







Make Skeleton-based Action Recognition Model Smaller, Faster and Better
1,DD-NET特点
DD-Net can reach a
super fast speed, as 3,500 FPS on one GPU, or, 2,000 FPS on
one CPU。
总之就是运行速度很快,同时保证较好的精确度。可以用于边缘设备上的 姿态识别和手势识别。
输入的是3维或者2维的骨骼点数据,输出是动作分类。
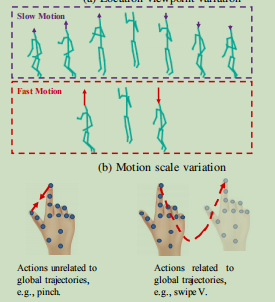
2,DD-NET的网络结构
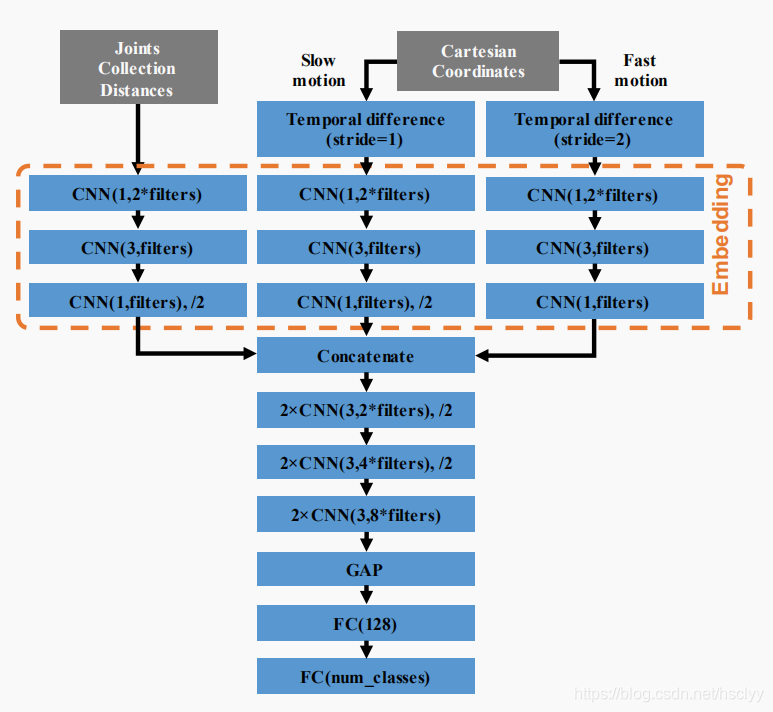
这里其实有三个输入数据流:1,每一帧图片上的骨骼点关系,这个信息用来抓取图片上的静态信息;2,3,间隔不同帧,之间的骨骼点的差分数据,可以简单地理解为类似视频中间隔不同帧的“光流”信息,这个信息用来抓取动作的时序信息。

