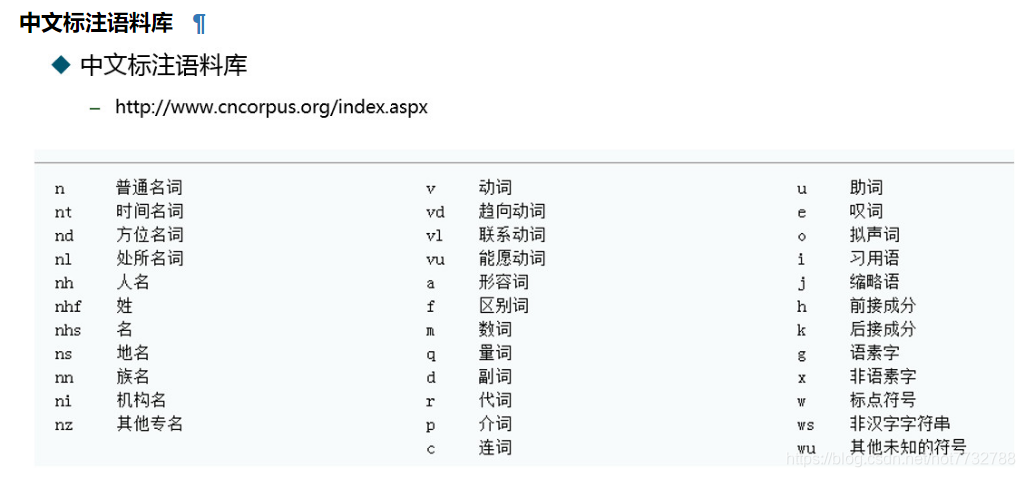
nltk词性标注词性对照

1.词性标注器
text = word_tokenize("今天 的 天气 是 真的 好 苹果")
print(pos_tag(text))
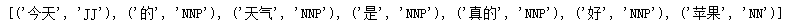
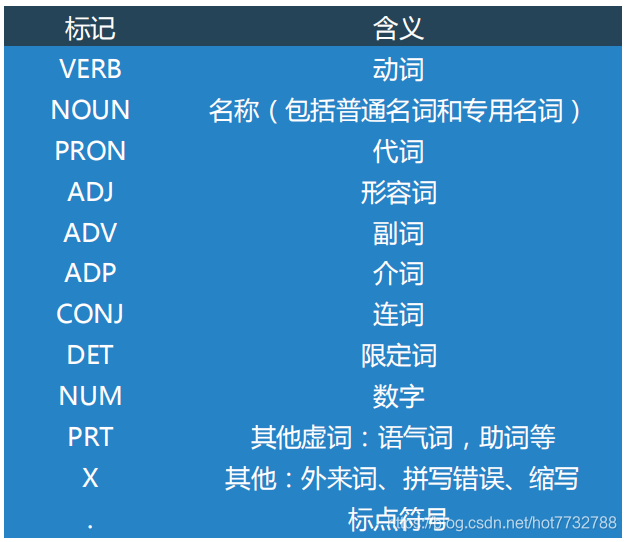
2.标注语料库
- 统一标注集合词性
tagged_token = nltk.tag.str2tuple("苹果/NN")
tagged_token
sent = '''
The/AT grand/JJ jury/NN commented/VBD on/IN a/AT number/NN of/IN
other/AP topics/NNS ,/, AMONG/IN them/PPO the/AT Atlanta/NP and/CC
Fulton/NP-tl County/NN-tl purchasing/VBG departments/NNS which/WDT it/PP
said/VBD ``/`` ARE/BER well/QL operated/VBN and/CC follow/VB generally/R
accepted/VBN practices/NNS which/WDT inure/VB to/IN the/AT best/JJT
interest/NN of/IN both/ABX governments/NNS ''/'' ./.
'''
[nltk.tag.str2tuple(t) for t in sent.split()]

print(nltk.corpus.nps_chat.tagged_words())
print(nltk.corpus.conll2000.tagged_words())
print(nltk.corpus.treebank.tagged_words())
print(nltk.corpus.brown.tagged_words(tagset='universal'))
print(nltk.corpus.nps_chat.tagged_words(tagset='universal'))
print(nltk.corpus.conll2000.tagged_words(tagset='universal'))
print(nltk.corpus.treebank.tagged_words(tagset='universal'))

