












引言:3D人体姿态与形状恢复的新视角
在3D人体姿态和形状恢复领域,传统的方法通常依赖于优化技术,通过将人体模型拟合到图像观测数据上来解决逆问题。然而,这些方法存在多个局部最小值、对初始化敏感且通常较慢的缺点。为了克服这些限制,回归方法被提出,通过训练神经网络直接从图像预测人体模型参数。但现有的前馈系统尚未能同时实现准确的3D重建和图像-模型对齐,尤其是在单目设置中。我们提出了一种新的方法,Score-Guided Human Mesh Recovery(ScoreHMR),它利用扩散模型作为学习到的先验,通过在潜在空间中的得分引导来实现与图像观测的对齐。ScoreHMR能够有效解决多种应用中的逆问题,而无需对任务不可知的扩散模型进行特定任务的重新训练。我们在单帧模型拟合、多视角重建以及视频序列中重建人类动作等三种设置/应用中评估了我们的方法。ScoreHMR在所有设置中始终优于所有优化基线。
论文标题:Score-Guided Diffusion for 3D Human Recovery
论文链接:https://arxiv.org/pdf/2403.09623.pdf
公众号【AI论文解读】后台回复“论文解读” 获取论文PDF!
ScoreHMR方法概述:从2D图像到3D重建的新途径
1. 传统方法的局限性
传统的3D人体姿态和形状恢复方法通常依赖于优化技术,通过迭代拟合人体模型到2D图像观测数据。然而,这种优化过程存在多个局部最小值,对初始化的选择敏感,并且通常速度较慢。为了避免这些缺点,回归方法训练神经网络直接从图像预测人体模型参数。但现有的前馈系统无法同时实现精确的3D重建和图像-模型对齐,尤其是在单目设置中。尽管回归和优化范式之间已经建立了协同关系,但即使在这种情况下,优化仍然具有挑战性,需要多个先验项才能获得有意义的解决方案。
2. ScoreHMR的核心思想
ScoreHMR(Score-Guided Human Mesh Recovery)是一种新颖的方法,它利用扩散模型来解决与人体网格恢复(HMR)相关的逆问题。ScoreHMR模仿模型拟合方法,但通过在扩散模型的潜在空间中的得分引导来实现与图像观测的对齐。扩散模型被训练来捕获给定输入图像的人体模型参数的条件分布。通过使用特定任务的得分来引导其去噪过程,ScoreHMR有效地解决了各种应用的逆问题,而无需对任务不可知的扩散模型进行重新训练。
ScoreHMR的工作流程:迭代精细化过程
1. 初始估计与逆向映射
ScoreHMR首先使用现有的回归网络获得每帧3D估计的初始值,然后将其通过DDIM逆向映射到扩散模型的相应潜在空间中。
2. 引导的去噪过程
在确定性DDIM采样中,引导项作为标准优化设置中的数据项,而扩散模型则作为学习到的参数化先验。通过引导项,ScoreHMR在去噪过程中注入了适当的信息,以改进基于可用观测的初始回归估计。