网络结构名称解释:
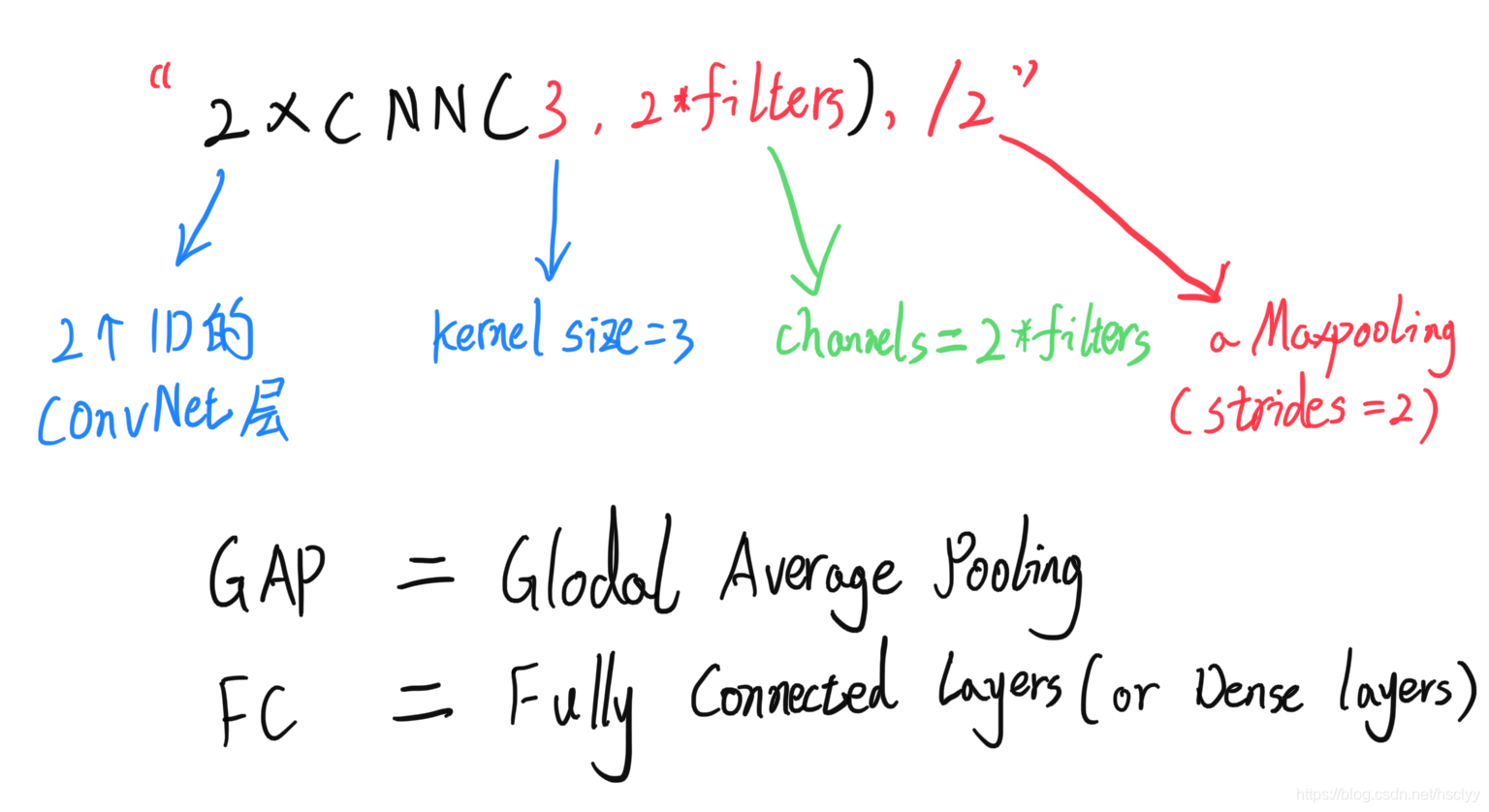
DD-NET的特点如下:
The network architecture of Double-feature Double-motion Network (DD-Net)
A:Modeling Location-viewpoint Invariant Feature by Joint Collection Distances (JCD) 基于联合集合距离的位置视点不变特征 建模
默认帧数是32帧,一个subiect 有 N 个关节
其中,在第K帧中,第i个关节(三维)的坐标是:
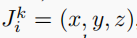
其中,在第K帧中,第i个关节(二维)的坐标是:
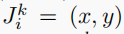
骨骼点的集合:
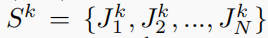
Sk的JCD特征:
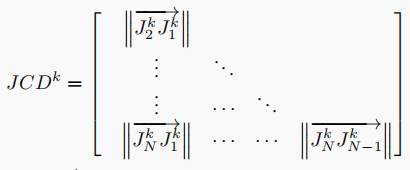
The dimension of flattened JCD is 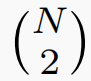
B: Modeling Global Scale-invariant Motions by a Two-scale Motion Feature 基于双尺度运动特征的全局尺度不变运动建模
This idea is inspired by the two-scale optical flows proposed for RGB-based action recognition
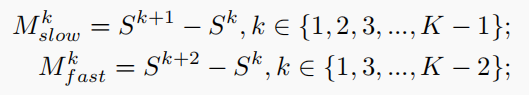
其中,Mslow和Mfast分别代表slow motion和fast motion。其实就是选用的帧与帧之间的时间间隔不同。分别是1帧和2帧。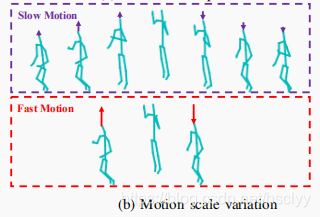
C: Modeling Joint Correlations by an Embedding 基于嵌入的关节相关性建模
分别有3个数据输入:
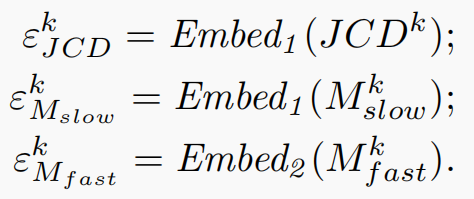
最后把这三个输出融合起来。
DD-Net futher concatenates embedding features to a representation εk by:
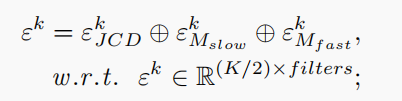

















 1269
1269

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









