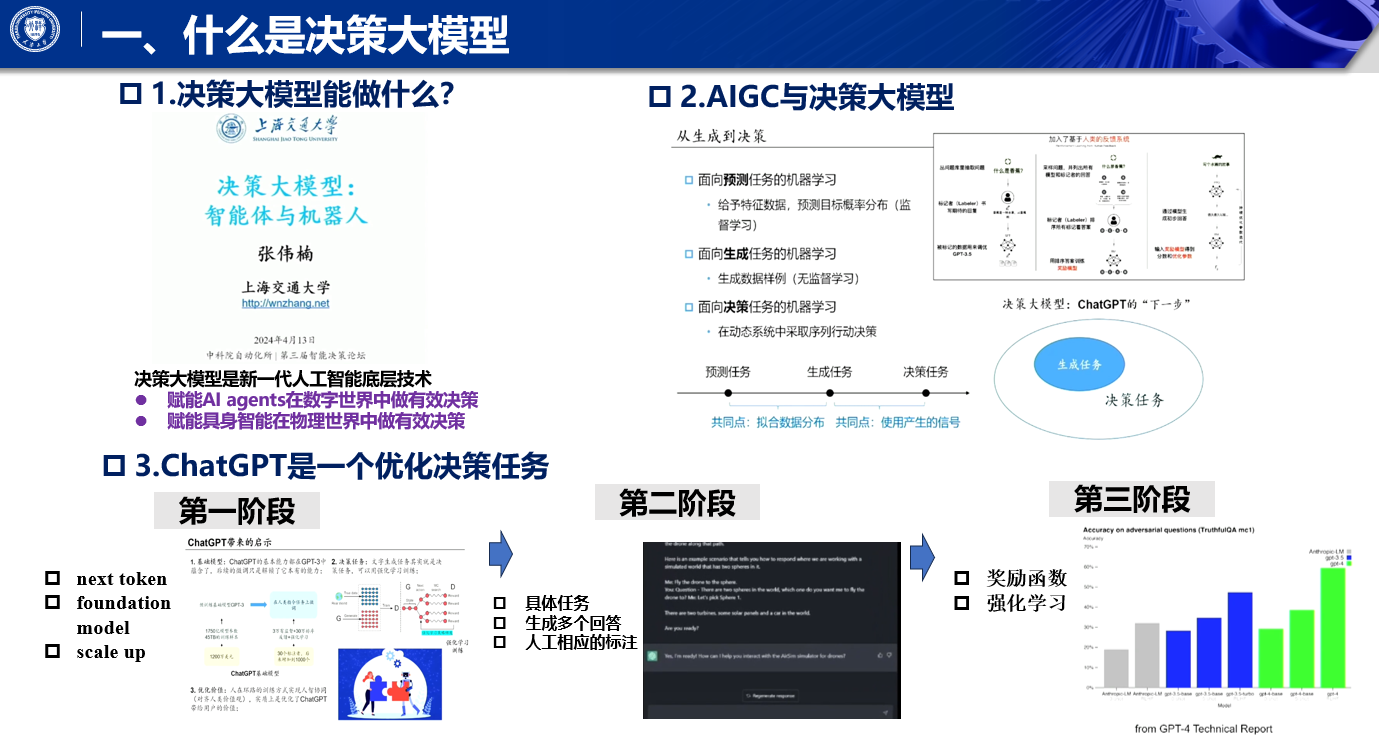
从生成到决策的范式转变
机器学习的三类问题
- 预测问题:有监督学习,面向标签预测,构建并最小化损失函数,如分类、回归等。
- 生成任务:通过构建拟合数据的最大化 log(likelihood),基于无监督学习技术,从分布中采样。
- 决策任务:在机器学习中对应强化学习工作。
三者的相似点
- 生成式任务和预测型任务:都有拟合数据分布的训练过程。
- 生成式任务和决策式任务:都能使用模型产生的数据信号。
ChatGPT 的训练阶段
- 第一阶段:通过 next TOKEN prediction 的有监督学习损失拟合基础模型,需使学习任务和架构可扩展。
- 第二阶段:模型生成多个回答,基于模型生成的数据进行人工标注,为决策优化任务做准备。
- 第三阶段:学习奖励函数后,基于奖励指引进行强化学习,实现优化决策。
智能决策技术的发展历程
- 2012 年以前:主要使用专家系统技术,需要研究者或开发者是决策智能任务的专家,将专家知识嵌入模型构建决策解决方案,广泛应用需大量人力,存在瓶颈。
- 2012 - 2013 年起:DeepMind 提出深度强化学习,智能体无需人类专家知识,直接与环境交互,利用交互数据提升性能,但在跨任务、跨场景泛化上存在困难,因使用贝尔曼最优迭代式,环境变化易传递拟合误差。
