







天下武功,唯快不破。在面对大数据分析的时候,快就是那不破的武功,而Spark就是这样的神器!
What is Spark
Apache Spark™ is a fast and general engine for large-scale data processing.
Spark官网说的很清楚了,它具有如下优点:
- Speed: Spark有高效的DAG执行引擎,支持循环数据流和内存计算
- Easy of Use: 支持多种语言,80多个高级别的算子
- Generality: 拥有包括SQL和数据框,MLlib(机器学习)等软件栈
- Run Everwhere: Spark运行在Hadoop,Mesos,单机或者云集群,能够访问各种数据源包括HDFS, Cassandra, HBase, and S3。
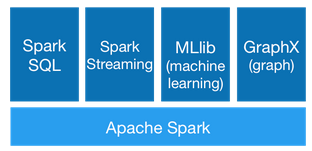
我们常说的Spark主要包括:
Why Spark so fast
内存计算
我们知道MapReduce存在以下局限:
抽象层次低,只提供了Map和Reduce两个操作,表达力欠缺。
复杂的计算需要大量的Job完成,而Job之间的关系需要开发者自己维护管理
中间结果存放在HDFS中,对迭代数据处理性能很差
ReduceTask需要等待所有MapTask都完成才可以开始
针对这些,Spark做了很多改进,其中之一就是内存计算。说到内存,Spark的一个很大的抽象就是RDD弹性分布数据集(Resilient Distributed Dataset)
RDD是Spark中对数据和计算的抽象,是Spark中最核心的概念,它表示已被分片(partition),不可变的并能够被并行操作的数据集合。对RDD的操作分为两种transformation和action。Transformation操作是通过转换从一个或多个RDD生成新的RDD。Action操作是从RDD生成最后的计算结果。在Spark最新的版本中,提供丰富的transformation和action操作,比起MapReduce计算模型中仅有的两种操作,会大大简化程序开发的难度。
RDD的生成方式只有两种:
一是从数据源读入;
另一种就是从其它RDD通过transformation操作转换;
一个典型的Spark程序就是通过Spark上下文环境(SparkContext)生成一个或多个RDD,在这些RDD上通过一系列的transformation操作生成最终的RDD,最后通过调用最终RDD的action方法输出结果。
每个RDD都可以用下面5个特性来表示,其中后两个为可选的:
分片列表(数据块列表)
计算每个分片的函数
对父RDD的依赖列表
对key-value类型的RDD的分片器(Partitioner)(可选)
每个数据分片的预定义地址列表(如HDFS上的数据块的地址)(可选)
