







 本文提出了一种名为异步交互聚合网络(AIA)的新方法,用于视频中的动作检测。AIA通过集成人-人、人-物和时间交互,提高了动作检测的准确性。关键创新包括交互聚合结构(IA)和异步记忆更新(AMU)算法,后者解决了长时间交互建模的计算挑战。在AVA、UCF101-24和EPIC-Kitchens数据集上的实验表明,AIA在性能上显著优于现有方法,验证了其在动作检测任务中的有效性。
本文提出了一种名为异步交互聚合网络(AIA)的新方法,用于视频中的动作检测。AIA通过集成人-人、人-物和时间交互,提高了动作检测的准确性。关键创新包括交互聚合结构(IA)和异步记忆更新(AMU)算法,后者解决了长时间交互建模的计算挑战。在AVA、UCF101-24和EPIC-Kitchens数据集上的实验表明,AIA在性能上显著优于现有方法,验证了其在动作检测任务中的有效性。
参考文献:https://arxiv.org/abs/2004.07485v1
代码实现:https://github.com/MVIG-SJTU/AlphAction
Asynchronous Interaction Aggregation for Action Detection
摘要
理解交互是视频动作检测的重要组成部分。我们提出了异步交互聚合网络(AIA),它利用不同的交互促进动作检测。其中有两个关键设计:一是交互聚合结构(IA),采用统一的范式对多种交互类型进行建模和集成;另一种是异步记忆更新算法(AMU),它使我们能够通过动态建模非常长时间的交互来获得更好的性能,而不需要巨大的计算成本。我们提供的经验数据表明,我们的网络能够从综合交互中获得更显著的准确性,并且易于端到端的训练。我们的方法在AVA数据集上报告了最新的最新性能,与我们强大的baseline相比,验证集的mAP增益为3.7(相对改进12.6%),在UCF101-24和EPIC-Kitchens数据集上的结果进一步说明了我们的方法的有效性。
1 引言
动作检测(时空动作定位)的任务是检测和识别空间和时间上的动作,作为视频理解的一项重要任务,它具有异常行为检测、自动驾驶等多种应用。除了空间特征和时间特征[19,25,3,9],相互作用关系[12,37,45,27]对于理解动作至关重要。以图1为例。男人、茶杯以及女人之前的动作有助于预测女人的动作。在本文中,我们提出了一个新的架构,强调动作检测的互动性。
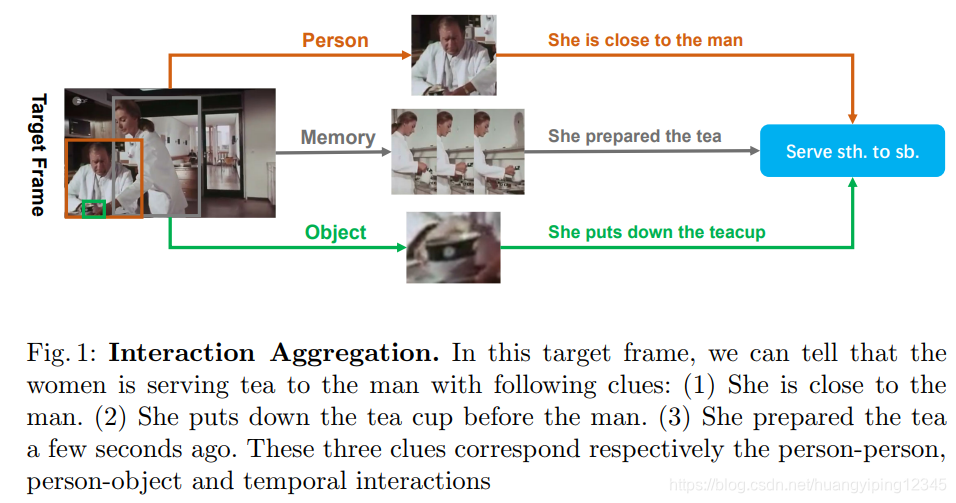
