








Precision和Recall
首先我们来看看下面这个混淆矩阵:
| pred_label/true_label | Positive | Negative |
|---|---|---|
| Positive | TP | FP |
| Negtive | FN | TN |
如上表所示,行表示预测的label值,列表示真实label值。TP,FP,FN,TN分别表示如下意思:
- TP(true positive):表示样本的真实类别为正,最后预测得到的结果也为正;
- FP(false positive):表示样本的真实类别为负,最后预测得到的结果却为正;
- FN(false negative):表示样本的真实类别为正,最后预测得到的结果却为负;
- TN(true negative):表示样本的真实类别为负,最后预测得到的结果也为负.
根据以上几个指标,可以分别计算出Accuracy、Precision、Recall(Sensitivity,SN),Specificity(SP)。
- Accuracy:表示预测结果的精确度,预测正确的样本数除以总样本数。
- precision,准确率,表示预测结果中,预测为正样本的样本中,正确预测为正样本的概率;
- recall,召回率,表示在原始样本的正样本中,最后被正确预测为正样本的概率;
- specificity,常常称作特异性,它研究的样本集是原始样本中的负样本,表示的是在这些负样本中最后被正确预测为负样本的概率。
在实际当中,我们往往希望得到的precision和recall都比较高,比如当FN和FP等于0的时候,他们的值都等于1。但是,它们往往在某种情况下是互斥的。例如,有50个正样本,50个负样本,结果全部预测为正样本,那么TP=50,FP=50,TN=0,FN=0,按照上面的公式计算,可以得到正样本的recall却为1,precision却为0.5.所以需要一种折衷的方式,因此就有了F1-score。
F1-score表示的是precision和recall的调和平均评估指标。
另外还有一个指标,即MCC,该指标对于不均衡数据集的评估非常有效,公式如下:
![]()
下面简单列举几种常用的推荐系统评测指标:
1、准确率与召回率(Precision & Recall)
准确率和召回率是广泛用于信息检索和统计学分类领域的两个度量值,用来评价结果的质量。其中精度是检索出相关文档数与检索出的文档总数的比率,衡量的是检索系统的查准率;召回率是指检索出的相关文档数和文档库中所有的相关文档数的比率,衡量的是检索系统的查全率。
一般来说,Precision就是检索出来的条目(比如:文档、网页等)有多少是准确的,Recall就是所有准确的条目有多少被检索出来了。
正确率、召回率和 F 值是在鱼龙混杂的环境中,选出目标的重要评价指标。不妨看看这些指标的定义先:
1. 正确率 = 提取出的正确信息条数 / 提取出的信息条数
2. 召回率 = 提取出的正确信息条数 / 样本中的信息条数
两者取值在0和1之间,数值越接近1,查准率或查全率就越高。
3. F值 = 正确率 * 召回率 * 2 / (正确率 + 召回率) (F 值即为正确率和召回率的调和平均值)
不妨举这样一个例子:某池塘有1400条鲤鱼,300只虾,300只鳖。现在以捕鲤鱼为目的。撒一大网,逮着了700条鲤鱼,200只虾,100只鳖。那么,这些指标分别如下:
正确率 = 700 / (700 + 200 + 100) = 70%
召回率 = 700 / 1400 = 50%
F值 = 70% * 50% * 2 / (70% + 50%) = 58.3%
不妨看看如果把池子里的所有的鲤鱼、虾和鳖都一网打尽,这些指标又有何变化:
正确率 = 1400 / (1400 + 300 + 300) = 70%
召回率 = 1400 / 1400 = 100%
F值 = 70% * 100% * 2 / (70% + 100%) = 82.35%
由此可见,正确率是评估捕获的成果中目标成果所占得比例;召回率,顾名思义,就是从关注领域中,召回目标类别的比例;而F值,则是综合这二者指标的评估指标,用于综合反映整体的指标。
当然希望检索结果Precision越高越好,同时Recall也越高越好,但事实上这两者在某些情况下有矛盾的。比如极端情况下,我们只搜索出了一个结果,且是准确的,那么Precision就是100%,但是Recall就很低;而如果我们把所有结果都返回,那么比如Recall是100%,但是Precision就会很低。因此在不同的场合中需要自己判断希望Precision比较高或是Recall比较高。如果是做实验研究,可以绘制Precision-Recall曲线来帮助分析。
2、综合评价指标(F-Measure)
P和R指标有时候会出现的矛盾的情况,这样就需要综合考虑他们,最常见的方法就是F-Measure(又称为F-Score)。
F-Measure是Precision和Recall加权调和平均:
当参数α=1时,就是最常见的F1,也即
可知F1综合了P和R的结果,当F1较高时则能说明试验方法比较有效。
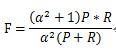
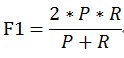
3、E值
E值表示查准率P和查全率R的加权平均值,当其中一个为0时,E值为1,其计算公式:
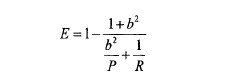
b越大,表示查准率的权重越大。
4、平均正确率(Average Precision, AP)
平均正确率表示不同查全率的点上的正确率的平均。
5、DCG
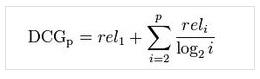
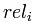 就是第 i 个结果的得分。
就是第 i 个结果的得分。
例如:假设有两个主题,主题1有4个相关网页,主题2有5个相关网页。某系统对于主题1检索出4个相关网页,其rank分别为1, 2, 4, 7;对于主题2检索出3个相关网页,其rank分别为1,3,5。对于主题1,平均准确率为(1/1+2/2+3/4+4/7)/4=0.83。对于主题2,平均准确率为(1/1+2/3+3/5+0+0)/5=0.45。则MAP= (0.83+0.45)/2=0.64。”
计算相对复杂。对于排在结位置n处的NDCG的计算公式如下图所示:

在MAP中,四个文档和query要么相关,要么不相关,也就是相关度非0即1。NDCG中改进了下,相关度分成从0到r的r+1的等级(r可设定)。当取r=5时,等级设定如下图所示:

(应该还有r=1那一级,原文档有误,不过这里不影响理解)
例如现在有一个query={abc},返回下图左列的Ranked List(URL),当假设用户的选择与排序结果无关(即每一级都等概率被选中),则生成的累计增益值如下图最右列所示:

考虑到一般情况下用户会优先点选排在前面的搜索结果,所以应该引入一个折算因子(discounting factor): log(2)/log(1+rank)。这时将获得DCG值(Discounted Cumulative Gain)如下如所示:

最后,为了使不同等级上的搜索结果的得分值容易比较,需要将DCG值归一化的到NDCG值。操作如下图所示,首先计算理想返回结果List的DCG值:

然后用DCG/MaxDCG就得到NDCG值,如下图所示:

8、MRR(Mean Reciprocal Rank):
是把标准答案在被评价系统给出结果中的排序取倒数作为它的准确度,再对所有的问题取平均。相对简单,举个例子:有3个query如下图所示:
 (黑体为返回结果中最匹配的一项)
(黑体为返回结果中最匹配的一项)

















 621
621

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