虽然Spark是基于内存的计算,但RDD不光可以存储在内存中,根据useDisk、useMemory、useOffHeap, deserialized、replication五个参数的组合Spark提供了12种存储级别。值得注意的是当StorageLevel设置成OFF_HEAP时,RDD实际被保存到Tachyon中。Tachyon是一个基于内存的分布式文件系统,目前正在快速发展。
DAG
在图论中,如果一个有向图无法从任意顶点出发经过若干条边回到该点,则这个图是一个有向无环图(DAG图)。
因为有向图中一个点经过两种路线到达另一个点未必形成环,因此有向无环图未必能转化成树,但任何有向树均为有向无环图。
DAG可用于对数学和 计算机科学中得一些不同种类的结构进行建模。由于受制于某些任务必须比另一些任务较早执行的限制,必须排序为一个队 列的任务集合可以由一个DAG图来呈现,其中每个顶点表示一个任务,每条边表示一种限制约束,拓扑排序算法可以用来生成一个有效的序列。DAG也可以用来模拟信息沿着一个一 致性的方向通过处理器网络的过程。DAG中得可达性关系构成了一个局 部顺序,任何有限的局部顺序可以由DAG使用可达性来呈现。此外,DAG的可作为一个序列集合的高效利用空间的重叠的子序列的代表性。
相对应的概念,无向图是一个森林,无环的无向图。
选择森林的一个方向,产生了一种特殊的有向无环图称为polytree 。
不过,也有其他种类的向无环图,它们不是由面向无向无环图的边构成的。
出于这个原因,称其为有向无环图比无环有向图或者无环图更确切。
线程模型
Apache Spark在Master和Slave通讯直接采用了开源软件Akka,该软件实现了Actor模型,性能非常高。
Spark应用程序的运行环境是由多个独立的Executor进程构建的临时资源池构成的。Spark同节点上的任务以多线程的方式运行在一个JVM进程中,可带来以下好处:
1)任务启动速度快,与之相反的是MapReduce Task进程的慢启动速度,通常需要1s左右;
2)同节点上所有任务运行在一个进程中,有利于共享内存。这非常适合内存密集型任务。
3)同节点上所有任务可运行在一个JVM进程(Executor)中,且Executor所占资源可连续被多批任务使用,不会在运行部分任务后释放掉,这避免了每个任务重复申请资源带来的时间开销,对于任务数目非常多的应用,可大大降低运行时间。与之对比的是MapReduce中的Task:每个Task单独申请资源,用完后马上释放。
How Spark runs
这个是一个很大的话题,很多书和博客都有介绍,当然最好的是读读Spark的源代码,这样是最好不过的。下面列出几张图,以作笔记。
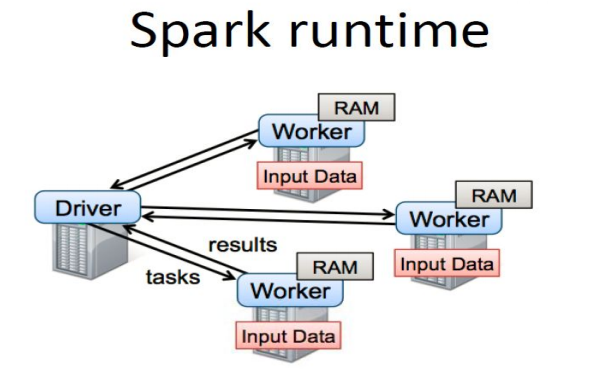

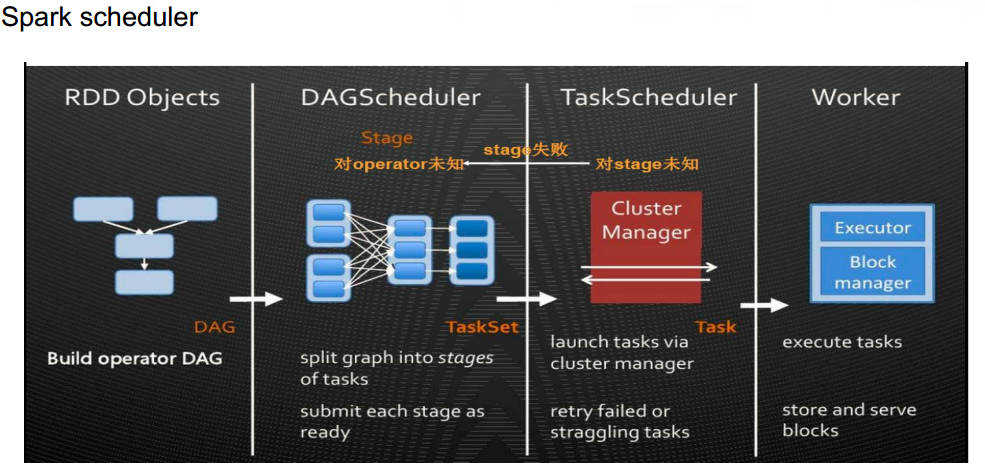
How to setup Spark
Spark运行有多种方式,这里以Spark运行在Yarn上为例,做个简单的介绍。
1.启动Hadoop(检查配置最好相同,例如时间/区同步)