互动可以简单地看作是目标人和语义之间的关系。现有的许多研究都试图探索视频中的交互,但目前的研究方法存在两个问题:(1)以往的研究方法[12,14]只关注单一类型的交互(如人-物体),它们只能促进一种特定的行为。文献[44]试图合并不同的交互,但它们是分别建模的,一个交互的信息对另一个交互建模没有贡献,如何在视频中找到正确的交互并将其用于动作检测仍然是一个挑战。(2) 长期的时间交互作用很重要,但很难追踪。由于资源挑战,使用时间卷积的方法[19,25,9]接收时间非常有限,像文献[39]把复制的提取特征作为预处理,在现实中是不实际的。
在这项工作中,我们提出了一个新的框架,即异步交互聚合网络(AIA),它探索了三种交互(人-人、人-物和时间交互),几乎涵盖了视频中所有类型的人-语义交互。作为第一次尝试,AIA使它们在层次结构中协同工作,以捕获更高层次的时空特征和更精确的注意。我们的网络主要有两种设计:交互聚合(IA)结构和异步记忆更新(AMU)算法。
对于交互聚合(IA)结构的设计,探索并整合了所有三种类型的交互在一个深层结构中。更具体地说,它由多个元素的交互块组成,每个元素交互块通过一种交互类型增强目标特征。这三种类型的交互块沿着IA结构的深度嵌套,一个块可以使用先前交互块的结果。因此,IA结构能够使用不同类型的信息精确地对交互进行建模。
由于视频数据量大,联合训练具有长记忆特性是不可行的,因此提出了AMU算法来估计训练过程中的难处理特征。我们采用类记忆结构来存储空间特征,并提出了一系列的写-读算法来更新内存中的内容:每次迭代时从目标片段中提取的特征被写入记忆池,然后在后续迭代中进行检索,从而对时间交互进行建模。这种有效的策略使我们能够端到端地训练整个网络,并且计算复杂度不会随着时间记忆特征长度的增加而线性增加。与先前预先提取特征的解决方案[39]相比,AMU简单得多,并且获得更好的性能。
综上所述,我们的主要贡献是:(1)一个深度IA结构,它集成了多种人-语义交互以实现鲁棒的动作检测;(2)一个动态估计记忆特征的AMU算法。我们在AVA[16]数据集上对时空动作定位任务进行了广泛的消融研究,提出的方法在性能上显示了巨大的提升,这在验证和测试集上都产生了最新的结果。我们也在数据集UCF101-24和片段级动作识别数据集EPIC Kitchens上测试了我们的方法,进一步验证了方法的通用性。
2 相关工作
视频分类(动作分类)。各种3D CNN[19,32,31,34]已经被开发用来处理视频输入。为了使用巨大的图像数据集,I3D[3]在ImageNet[6]预训练基础上获益。在文献[25,7,33,42,4]中,上述模型中的3D核通过时间滤波器和空间滤波器来模拟,这两种滤波器可以显著减小模型的尺寸。SlowFast网络[9]引入了双流方法[28,10]。
时空动作检测。动作检测比动作分类更为困难,因为模型不仅需要预测动作标签,还需要在时间和空间上对动作进行定位。最新的方法[16,11,9,17,40]遵循目标检测框架[13,26],对检测到的边界框生成的特征进行分类。与我们的方法相比,它们的结果只依赖于裁剪的特征,而所有其他的信息都被丢弃,对最终的预测毫无贡献。
