







作者:einyboy or alert
俗话说:“物以类聚,人以群分”,在自然科学和社会科学中,存在着大量的分类问题。所谓类,通俗地说,就是指相似元素的集合。
为了进一步理解什么叫做聚类,请看一面的例子:
1. 地球人分三种,白种,黄种,黑种人,这是从肤色上分类的,这里的肤色是一种特征,一个人出现在你面前,他胸前没挂着自己是什么种人你也可以分别出来,也就是能自主分类。
2. 一个班的学生我们计算他的各科和的平均分,按平均分可以分为不及格,及格,良,优秀4个等级,这里的等级就是分类数目。这些分类结果也是由平均分这一本质特征来决定的,并不是说谁优秀谁就优秀的。
3. 试试想想在不知道中国老虎分为几类的情况下,你是怎么分类的。首先把所有老虎都抓起来慢慢研究,找出老虎特征间的本质不周再进行分类。而聚类就是能达到这种效果的方法。
4. 先看看下图:
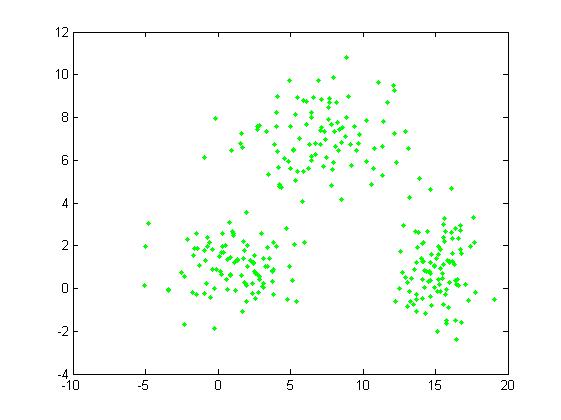
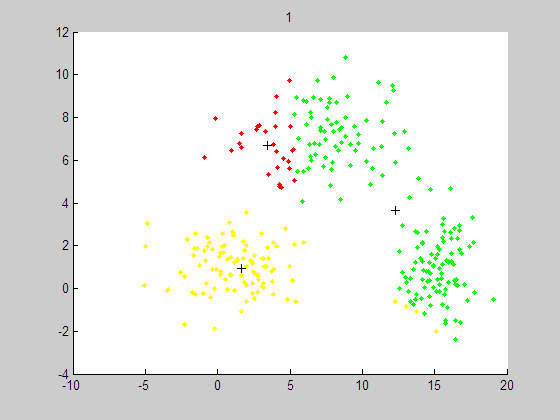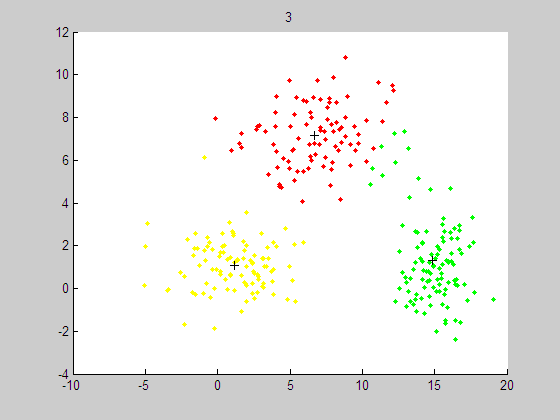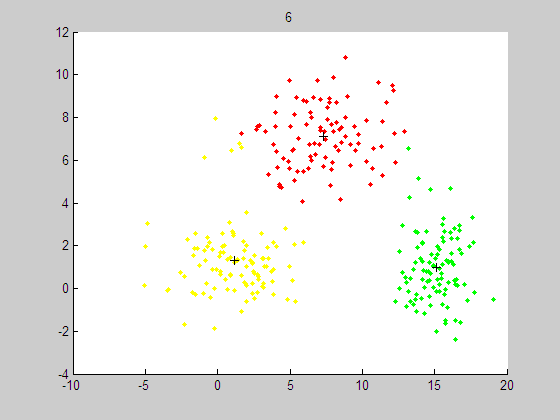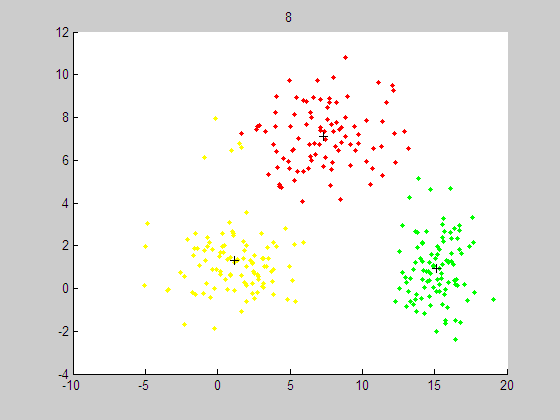
上图的点似乎围绕着3个中心点的,也就是3类的聚类中心。每个数据点只有2维坐标特征,并没有表明是属于哪一个类的特征。在分类问题中,如果要进行对已知分类的数据进行训练,这种方法叫监督学习。而聚类算法是在没有知道分类情况下的学习方式,这叫做非监督学习。
本文介绍一种k-mean聚类算法,这里的k就是分类的数目。
k-mean聚类算法如下:
1. 从数据点中,随机选取k个数据中心作为初始的聚类中心。例如k=3,则选择3个数据点
2. 分别计算每一个点到k个中心点的距离(本文计算的是欧式距离),如果当前计算的数据点离第i个(i=1,2,…,k)中心点最近,则把当前点归到第i类.
3. 重新计算k个聚类中心点。计算方式如下,如果第i类有n个数据点,则第i类新的中心为:

4.如果新的聚类中心跟上一次的聚类中心比较变化小于某值算法结束,否则转到第二步。
聚类结果如下:
代码如下:http://download.csdn.net/source/3374443
load gaussdata; %由于我先前生成好了,直接load进来
maxiter = 50; %设定最大频数
iter = 1;
num = size(X,2); %num为数据点个数
index = randperm(num); %产生1到num个数字的一个随机排列
center = X(:,index(1:3)); %选择出3个初始的聚类中心
%center = X(:,1:3);
old = center; %记录旧的聚类中心
hold on ;
plot(X(1,:),X(2,:),'g.'); %绘制数据点
plot(center(1,:),center(2,:),'ro'); %绘制数据中心
title(num2str(iter)); %显示迭代步数
hold off;
xnum = size(X,2);
cdim = size(center,2);
while iter<=maxiter
clf;
hold on;
%35-39行计算每一个点到k个中心的距离,一个很神奇的技巧,自己想吧,呵呵
sumX = sum(X.^2,1);
sumC = sum(center.^2,1);
XY = (2*X'*center)';
distance = repmat(sumX,cdim,1)+repmat(sumC',1,xnum)-XY;
[v,idx] = min(distance,[],1); %求出数据点到哪一个中心的距离最近
Y = idx; %对数据点进行分类
idx1 = find(idx==1);
idx2 = find(idx==2);
idx3 = find(idx==3);
%下面三行计算出新的聚类中心
center(:,1) = mean(X(:,idx1),2);
center(:,2) = mean(X(:,idx2),2);
center(:,3) = mean(X(:,idx3),2);
title(num2str(iter));
plot_data(X,Y,center);
hold off;
pause(0.1);
error = sum((center(:,1)-old(:,1)).^2,1); %计算迭代中止条件
if error<0.000001
break;
end
old = center;
iter = iter+1;
end
















 667
667

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