- 2022 年起:受自然语言处理启发,提出面向决策任务的大模型,认为基于 Transformer 的模型可能在多个决策任务上实现有效算法。
决策模型的两种范式
范式 A(LLM agent)
基于大语言模型构建 agent,通过 API 调用工具,与用户或系统进行标准化交互。
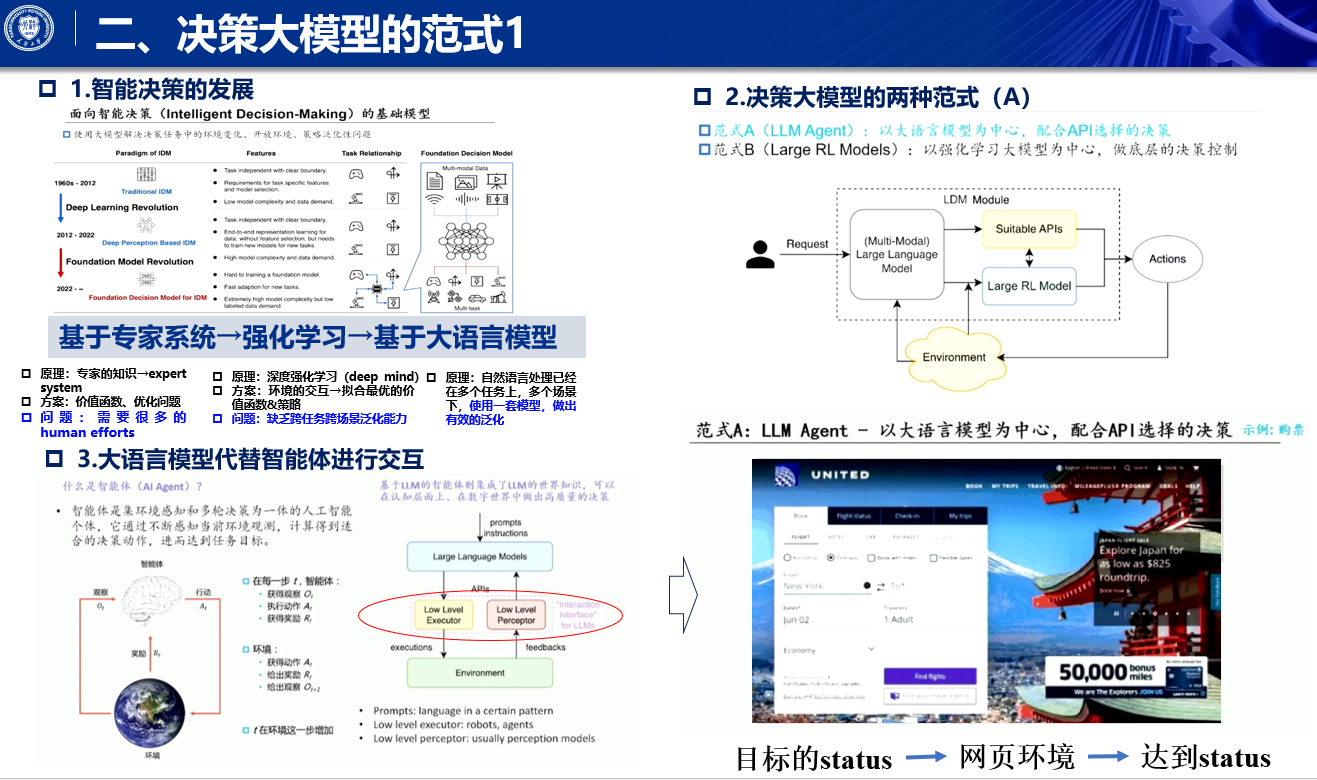
智能体的交互过程
- 智能体承载人工智能技术,与环境多轮交互,获取观测、计算决策动作、下达动作并接收反馈。
- 大语言模型替代智能体的感知和决策模块,因输入输出为语言 token,需配备 low level 的 perceptor 和 executor 以与各种环境交互。
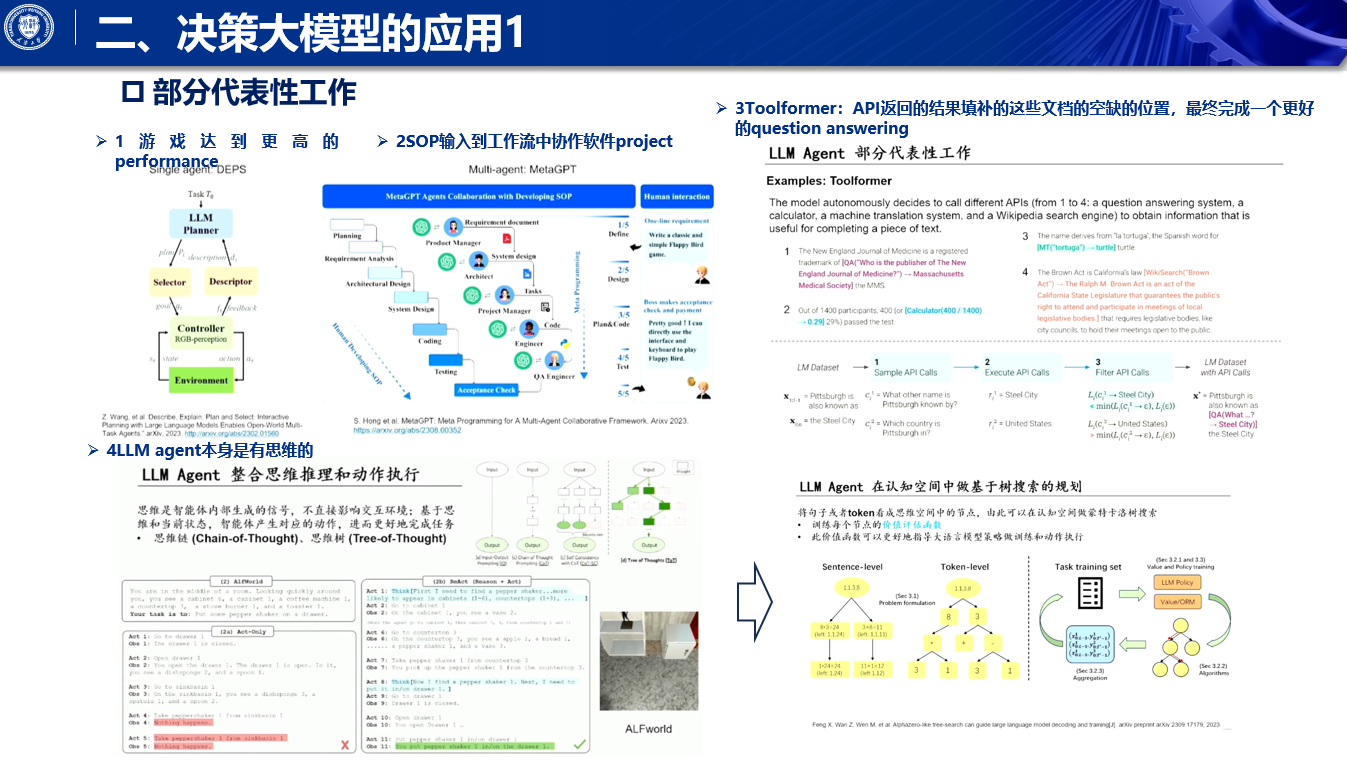
应用示例
- 个人助手:大模型可作为个人助手,如订机票、订酒店。
- 游戏交互:在游戏(如 Minecraft)中实现更高水平的表现。
- 多主体协作:如 Meta GPT,通过协作完成复杂的任务,如软件开发。
- 问答系统:如 to former,通过调用工具 API 完成更好的问答。
- 推理与决策:结合 tree of thought 结构和 MCTS 技术引导大语言模型做出更好决策。
范式 B(端到端强化学习)