3. 循环迭代直至收敛
ScoreHMR通过DDIM逆向映射和引导的DDIM采样循环,直到人体模型与可用观测对齐。当引导损失的相对变化低于给定阈值时,循环停止。这种方法可以被概念化为一种数据驱动的迭代拟合方法,通过在扩散模型的潜在空间中的得分引导来实现与图像观测的对齐。
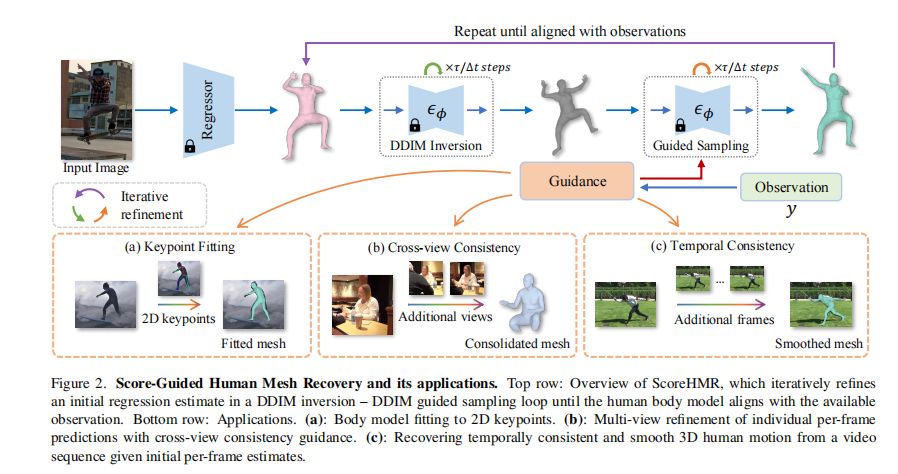
应用场景:单帧拟合、多视角和视频序列重建
1. 单帧模型拟合
单帧模型拟合是3D人体姿态和形状重建中的一个基本任务,它涉及将人体模型拟合到单个图像帧的观测数据上。在这个过程中,通常需要解决的逆问题是从图像中恢复出人体的3D姿态和形状参数。ScoreHMR通过在潜在空间中使用得分引导的方式,有效地解决了这一逆问题,而无需对任务不可知的扩散模型进行重新训练。
2. 多视角重建
多视角重建是指从多个未校准视角重建人体的3D网格。在这种场景下,ScoreHMR利用跨视图一致性引导来恢复一个在所有视点上保持一致的3D人体网格。这种方法不仅提高了重建的准确性,而且显著提高了处理速度。
3. 视频序列中的人体运动重建
在视频序列中重建人体运动涉及到从一系列图像帧中恢复出时间上连贯的人体动作。ScoreHMR通过时间一致性引导和(可选的)关键点重投影引导来细化每帧的回归估计,从而实现了时间上连贯的人体动作重建。
实验验证:评估ScoreHMR的性能
1. 数据集和评价指标
实验使用了包括Human3.6M、MPI-INF-3DHP、COCO和MPII在内的标准数据集进行训练,并在3DPW、EMDB、Human3.6M和Mannequin Challenge等数据集上进行了评估。评价指标包括平均每关节位置误差(MPJPE)、经过骨架对齐的MPJPE(PA-MPJPE)以及加速度误差(Acc Err)。
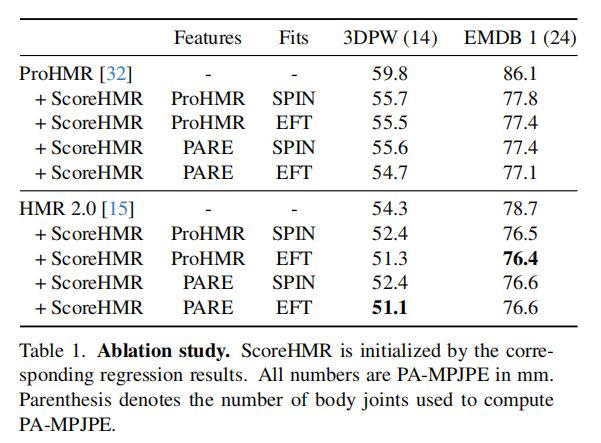
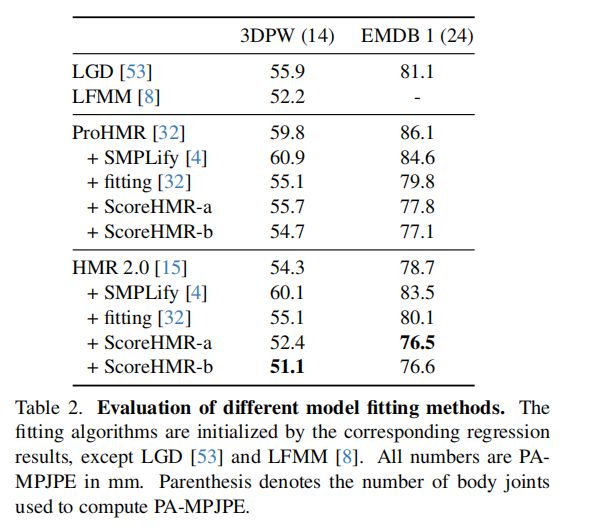
2. 定量评估与对比实验
ScoreHMR在单帧模型拟合、多视角重建和视频序列重建的各个应用场景中均展现出了优异的性能。在单帧模型拟合中,ScoreHMR在减少3D姿态误差方面表现出了对不同图像特征和伪真实姿态的鲁棒性。在多视角重建中,ScoreHMR通过跨视图一致性引导,实现了比单视图预测和基于优化的方法更低的MPJPE错误。在视频序列重建中,ScoreHMR显著提高了时间一致性,并且在处理速度上也表现出色。
3. 定性结果展示
