







Instruction fine-tuning(指令微调)
Last week, you were introduced to the generative AI project lifecycle. You explored example use cases for large language models and discussed the kinds of tasks that were capable of carrying out. In this lesson, you'll learn about methods that you can use to improve the performance of an existing model for your specific use case. You'll also learn about important metrics that can be used to evaluate the performance of your finetuned LLM and quantify its improvement over the base model you started with.

Let's start by discussing how to fine tune an LLM with instruction prompts. Earlier in the course, you saw that some models are capable of identifying instructions contained in a prompt and correctly carrying out zero shot inference, while others, such as smaller LLMs, may fail to carry out the task, like the example shown here. You also saw that including one or more examples of what you want the model to do, known as one shot or few shot inference, can be enough to help the model identify the task and generate a good completion.
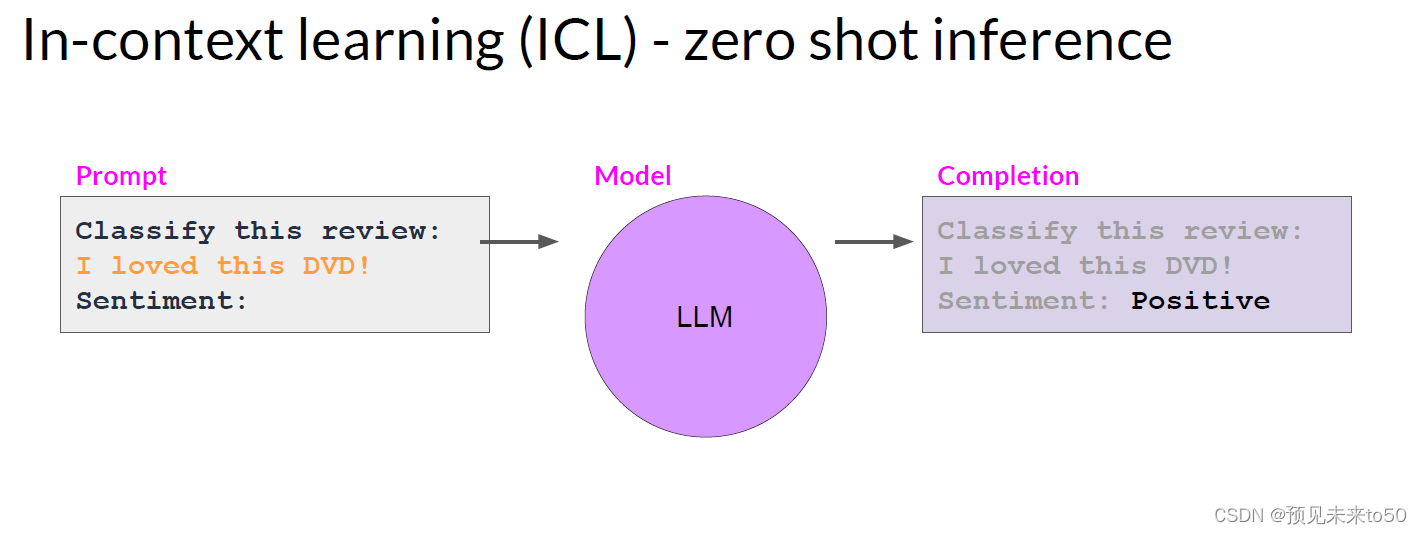
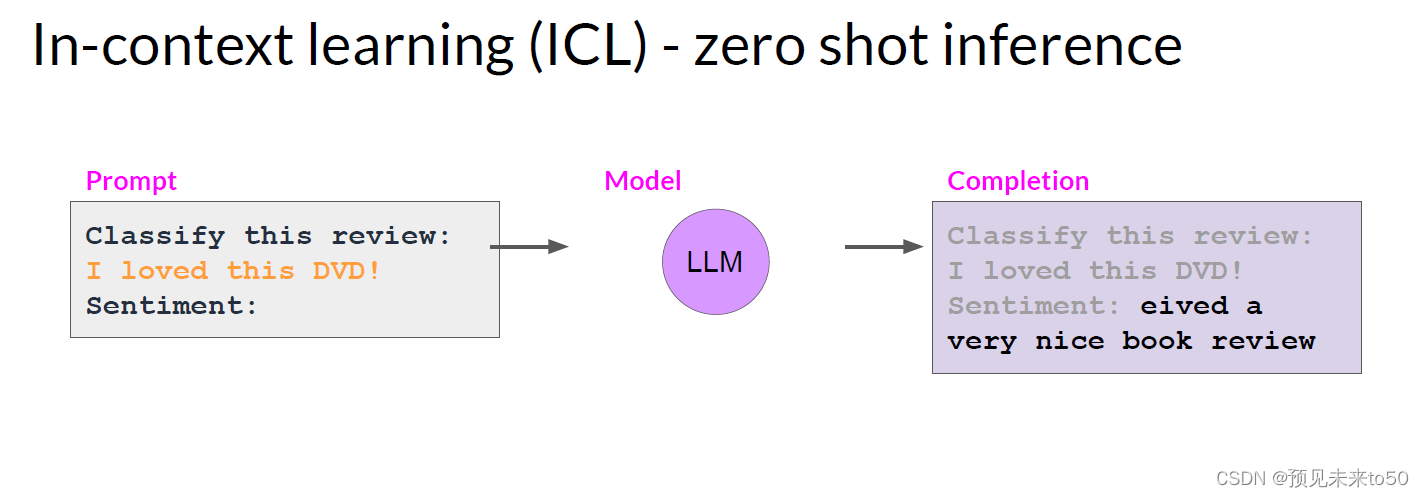
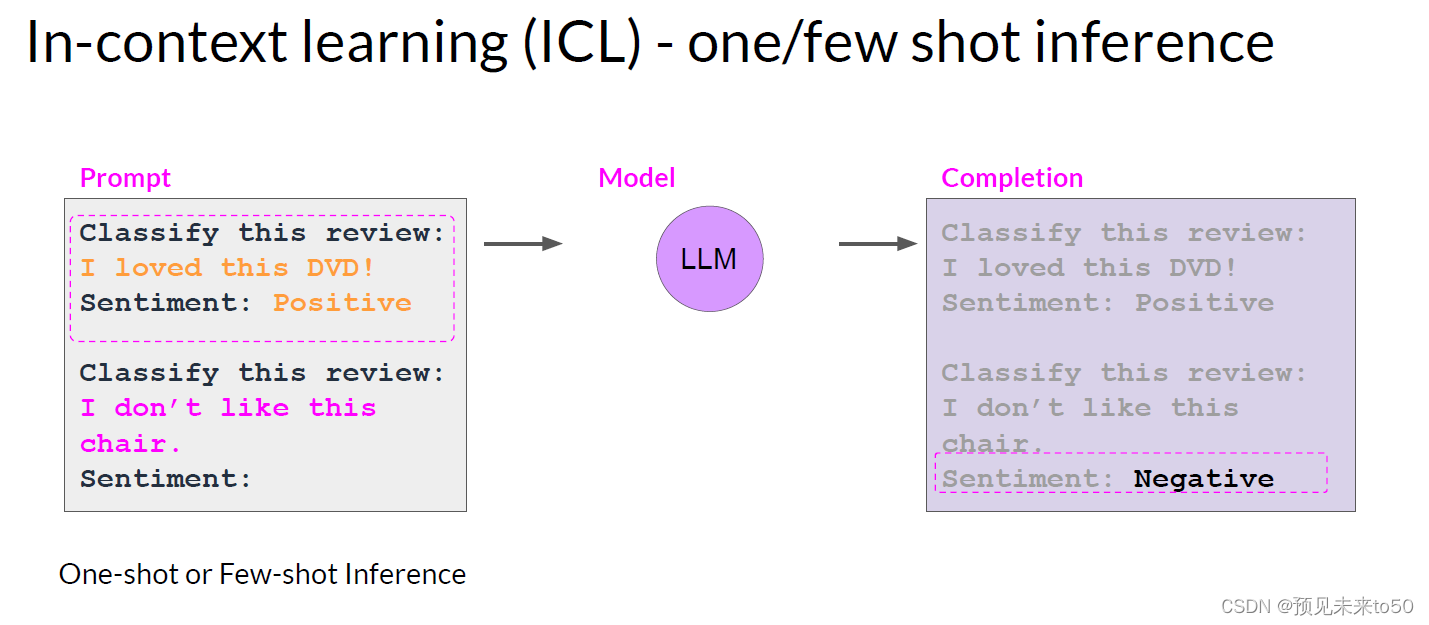
However, this strategy has a couple of drawbacks. First, for smaller models, it doesn't always work, even when five or six examples are included. Second, any examples you include in your prompt take up valuable space in the context window, reducing the amount of room you have to include other useful information.

