







关于YOLOv2的个人理解
背景
首先此文是YOLOv1的进阶版,作者运用了多种不同的手段来提高模型预测的精确度,但我只会对其中核心的部分进行讲解,清楚YOLOv2与YOLOv1在整个核心算法流程上有什么不同,以及它的输入和输出分别是什么含义,怎么得到的。我认为这才是我们阅读一篇文章,具体要弄懂的东西。如有的地方解释存在纰漏,敬请指正,谢谢!
思想

核心思想与YOLOv1相同,仍然是将图片划分为S*S个grid(默认S=13),每个grid预测B个bounding box(默认B=5),但对于bounding box的生成与YOLOv1有着很大的不同,我会在后面的部分详细介绍;另外就是作者采用的一些其他的技术,虽然这些技术对模型的预测精确有着很大的提供,但我认为这并不是本文的重点,仅仅只是工程上的改变。
模型结构
这里稍微提一嘴,其实我在看目标检测论文的时候,很少会去在意它的模型结构是个什么样子,因为我们都知道深度学习它本身其实是一个黑匣子(你并不知道它的中间过程到底在学习什么),因此我们只需要知道模型的输入和输出是什么就行,以及输出为什么要设计成这个样子。
以下是整个模型结构:

观察整个模型我们可以知道输入图像的尺寸为416 * 416,输出的尺寸为13 * 13 * 125,从此刻我们可以得知模型会将整个图像的尺寸缩减为原来的1/32,那么这个尺寸的输出代表什么含义呢。首先作者按照YOLOv1的思想将图像分为S*S个grid(此处S=13),然后每一个grid预测5个bounding box,每一个bounding box包含5个box的信息(为:相对于grid中心点坐标的偏移
t
x
t_x
tx,
t
y
t_y
ty,相对于anchor宽
P
w
P_w
Pw的缩放比例
e
t
w
e^{t_w}
etw以及相对于anchor高
P
h
P_h
Ph的缩放比例
e
t
h
e^{t_h}
eth,每一个box的置信度confidence和20个类别概率),因此每一个grid需要预测125个信息(包含了5个bounding box的相关信息)。其中我们需要注意的是我们计算的中心点偏移、置信度confidence、类别概率是需要经过Sigmoid函数缩放到[0~1]的,以及宽高缩放比例需要经过e^函数。
训练阶段
相信在介绍完模型结构之后,我们已经知道了模型的输入和输出是什么。接下来我将会详细介绍文章是怎么训练模型的。首先对于YOLOv2的损失函数采用的是与YOLOv1相同的,但还是存在了一点些许的不同。总的损失函数依旧分为有目标的bounding box的中心点损失、高宽损失、以及置信度损失;无目标的bounding box的置信度损失;有目标的bounding box的类别损失。
- 有目标的bounding box的中心点损失L1
以下为L1损失的公式:
x i x_i xi:首先我们需要知道的一个点就是预测bounding box 的中心点 x i x_i xi是怎么得到的,与YOLOv1一样,都是预测bounding box相对于grid左上角的偏移 t x t_x tx(会经过Sigmoid函数归一化到[0~1])。那么通过下面的公式,再在两边同时除以13(除以13的原因是因为我们最后是在13*13的特征图上预测的),这样就可以得到归一化的 x i x_i xi。
x − i {\mathop{x}\limits^{-}}_i x−i:该变量为真实bounding box的中心点坐标(直接除以原图的宽W,约束到[0~1]),如果想要知道相对于最后的13 * 13的特征图的位置。只需要将该值乘上13即可。
同理我们可以知道 y i y_i yi和 y − i {\mathop{y}\limits^{-}}_i y−i。
1 i j o b j 1_{i j}^{obj} 1ijobj:代指含有目标的预测bounding box,此处正样本的判定规则与YOLOv1不同,因为在YOLOv2中,作者加入了anchor的思想,而bounding box的生成和anchor有着密不可分的关系(一个anchor对应着一个预测的bounding box),也就是说每一个grid包含5个anchor,具体做法是:如果真实的bounding box的中心点落在哪一个grid中,将会与该grid中的所有的anchor计算IOU(计算方式:先将他们左上角对齐,再计算IOU),然后将这5个当中拥有最大IOU的anchor对应的预测bounding box标定为正样本,即此时 1 i j o b j 1_{i j}^{obj} 1ijobj=1,否则为0。
以下是关于 y i y_i yi和 y − i {\mathop{y}\limits^{-}}_i y−i的公式:
- 有目标的bounding box的宽高损失L2
以下是该L2损失的公式:
从公式中我们发现,这与之前的YOLOv1是不一样的(在宽和高的变量上加了根号),虽然两者的公式有着些许的差别,但都是去解决在相同的中心点偏移下,由于不同的box尺寸对IOU的影响力是不同的。
w
′
w^{'}
w′:真实的bounding box的宽,已被缩放到0~1。
h
′
h^{'}
h′:真实的bounding box的高,已被缩放到0~1。
w、h:预测的bounding box的宽和高,其中w和h是通过anchor的宽高相应比例得到的,网络预测得到宽高偏移量:
e
t
w
e^{t_w}
etw和
e
t
h
e^{t_h}
eth,将其与anchor的宽高
P
w
P_w
Pw、
P
h
P_h
Ph(这已经是归一化后的值,做法就是除以原图尺寸的宽和高)相乘,最终得到归一化后的预测bounding box的w和h。
公式:
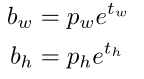
综合公式,如有不懂的,可以在下方留言。

-
有目标的bounding box的置信度损失L3
与YOLOv1相同,不同的地方还是对正样本的判定方式。其中真实的置信度,文章仍然是选择IOU的方式计算的置信度(预测bounding box与真实bounding box之间的IOU,注意并不是anchor,不要搞混了)。
公式:
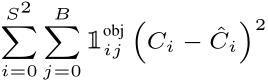
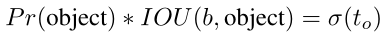
-
无目标的bounding box的置信度损失L4
与YOLOv1相同。
公式:
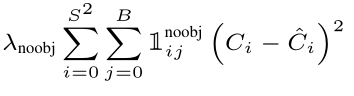
-
有目标的bounding box的类别损失L5
与YOLOv1有着些许的不同,那就是在YOLOv1中只会预测每一个grid对应的类别概率,而在YOLOv2中则会预测每一个bounding box对应的类别概率。
公式:

测试阶段
测试的整个算法流程与YOLOv1完全相同,如果感兴趣的话,可以参考我在上一篇当中对YOLOv1的讲解。此处就不再重复了。
总结
本文只介绍了论文的核心算法部分,至于文章当中运用到的其他技术这里不作详细介绍,另外如果本文在理解上存在纰漏,敬请指正,谢谢!















 3196
3196











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