视频的注意机制。transformer[35]由几个堆叠的自注意层和全连接层组成。Non-Local[36]提出的结论是,先前的自注意模型可以看作是non-local均值的经典计算机视觉方法的一种形式[2],因此引入了一般的non-local块[36]。这种结构使得模型能够通过在不同的时间或空间关联特征来计算响应,从而使注意力机制适用于动作分类等与视频相关的任务。non-local块在文献[39]中也扮演着重要的角色,通过non-local特征库操作符引用来自长期特征库的信息。
3 提出的方法
在本节中,我们将描述在空间和时间中定位动作的方法。我们的方法旨在对各种交互进行建模和聚合,以获得更好的动作检测性能。在第3.1节中,我们描述了两种重要的实例级特性:短片段和长视频中的记忆特征。在第3.2节中,探讨了交互聚集结构(IA)以聚集交互知识。在第3.3节中,我们介绍了异步记忆更新算法(AMU),以缓解时间交互建模中计算量大和内存消耗大的问题。我们的方法的总体流程如图2所示。
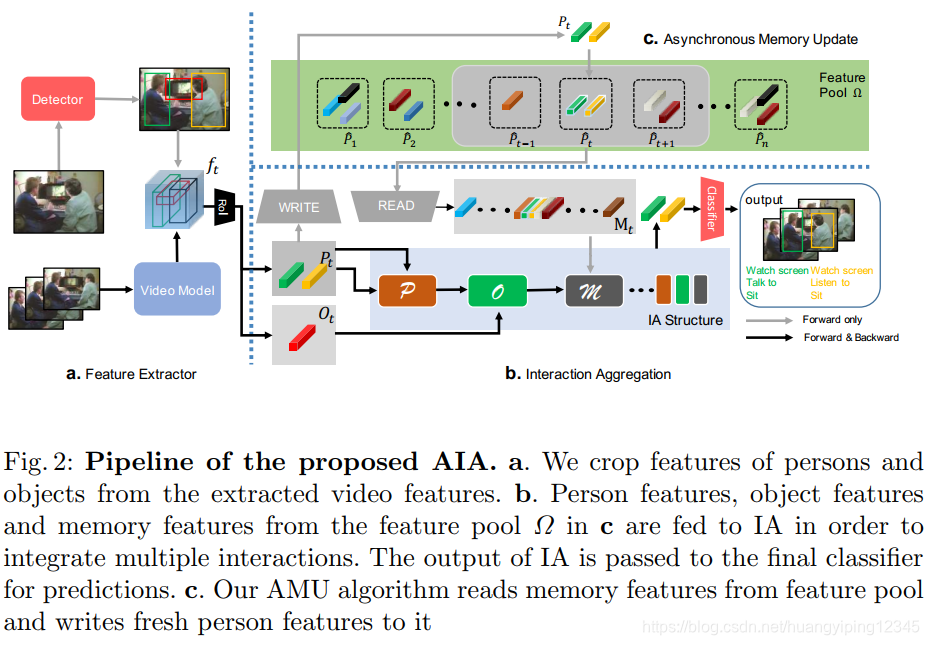
3.1 实例级和时间记忆特征
为了在视频中建立交互模型,我们需要正确地找到被查询的人与什么交互。以前的工作如[36]计算特征图中所有像素之间的交互作用。由于计算量大,这些暴力方法使用视频数据集的大小有限,难以学习像素之间的交互。因此,我们开始考虑如何获得集中的交互特征。我们观察到人总是与具体的物体和其他人互动,因此我们提取对象和人作为实例级特征。另外,视频帧之间总是高度相关的,因此我们保留了人的特征作为长期时间记忆特征。
实例级特征将从视频特征中截取。由于计算整个长视频是不可能的,所以我们将其分割为连续的短视频片段 [ v 1 , v 2 , … , v T ] [v_1,v_2,…,v_T] [v1,v2,…,vT],利用视频骨干模型 f t = F ( v t , φ F ) f_t=F(v_t,φF) ft=F(vt,φF)提取第 t t t个视频片段 v t v_t vt的 d d d维特征,其中 φ F φF φF为参数。
在 v t v_t vt的中间帧上应用检测器得到人员框和物体框。在检测到的边界框的基础上,利用RoIAlign算法从特征 f t f_t ft中裁剪出人和物体的特征, v t v_t vt中人和物体的实例级特征分别表示为 P t P_t Pt
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1741
1741

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