端到端训练,基于强化学习框架,更改强化学习模块以实现跨任务跨环境泛化,采用 goal condition reinforcement learning 训练范式,奖励函数源自目标设计。

强化学习的大模型化
- 强化学习由策略价值等模块构成,可通过类似于 sequence modeling 中 MAXIMUM log likelihood 的训练范式,将模块改为基于 Transformer 的模块。
- 结合不同任务的专家轨迹训练通才智能体 policy,但可能无法在每个任务上都精通。
相关工作示例
- Decision Transformer:2021 年由 Berkeley 提出,用 Transformer 实现 upside down Reinforce learning 架构,以 agent 后续可取得的 return 为目标,历史 action 作为监督信号训练策略架构。
- Ghetto:2022 年提出,使用统一架构对 600 多个任务的多模态数据进行 tokenization,训练 GPT only、decoder only 的 Transformer 架构。团队在 2022 年下半年开展相关工作,积累 100T 专家轨迹数据,训练出 13.2 亿参数、能完成 870 个任务的模型,在多种任务中性能超专家策略的 76%。
- Queue Transformer:Google 提出,将多维 action 序列化,用于离线强化学习的 q learning,套上 Transformer 架构,有 3500 万参数,应用于游戏和机械臂操作。
- Transformer Dynamics model(TDM):丁曼团队在 Ghetto 提出一年后,使用类似架构构建环境模型,拟合环境后做 MPC 的 action 选择,效果优于拟合 generalist agent。
- ST Transformer:结合视觉生成信号,与 lightened action model 构建更好的动态模型,可预测环境变化,应用于游戏和机械臂动作决策。
- Marte agent transfer 架构:与徐索团队早期工作被 MIR 接受,将 agent 之间的交互沿时间延展,每一帧完成交互,可在大量离线数据上训练基础控制策略和 act,并在新任务上微调,在星际等任务上有更好的泛化能力,在允许中心化执行的 setting 下,该架构比传统架构有更强的 coordination 能力。


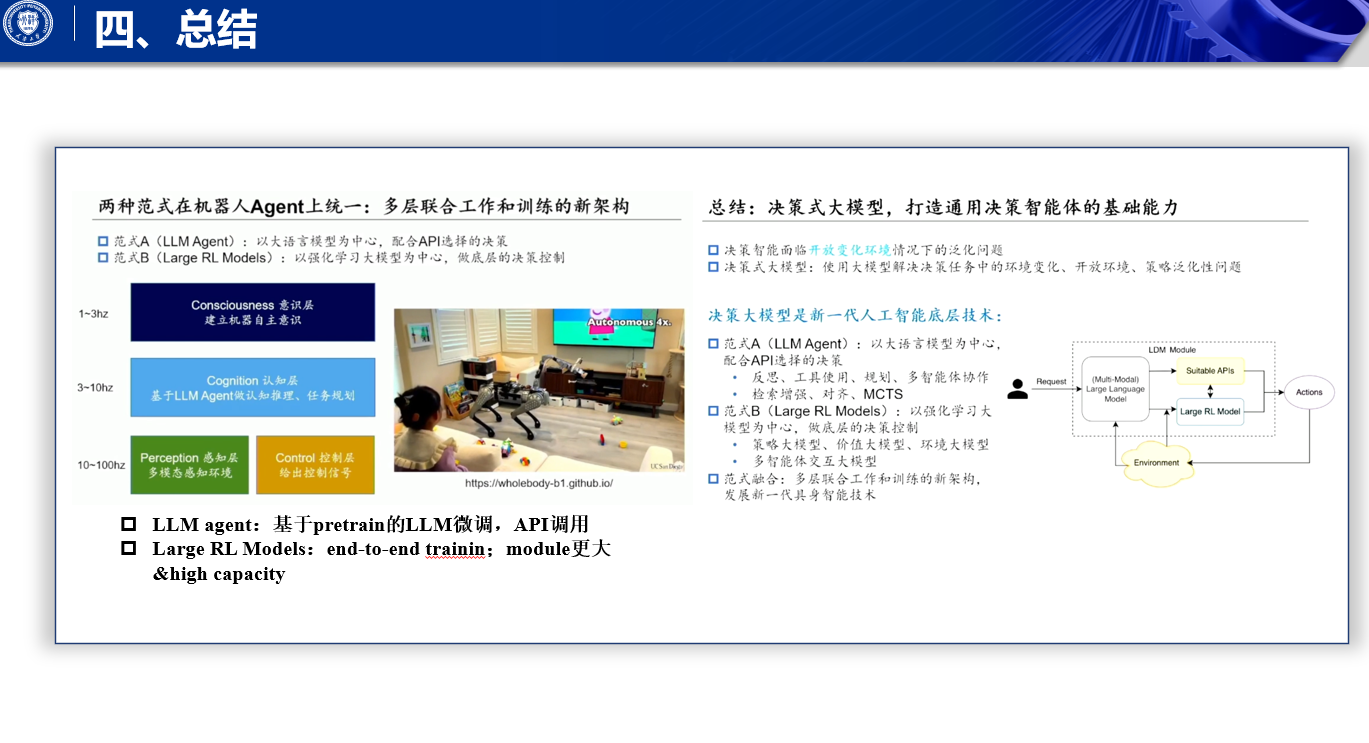
两种范式的融合展望
在聚身智能方向上,两种范式有望实现融合,提出三层架构:
- Consciousness 层:频率 1 到 3 赫兹左右,控制机器人自主意识,目前相关工作较少。
- 认知层:频率 3 到 10 赫兹左右,基于 vision language model 或纯 language model agent,对任务和状态进行评估、认知和规划。
- 感知和控制层:控制频率五十赫兹以上,用于环境感知和底层动作控制,由较小的控制模型与中层认知模型交互完成控制,架构更倾向平行执行。
在人形机器人领域,这种分层架构的体现尤为明显:
- Open AI Figure One:关注智能任务,如与人沟通、任务拆解,动作接近静态。
- Boston Dynamics 的机器人:注重灵活度,通过模拟环境深度强化学习训练 policy,再进行 SIM to real transfer 实现现实运动控制。两者智能有望快速融合。
结论
决策大模型是打造通用决策智能体的基础能力。当前的两种范式(基于大语言模型微调的范式和端到端强化学习范式)若能在智能体多层实现融合,将为智能决策开辟新的技术通路,推动决策智能的进一步发展。
希望本文能帮助你更好地理解决策大模型及其在新一代人工智能中的重要性。如果你对这一领域感兴趣,欢迎继续关注相关研究进展!


















 4169
4169

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