定性结果展示了ScoreHMR在不同场景下的应用效果。在单帧模型拟合中,ScoreHMR能够有效地将人体模型与检测到的关键点对齐,即使初始回归估计不准确。在多视角重建中,ScoreHMR能够整合来自不同视角的信息,改善手部等难以观察区域的姿态估计。在视频序列重建中,ScoreHMR能够生成时间上连贯且平滑的人体动作。此外,实验还展示了ScoreHMR在处理失败案例时的表现,即使在关键点检测错误的情况下,ScoreHMR仍尝试保持3D姿态与图像证据的一致性。

讨论:ScoreHMR的优势与潜在挑战
1. 与优化方法的比较
ScoreHMR是一种用于3D人体姿态和形状重建的方法,它通过在扩散模型的潜在空间中使用得分引导来实现与图像观察的对齐。与传统的优化技术相比,ScoreHMR避免了多个局部最小值、对初始化选择的敏感性以及通常较慢的问题。此外,ScoreHMR在单帧模型拟合、多视角图像重建以及视频序列中的应用上,均一致性地超越了所有优化基线,展现出其在处理3D人体恢复逆问题方面的优势。
2. 多视角信息融合的有效性
ScoreHMR在处理多视角信息时,通过跨视图一致性引导来恢复3D人体网格,保持了所有视点的一致性。这种方法不仅改善了每个视角的单帧预测,而且由于模型捕获了SMPL姿态θ的联合分布,因此在扩散模型的下一个噪声水平上也影响了全局方向。这是传统优化方法无法实现的,因为它们在优化过程中仅更新身体姿势。
3. 视频序列中的应用潜力
ScoreHMR在视频序列中的应用展示了其在保持时间一致性和平滑预测方面的潜力。通过引导损失,ScoreHMR能够作为一个可学习的平滑操作,确保平滑的参数与图像证据在图像条件分布下保持一致。这种方法在时间一致性方面相比先前的工作有显著提升,例如在3DPW和EMDB 1数据集上,相对于ProHMR-fitting,加速度误差分别提高了21.3%和40.5%。
总结与未来工作展望
1. ScoreHMR在3D人体恢复中的地位
ScoreHMR通过在扩散模型的潜在空间中使用得分引导来实现与图像观察的对齐,有效地解决了3D人体恢复的逆问题。它在各种基准测试和评估设置中表现出色,特别是在具有挑战性的数据集中,其性能超越了基于优化的方法。ScoreHMR的成功突显了得分引导扩散过程作为解决3D人体恢复逆问题的一种比传统基于优化的方法更好的替代方案的潜力。
2. 潜在的改进方向和应用前景
未来的工作可以探索将ScoreHMR应用于更广泛的3D人体恢复场景,例如复杂的动作和多人互动环境。此外,改进方向可能包括优化扩散模型的训练过程,以更好地捕获人体姿态和形状的多样性,以及提高模型对遮挡和异常姿势的鲁棒性。随着计算能力的提升和算法的进一步发展,ScoreHMR有望在虚拟现实、增强现实、游戏和电影产业中找到广泛的应用。




















 322
322

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











