









前言:
FISTA(A fast iterative shrinkage-thresholding algorithm)是一种快速的迭代阈值收缩算法(ISTA)。FISTA和ISTA都是基于梯度下降的思想,在迭代过程中进行了更为聪明(smarter)的选择,从而达到更快的迭代速度。理论证明:FISTA和ISTA的迭代收敛速度分别为O(1/k2)和O(1/k)。
本篇博文先从解决优化问题的传统方法“梯度下降”开始,然后引入ISTA,再上升为FISTA,最后在到其应用(主要在图像的去模糊方面和特征匹配)。文章主要参考资料如下:
[1] A Fast Iterative Shrinkage-Thresholding Algorithm for Linear Inverse Problems。
[2] Proximal Gradient Descent for L1 Regularization
-------------------------------------------------------------------------------------------------------------------------------------------------------
--------------------------------------------------------我是分割线--------------------------------------------------------
1.梯度下降法
考虑以下线性转换问题:b = Ax + w (1)
例如在图像模糊问题中,A为模糊模板(由未模糊图像通过转换而来),b为模糊图像,w为噪声。并且,A和b已知,x为待求的系数。
求解该问题的的传统方法为最小二乘法,思想很简单粗暴:使得重构误差||Ax-b||2最小。即:
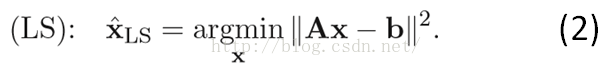
对f(x) = ||Ax-b||2求导,可得其导数为:f'(x) = 2AT(Ax-b)。对于该问题,令导数为零即可以取得最小值(函数f(x)为凸函数,其极小值即为最小值)。
1)如果A为非奇异矩阵,即A可逆的话,那么可得该问题的精确解为x=A-1b。
2)如果A为奇异矩阵,即A不可逆,则该问题没有精确解。退而求其次,我们求一个近似解就好,||Ax-b||2<=ϵ。
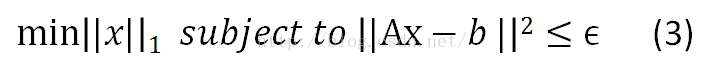
其中,||x||_1为惩罚项,用以规范化参数x。该例子使用L1范数作为惩罚项,是希望x尽量稀疏(非零元素个数尽可能少),即b是A的一个稀疏表示。||Ax-b||2<=ϵ则为约束条件,即重构误差最小。问题(3)也可以描述为:
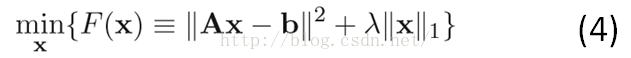
式子(4)即为一般稀疏表示的优化问题。希望重构误差尽可能小,同时参数的个数尽可能少。
注:惩罚项也可以是L2或其他范数。
1.1 梯度下降法的缺陷
考虑更为一般的情况,我们来讨论梯度下降法。有无约束的优化问题如下:
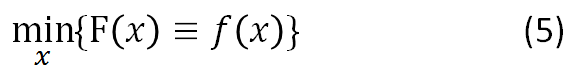
梯度下降法基于这样的观察:如果实值函数F(x)在点a处可微且有定义,那么函数F(x)在点a沿着梯度相反的方向-∇F(a)下降最快。
基于此,我们假设f(x)连续可微(continuously differentiable)。如果存在一个足够小的数值t>0使得x2 = x1 - t∇F(a),那么:
F(x1) >= F(x2)
梯度下降法的核心就是通过式子(6)找到序列{xk},使得F(xk) >= F(xk-1)。
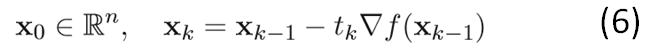
下图详细说明了梯度下降的过程:
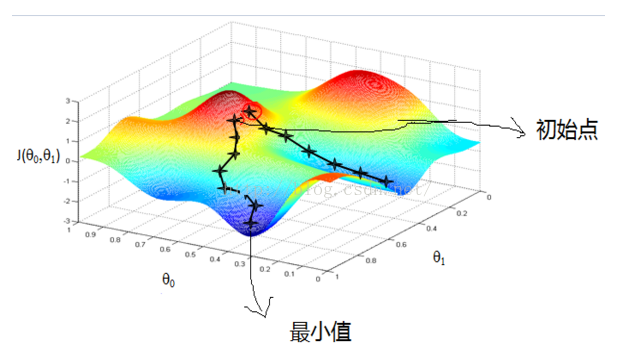