Luckily, another solution exists, you can take advantage of a process known as fine-tuning to further train a base model. In contrast to pre-training, where you train the LLM using vast amounts of unstructured textual data via self-supervised learning, fine-tuning is a supervised learning process where you use a data set of labeled examples to update the weights of the LLM. The labeled examples are prompt completion pairs, the fine-tuning process extends the training of the model to improve its ability to generate good completions for a specific task.

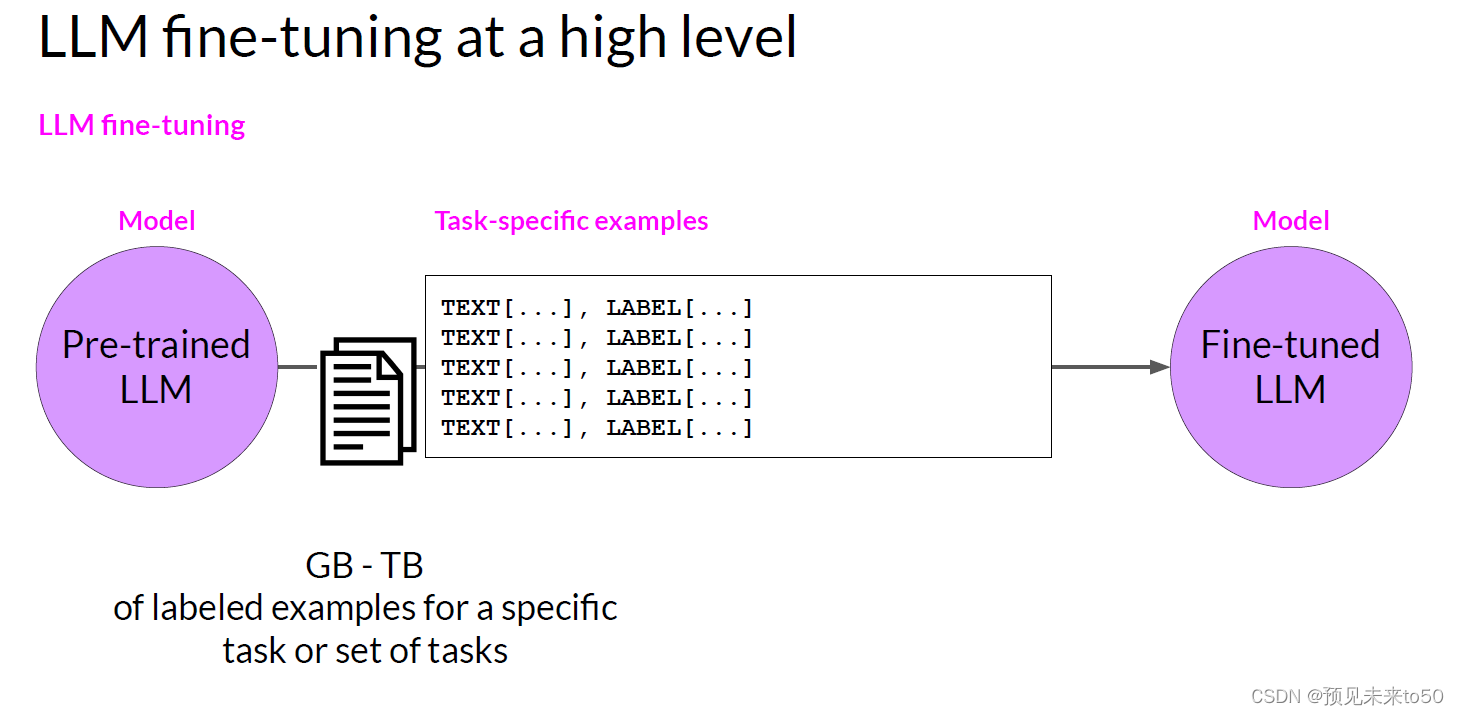