from nltk.corpus import brown
brown_news_tagged = brown.tagged_words(categories='news', tagset='universal')
print(brown_news_tagged)
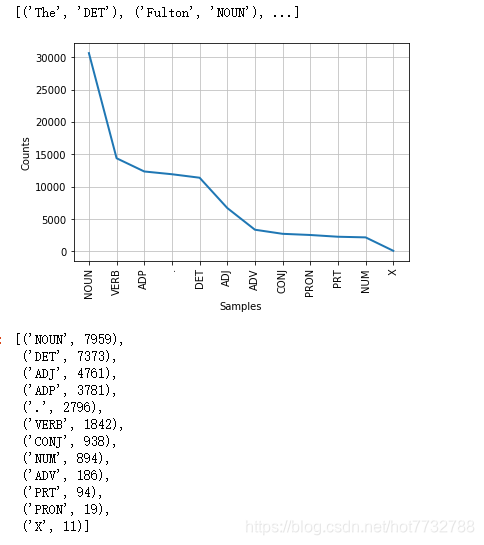
tag_fd = nltk.FreqDist(tag for (word, tag) in brown_news_tagged)
tag_fd.most_common()
tag_fd.plot()
word_tag_pairs = list(nltk.bigrams(brown_news_tagged))
nltk.FreqDist(a[1] for (a, b) in word_tag_pairs if b[1] == 'NOUN').most_common()
3.自动标注
- 默认标注器(所有词都默认标注为一种词性,这种方法不好,没什么意义,但是对于一些不知道词性新词来说可以默认标注为频数最多的词性,可以猜猜看…)
raw = '你 说 巧 不巧 正好 我 今天 也 想 去 打 篮球'
tokens = nltk.word_tokenize(raw)
default_tagger = nltk.DefaultTagger('NN')
default_tagger.tag(tokens)

- 正则表达式标注器(根据特殊后缀对单词进行词性标注)
patterns = [
(r'.*ing$', 'VBG'),
(r'.*ed$', 'VBD'),
(r'.*es$', 'VBZ'),
(r'.*ould$', 'MD'),
(r'.*\'s$', 'NN$'),
(r'.*s$', 'NNS'),
(r'^-?[0-9]+(.[0-9]+)?$', 'CD'),
(r'.*', 'NN')
]
regexp_tagger = nltk.RegexpTagger(patterns)
regexp_tagger.tag(brown.sents()[3])

fd = nltk.FreqDist(brown.words(categories='news'))
cfd = nltk.ConditionalFreqDist(brown.tagged_words(categories='news'))
most_freq_words = fd.most_common()[:100]
likely_tags = dict((word, cfd[word].max()) for (word,freq) in most_freq_words)
baseline_tagger = nltk.UnigramTagger(model=likely_tags)
baseline_tagger.evaluate(brown.tagged_sents(categories='news'))
sent = brown.sents(categories='news')[3]
baseline_tagger.tag(sent)

4.N-gram标注(基于统计算法的标注)
from nltk.corpus import brown
brown_tagged_sents = brown.tagged_sents(categories='news')
brown_sents = brown.sents(categories='news')
unigram_tagger = nltk.UnigramTagger(brown_tagged_sents)
print(unigram_tagger.tag(brown_sents[2007]))
[('Various', 'JJ'), ('of', 'IN'), ('the', 'AT'), ('apartments', 'NNS'), ('are', 'BER'), ('of', 'IN'), ('the', 'AT'), ('terrace', 'NN'), ('type', 'NN'), (',', ','), ('being', 'BEG'), ('on', 'IN'), ('the', 'AT'), ('ground', 'NN'), ('floor', 'NN'), ('so', 'QL'), ('that', 'CS'), ('entrance', 'NN'), ('is', 'BEZ'), ('direct', 'JJ'), ('.', '.')]
size = int(len(brown_tagged_sents) * 0.9)
print(size)
train_sents = brown_tagged_sents[:size]
test_sents = brown_tagged_sents[size:]
unigram_tagger = nltk.UnigramTagger(train_sents)
unigram_tagger.evaluate(test_sents)
4160
0.8121200039868434
bigram_tagger = nltk.BigramTagger(train_sents)
bigram_tagger.tag(brown_sents[2007])
unseen_sent = brown_sents[4203]
bigram_tagger.tag(unseen_sent)
bigram_tagger.evaluate(test_sents)
0.10206319146815508
t0 = nltk.DefaultTagger('NN')
t1 = nltk.UnigramTagger(train_sents, backoff=t0)
t2 = nltk.BigramTagger(train_sents, backoff=t1)
t2.evaluate(test_sents)
0.8452108043456593
5.标注器的存储与读取
from pickle import dump
output = open('t2.pkl', 'wb')
dump(t2, output, -1)
output.close()
from pickle import load
input = open('t2.pkl', 'rb')
tagger = load(input)
input.close()
text = """The board's action shows what free enterprise
is up against in our complex maze of regulatory laws ."""
tokens = text.split()
tagger.tag(tokens)









 本文深入探讨了NLTK库中的词性标注技术,包括词性标注器的使用、标注语料库的处理、自动标注的方法,以及N-gram标注器的训练与评估。通过实例演示了如何利用NLTK进行文本的词性分析,适合自然语言处理初学者及进阶者。
本文深入探讨了NLTK库中的词性标注技术,包括词性标注器的使用、标注语料库的处理、自动标注的方法,以及N-gram标注器的训练与评估。通过实例演示了如何利用NLTK进行文本的词性分析,适合自然语言处理初学者及进阶者。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