从上图可以看出:初始点不同,获得的最小值也不同。因为梯度下降法求解的是局部最小值,受初值的影响较大。如果函数f(x)为凸函数的话,则局部最小值亦为全局最小值。这时,初始点只对迭代速度有影响。
再回头看一下式子(6),我们使用步长tk和导数∇F(xk)来控制每一次迭代时x的变化量。再看一下上面那张图,彩色缤纷那张。对于每一次迭代,我们当然希望F(x)的值降得越快越好,这样我们就能更快速得获得函数的最小值。因此,步长tk的选择很重要。
如果步长tk太小,则找到最小值的迭代次数非常多,即迭代速度非常慢,或者说迭代的收敛速度很慢;而步长太大的话,则会出现overshoot the minimum的现象,即不断在最小值左右徘徊,跳来跳去的,如下图所示:
然而,tk最后还是作用在xk-1上,得到xk。因此,更为朴素的思想应该是:序列{xk}的个数尽可能小,即每一次迭代步伐尽可能大,函数值减少得尽可能多。那么就是关于序列{xk}的选择了,如何更好的选择每一个点xk,使得函数值更快的趋近其最小值。
-----------------------------------------------------------------------------------------------------------------------------------------------------
----------------------------------------------------------我是分割线--------------------------------------------------------
ISTA和FISTA求解最小化问题的思想就是基于梯度下降法的,它们的优化在于对{xk}的选择上。这里我们不讲证明,只讲思想。想看证明的话,请看参考资料[1]。
2.ISTA算法
ISTA(Iterative shrinkage-thresholding algorithm),即迭代阈值收缩算法。
先从无约束的优化问题开始,即上面的式子(5):
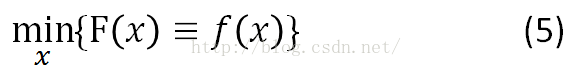
这时候,我们还假设了f(x)满足Lipschitz连续条件,即f(x)的导数有下界,其最小下界称为Lipschitz常数L(f)。这时,对于任意的L>=L(f),有:
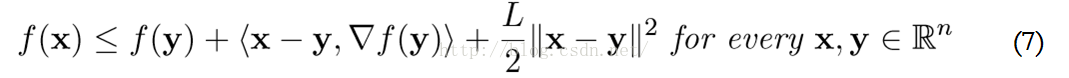
基于此,在点xk附近可以把函数值近似为:
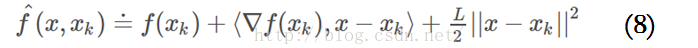
在梯度下降的每一步迭代中,将点xk-1处的近似函数取得最小值的点作为下一次迭代的起始点xk,这就是所谓的proximal regularization算法(其中,tk=1/L)。
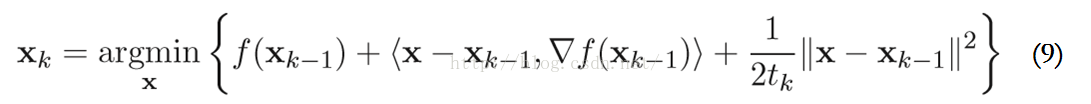
上面的方法只适合解决非约束问题。而ISTA要解决的可是带惩罚项的优化问题,引入范数规范化函数g(x)对参数x进行约束,如下:
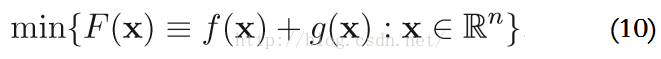
使用更为一般的二次近似模型来求解上述的优化问题,在点y,F(x) := f(x) + g(x)的二次近似函数为:
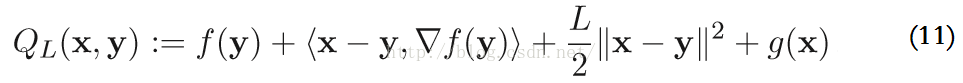
该函数的最小值表示为,P_L是proximal(近端算子)的简写形式:
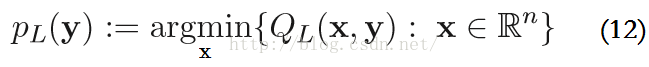
忽略其常数项f(y)和∇F(y),这些有和没有对结果没有影响。再结合式子(11)和(12),PL(y)可以写成:
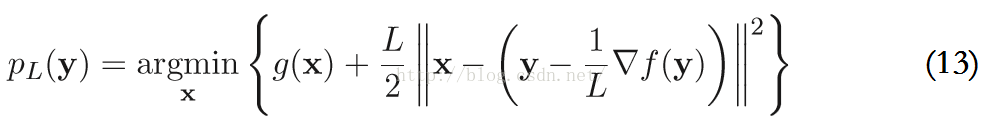
显然,使用ISTA解决带约束的优化问题时的基本迭代步骤为:
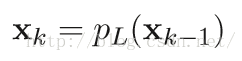
固定步长的ISTA的基本迭代步骤如下(步长t = 1/L(f)):