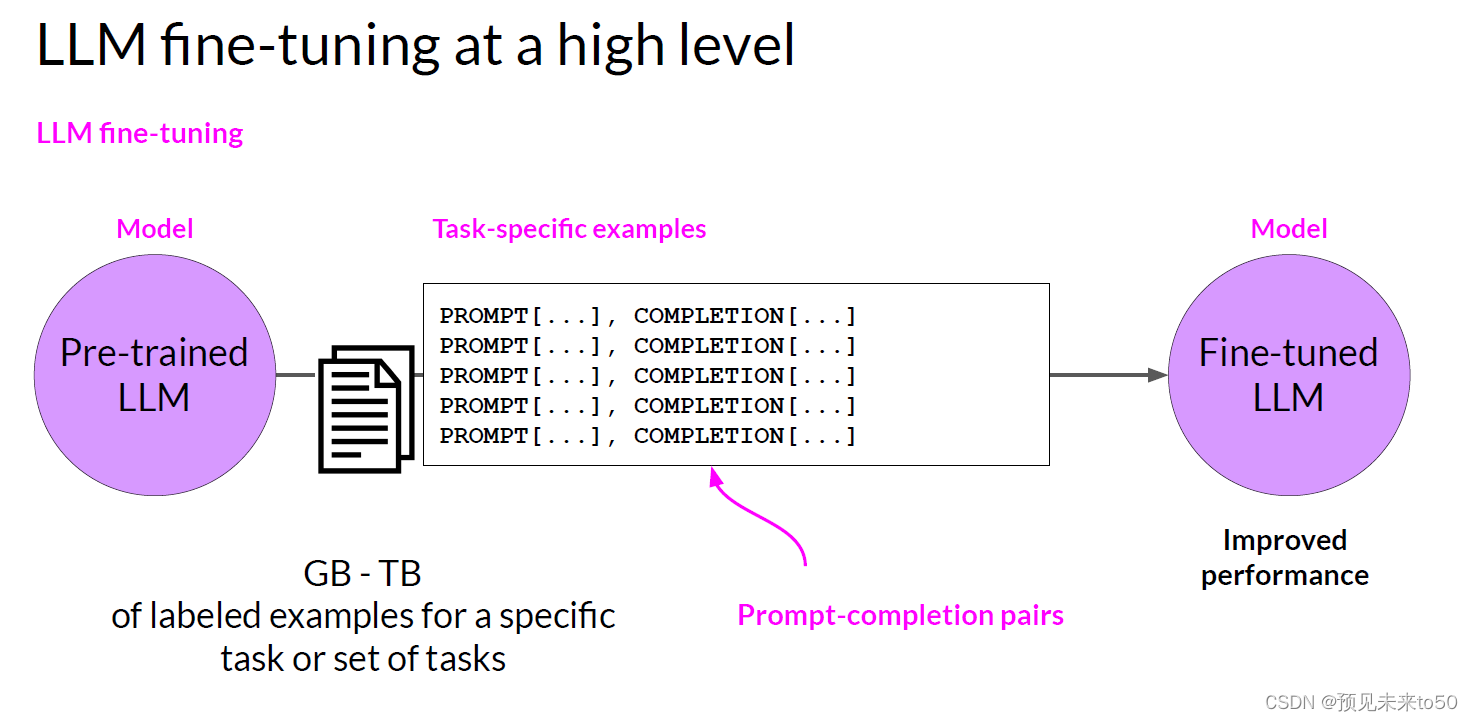
One strategy, known as instruction fine tuning, is particularly good at improving a model's performance on a variety of tasks. Let's take a closer look at how this works, instruction fine-tuning trains the model using examples that demonstrate how it should respond to a specific instruction. Here are a couple of example prompts to demonstrate this idea. The instruction in both examples is classify this review, and the desired completion is a text string that starts with sentiment followed by either positive or negative.

