 深度学习入门:AlexNet架构解析与PyTorch实现案例,
深度学习入门:AlexNet架构解析与PyTorch实现案例,





经典卷积神经网络-AlexNet
一、背景介绍
2012 年, 出自论文《ImageNet Classification with Deep Convolutional Neural Networks》中的AlexNet被称为是首个真正意义上的深度卷积神经网络。这个模型的名字来源于论文第一作者的姓名 Alex Krizhevsky。AlexNet 使用了 8 层卷积神经网络,并以很大的优势赢得了 ImageNet 2012 图像识别挑战赛冠军。

二、AlexNet网络结构
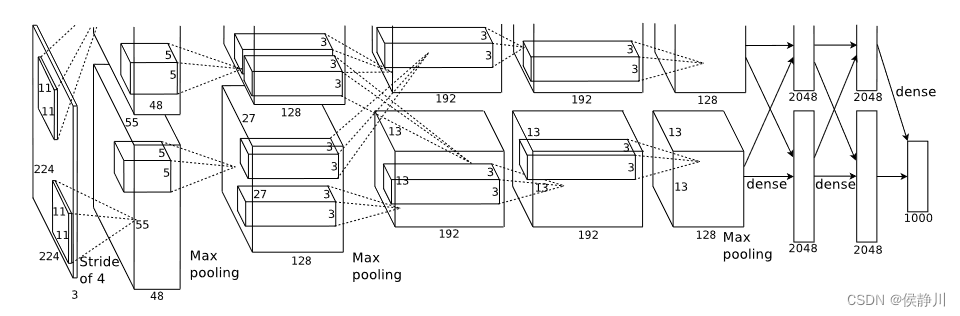
如图所示,这是论文中作者给出的AlexNet网络结构,共有八层,包含五个卷积层和三个全连接层。吴恩达深度学习视频中给出的网络结构如下:

如图所示,AlexNet与LeNet有很多相似之处,但AlexNet要大的多。AlexNet是针对ImageNet数据集来建立的,所以其最后输出(Softmax)层有1000个神经元。LeNet大约包含6万个参数,而AlexNet大约包含6000万个参数。以下是AlexNet论文中的一些细节:
- 论文中的网络结构使用的原图输入为224 × 224,实际上进行了随机裁剪,实际大小为227 × 227。
- AlexNet使用了ReLU激活函数,比传统神经网络所选取的非线性饱和函数(如sigmoid函数,tanh函数)要快许多。
- 论文中采用了非常复杂的方法在两个GPU上进行训练,大致原理是这些层被分拆到两个不同的GPUs上,同时还有一个专门的方法用于两个GPUs进行交流。
- 采用局部响应归一化(LRN),可形成某种形式的横向抑制,从而提高网络的泛华能力。随着时间的推移,LRN 在深度学习中的应用逐渐减少,因为其他正则化技术,如批量归一化(Batch Normalization)等,通常表现更好且更易于训练。
- 池化方式采用overlapping pooling,即池化窗口的大小大于步长,使得每次池化都有重叠的部分。这种重叠的池化方式比传统无重叠的池化方式有着更好的效果,且可以避免过拟合现象的发生。
- 采用Dropout操作,Dropout操作会将概率小于0.5的每个隐层神经元的输出设为0,即去掉了一些神经节点,达到防止过拟合。
三、AlexNet的Pytorch实现
后面要将AlexNet应用到猫狗二分类问题上,所以对AlexNet网络做了一些修改,其实现代码如下:
import torch
from torch import nn
from torch.nn import Sequential
class AlexNet(nn.Module):
def __init__(self):
super().__init__()
# 五个卷积层提取特征
self.features = Sequential(
# 【1】号卷积层 + ReLU + LRN + 池化
nn.Conv2d(in_channels=3, out_channels=96, kernel_size=11, stride=4, padding=2),
nn.LocalResponseNorm(size=5, alpha=0.0001, beta=0.75, k=2),
nn.MaxPool2d(kernel_size=3, stride=2),
# 【2】号卷积层 + ReLU + LRN + 池化
nn.Conv2d(in_channels=96, out_channels=256, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.LocalResponseNorm(size=5, alpha=0.0001, beta=0.75, k=2),
nn.MaxPool2d(kernel_size=3, stride=2),
# 3个卷积层+RelU + 池化
nn.Conv2d(in_channels=256, out_channels=384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=384, out_channels 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1456
1456

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