然而,固定步长的ISTA的缺点是:Lipschitz常数L(f)不一定可知或者可计算。例如,L1范数约束的优化问题,其Lipschitz常数依赖于ATA的最大特征值。而对于大规模的问题,非常难计算。因此,使用以下带回溯(backtracking)的ISTA:

理论证明:ISTA的收敛速度为O(1/k);而FISTA的收敛速度为O(1/k2)。实际应用中,FISTA亦明显快于ISTA。其证明过程还是看这篇文章:[1]。
3.FISTA
FISTA(A fast iterative shrinkage-thresholding algorithm)是一种快速的迭代阈值收缩算法(ISTA)。
FISTA与ISTA的区别在于迭代步骤中近似函数起始点y的选择。ISTA使用前一次迭代求得的近似函数最小值点xk-1,而FISTA则使用另一种方法来计算y的位置。理论证明,其收敛速度能够达到O(1/k2)。固定步长的FISTA的基本迭代步骤如下:

当然,考虑到与ISTA同样的问题:问题规模大的时候,决定步长的Lipschitz常数计算复杂。FISTA与ISTA一样,亦有其回溯算法。在这个问题上,FISTA与ISTA并没有区别,上面也说了,FISTA与ISTA的区别仅仅在于每一步迭代时近似函数起始点的选择。更加简明的说:FISTA用一种更为聪明的办法选择序列{xk},使得其基于梯度下降思想的迭代过程更加快速地趋近问题函数F(x)的最小值。
带回溯的FISTA算法基本迭代步骤如下:

值得注意的是,在每一步迭代中,计算近似函数的起止点时,FISTA使用前两次迭代过程的结果xk-1,xk-1,对其进行简单的线性组合生成下一次迭代的近似函数起始点yk。方法很简单,但效果却非常好。当然,这也是有理论支持的。
-----------------------------------------------------------------------------------------------------------------------------------------------------
----------------------------------------------------------我是分割线--------------------------------------------------------
4.ISTA&FISTA的应用(去模糊)
LASSO是一个图像处理中经典的目标方程
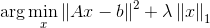
第二项的1范数限制了x的稀疏性,前文已说过,在此不再叙述。

比如在图像去模糊的问题中,已知模糊的图像b,和模糊函数R,我们想恢复去模糊的图像I。这些变量的关系可以表达成I*R=b,其中*为卷积。在理想状态下,b没有任何噪音,那么这个问题就很简单。基于卷积定理,两个函数在时域的卷积相当于频域的相乘,那么我们只需要求出b和R的傅里叶变换,然后相除得到I的傅里叶变换,再将其恢复到时域。但是一般来说模糊图像b含有噪声,这使得频域中的操作异常不稳定,所以更多时候,我们希望通过以下方程求得I
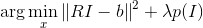
其中模糊算子R表现成矩阵形式,I和b表示为1维向量,函数p作为规范项。我们将I小波分解,I=Wx,其中W为小波基,x为小波基系数。我们知道图像的小波表示是稀疏的,那么目标方程就变成了LASSO的形式
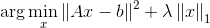
其中A=RW。现在的问题是,这个方程由于L1范数的存在,不是处处可微的,如果用subgradient的方法,收敛的速度会很慢。
4.1 LASSO问题用ISTA求解
因此我们用ISTA(Iterative Shrinkage-Thresholding Algorithm)。这个算法可以解决以上f+g形式的最小化问题,但ISTA适用于以下形式问题的求解:
1.目标方程是f+g的形式
2.f和g是凸的,f是可导的,g无所谓
3.g需要足够简单(可拆分的,可以做坐标下降的coordinate descent)
于是,我们首先看对f做一般的递归下降。我们可以参照(13)式,便可以得到:
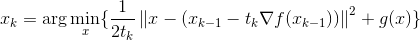
这时我们可以看到,假如g是一个开拆分的函数(比如L1范数),我们就可以对每一维分别进行坐标下降,也就是将N维的最小值问题,转化成N个1D的最小值问题。我们发现,如果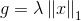
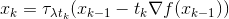
其中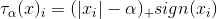
4.2 LASSO问题用FISTA求解
FISTA其实就是对ISTA应用Nestrerov加速。一个普通的Nestrerov加速递归下降的迭代步骤是:
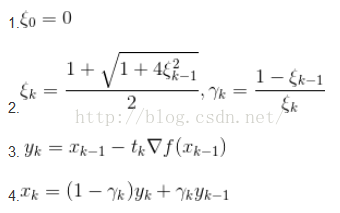
应用到FISTA上的话,就是把第3步换成ISTA的迭代步骤。可以证明FISTA可以达到1/(t^2)的收敛速度。(t是迭代次数)通过下面的实验可以看到,同样迭代了300次,左图(ISTA)仍未收敛,图像仍然模糊。而右图(FISTA)已经基本还原了去模糊的原图。


-----------------------------------------------------------------------------------------------------------------------------------------------------
----------------------------------------------------------我是分割线--------------------------------------------------------
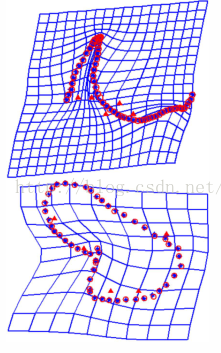
5.ISTA&FISTA的应用(特征匹配)
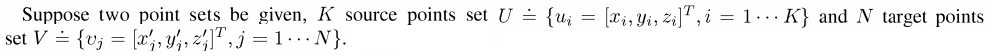
f is the transformation function between U and V. Then we can see that:

through the above function. We can get:
=========================
参考自:
1、Junhao_wu: http://www.cnblogs.com/JunhaoWu/p/Fista.html
2、Beyond Algorithm is Math : http://blog.csdn.net/iverson_49/article/details/38354961
转载请注明:Pual-Huang+地址

















 1637
1637

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