The data set you use for training includes many pairs of prompt completion examples for the task you're interested in, each of which includes an instruction. For example, if you want to fine tune your model to improve its summarization ability, you'd build up a data set of examples that begin with the instruction summarize, the following text or a similar phrase. And if you are improving the model's translation skills, your examples would include instructions like translate this sentence. These prompt completion examples allow the model to learn to generate responses that follow the given instructions.

Instruction fine-tuning, where all of the model's weights are updated is known as full fine-tuning. The process results in a new version of the model with updated weights. It is important to note that just like pre-training, full fine tuning requires enough memory and compute budget to store and process all the gradients, optimizers and other components that are being updated during training. So you can benefit from the memory optimization and parallel computing strategies that you learned about last week.

So how do you actually go about instruction, fine-tuning and LLM? The first step is to prepare your training data. There are many publicly available datasets that have been used to train earlier generations of language models, although most of them are not formatted as instructions. Luckily, developers have assembled prompt template libraries that can be used to take existing datasets, for example, the large data set of Amazon product reviews and turn them into instruction prompt datasets for fine-tuning. Prompt template libraries include many templates for different tasks and different data sets. Here are three prompts that are designed to work with the Amazon reviews dataset and that can be used to fine tune models for classification, text generation and text summarization tasks. You can see that in each case you pass the original review, here called review_body, to the template, where it gets inserted into the text that starts with an instruction like predict the associated rating, generate a star review, or give a short sentence describing the following product review. The result is a prompt that now contains both an instruction and the example from the data set.

Once you have your instruction data set ready, as with standard supervised learning, you divide the data set into training validation and test splits.
 During fine tuning, you select prompts from your training data set and pass them to the LLM, which then generates completions. Next, you compare the LLM completion with the response specified in the training data. You can see here that the model didn't do a great job, it classified the review as neutral, which is a bit of an understatement. The review is clearly very positive. Remember that the output of an LLM is a probability distribution across tokens. So you can compare the distribution of the completion and that of the training label and use the standard crossentropy function to calculate loss between the two token distributions. And then use the calculated loss to update your model weights in standard backpropagation.
During fine tuning, you select prompts from your training data set and pass them to the LLM, which then generates completions. Next, you compare the LLM completion with the response specified in the training data. You can see here that the model didn't do a great job, it classified the review as neutral, which is a bit of an understatement. The review is clearly very positive. Remember that the output of an LLM is a probability distribution across tokens. So you can compare the distribution of the completion and that of the training label and use the standard crossentropy function to calculate loss between the two token distributions. And then use the calculated loss to update your model weights in standard backpropagation.
 You'll do this for many batches of prompt completion pairs and over several epochs, update the weights so that the model's performance on the task improves. As in standard supervised learning, you can define separate evaluation steps to measure your LLM performance using the holdout validation data set. This will give you the validation accuracy, and after you've completed your fine tuning, you can perform a final performance evaluation using the holdout test data set. This will give you the test accuracy.
You'll do this for many batches of prompt completion pairs and over several epochs, update the weights so that the model's performance on the task improves. As in standard supervised learning, you can define separate evaluation steps to measure your LLM performance using the holdout validation data set. This will give you the validation accuracy, and after you've completed your fine tuning, you can perform a final performance evaluation using the holdout test data set. This will give you the test accuracy.


The fine-tuning process results in a new version of the base model, often called an instruct model that is better at the tasks you are interested in. Fine-tuning with instruction prompts is the most common way to fine-tune LLMs these days. From this point on, when you hear or see the term fine-tuning, you can assume that it always means instruction fine tuning.