2.安装配置scala,spark
export SCALA=/home/hadoop/tools/scala-2.11.0
export PATH=$PATH:$SCALA/bin:/home/hadoop/sparkc/sbt/bin
3.修改配置
conf/spark-env.sh
#!/usr/bin/env bash
export JAVA_HOME=/usr/local/jdk1.7.0_79
export SCALA_HOME=/home/hadoop/tools/scala-2.11.0
export SPARK_WORKER_MEMORY=1g
export SPARK_MASTER_IP=192.168.232.128
export MASTER=spark://192.168.232.128:7077
conf/slaves
# A Spark Worker will be started on each of the machines listed below.
vm11
vm22
vm33
将spark安装copy到其他节点上,即可开始启动
./sbin/start-all.sh
检查状况:
1.jps
[hadoop@vm11 conf]$ jps
5231 SecondaryNameNode
6448 Master
6589 Worker
5525 NodeManager
5001 NameNode
7078 Jps
5092 DataNode
5430 ResourceManager
2.查看logs/
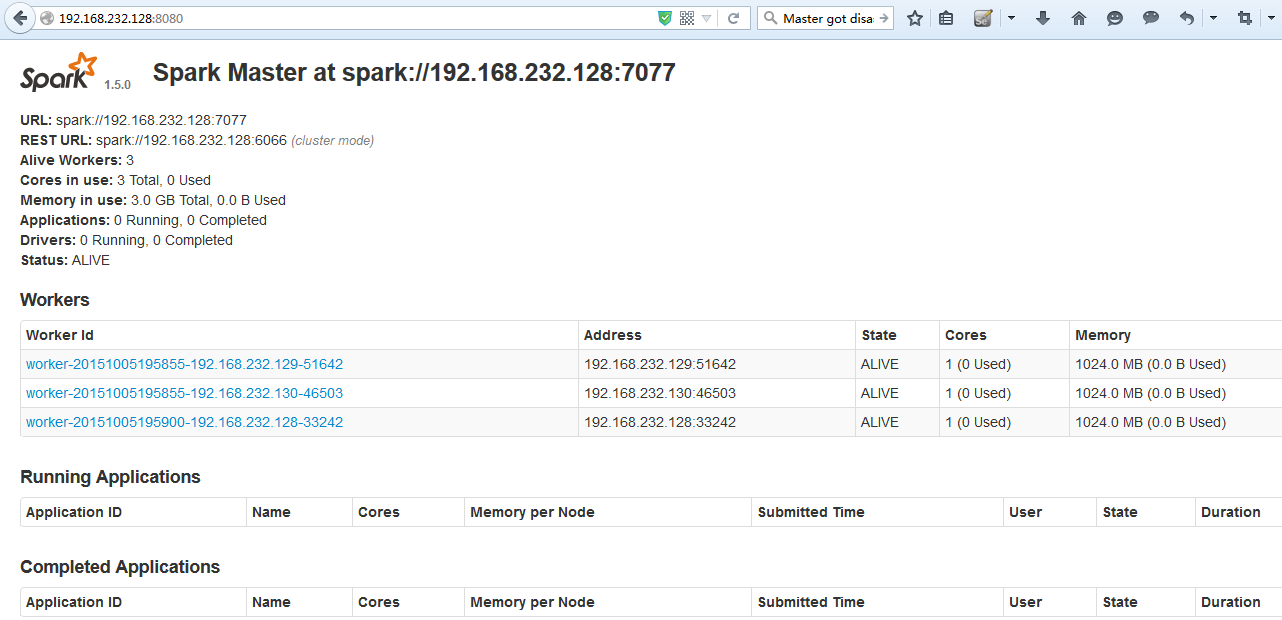
3.webUI查看 (http://192.168.232.128:8080/)
测试运行:
[hadoop@vm22 bin]$ ./run-example org.apache.spark.examples.SparkPi
出现错误
15/10/05 21:54:54 INFO Slf4jLogger: Slf4jLogger started
15/10/05 21:54:57 INFO Remoting: Starting remoting
15/10/05 21:55:08 ERROR SparkContext: Error initializing SparkContext.
java.util.concurrent.TimeoutException: Futures timed out after [10000 milliseconds]
at scala.concurrent.impl.Promise$DefaultPromise.ready(Promise.scala:219)
看到master的log有这样的
15/10/05 22:08:23 INFO Master: I have been elected leader! New state: ALIVE
15/10/05 22:08:23 INFO Master: 192.168.232.129:56472 got disassociated, removing it.
15/10/05 22:08:23 INFO Master: 192.168.232.130:43993 got disassociated, removing it.
15/10/05 22:08:23 INFO Master: 192.168.232.129:56472 got disassociated, removing it.
看起来是连接不够稳定。
重启后又出现:
15/10/05 22:14:31 WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
这个果然是吃内存啊,我的虚拟机设置太小了。















 2524
2524

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