上周,你了解了生成式AI项目生命周期。你探索了大型语言模型的示例用例,并讨论了它们能够执行的任务类型。在这一课中,你将学习可以用于改进特定用例现有模型性能的方法。你还将了解可以用来评估你的微调LLM性能并量化其比你开始的基础模型改进程度的重要指标。
让我们首先讨论如何用指令提示对LLM进行微调。在本课程的早期,你看到一些模型能够识别包含在提示中的指令并正确执行零样本推理,而其他模型,如较小的LLM,可能无法执行任务,就像这里显示的例子。你还看到,包括一个或多个你想要模型做什么的例子,被称为单样本或少样本推理,足以帮助模型识别任务并生成一个好的完成。
然而,这个策略有几个缺点。首先,对于较小的模型,即使包括五个或六个例子,它也不总是有效。其次,你在提示中包括的任何例子都占据了上下文窗口中的宝贵空间,减少了你包括其他有用信息的空间。幸运的是,另一个解决方案存在,你可以利用被称为微调的过程进一步训练基础模型。与预训练不同,在预训练中你使用大量的非结构化文本数据通过自我监督学习来训练LLM,微调是一个监督学习过程,你使用一组标记示例的数据集来更新LLM的权重。标记的示例是提示完成对,微调过程扩展了模型的训练,以提高其为特定任务生成良好完成的能力。
一种策略,被称为指令微调,特别擅长提高模型在各种任务上的性能。让我们仔细看看这是如何工作的,指令微调使用展示模型应该如何响应特定指令的示例来训练模型。这里有一些示例提示来演示这个想法。两个示例中的指令都是分类这个评论,所需的完成是以情绪开始的文本字符串,后面跟着积极或消极。你用于训练的数据集包括了许多对你感兴趣的任务的提示完成示例对,每一对都包括一个指令。例如,如果你想微调你的模型以提高其摘要能力,你会建立一个以指令摘要开始的示例数据集,后面跟着文本或类似的短语。如果你正在提高模型的翻译技能,你的示例将包括像翻译这个句子这样的指令。这些提示完成示例允许模型学会生成遵循给定指令的响应。所有模型权重都更新的指令微调被称为全微调。该过程产生了一个带有更新权重的模型新版本。需要注意的是,就像预训练一样,全微调需要足够的内存和计算预算来存储和处理在训练期间正在更新的所有梯度、优化器和其他组件。因此,你可以从上周学到的内存优化和并行计算策略中受益。
那么,你究竟如何进行指令微调以及使用LLM呢?第一步是准备你的训练数据。有许多公开可用的数据集已经被用来训练早期的语言模型,尽管它们中的大多数并不是以指令格式编排的。幸运的是,开发者们已经汇编了提示模板库,这些库可以用来获取现有的数据集,例如,亚马逊产品评论的大数据集,并将其转换为用于微调的指令提示数据集。提示模板库包括许多不同任务和不同数据集的模板。这里有三个设计用于与亚马逊评论数据集一起工作的提示,可以用来微调用于分类、文本生成和文本摘要任务的模型。你可以看到,在每种情况下,你都会将原始评论传递给模板,在这里称为review_body,它被插入到以预测相关评分、生成星级评论或给出简短句子描述以下产品评论等指令开头的文本中。结果是一个现在包含指令和数据集中示例的提示。
一旦你准备好了你的指令数据集,就像标准的监督学习一样,你将数据集划分为训练验证和测试分割。在微调过程中,你从你的训练数据集中选择提示并将它们传递给LLM,然后生成完成。接下来,你将LLM的完成与训练数据中指定的响应进行比较。你可以看到这里模型并没有做得很好,它将评论分类为中性,这有点轻描淡写。评论显然是非常积极的。记住,LLM的输出是标记上的概率分布。因此,你可以比较完成和训练标签的分布,并使用标准的交叉熵函数来计算两个标记分布之间的损失。然后使用计算出的损失通过标准反向传播更新你的模型权重。你会对许多批次的提示完成对进行这个操作,并在几个时代中更新权重,以便模型在任务上的表现得到改善。就像标准的监督学习一样,你可以定义单独的评估步骤来使用保留的验证数据集测量你的LLM性能。这将给你验证准确性,完成微调后,你可以使用保留的测试数据集进行最终性能评估。这将给你测试准确率。微调过程导致基础模型的新版本,通常称为instruct模型,它在你感兴趣的任务上表现更好。使用指令提示进行微调是当今微调LLMs的最常见方式。从现在开始,当你听到或看到术语“微调”时,你可以假设它总是意味着指令微调。














 680
680











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









