Abstract
我们提出了BART,一个去噪的自动编码器。BART通过(1)用任意噪声函数破坏文本进行训练,(2)学习一个模型来重建原始文本。它使用了一个标准的基于转换器的神经机器翻译架构,尽管它很简单,但可以看作是推广BERT(由于双向编码器)、GPT(带有从左到右的解码器)和许多其他更新的预训练方案。我们评估了许多噪声方法,通过随机打乱原始句子的顺序和使用一种新的填充方案来找到最佳性能,其中文本的跨度被替换为一个掩码标记。BART在微调文本生成时特别有效,但对理解任务也很有效。 它将RoBERTa的性能与GLUE和SQUAD上类似的培训资源相匹配,在一系列抽象对话、问题回答和总结任务上取得了最新的结果,可获得多达6个
ROUGE。BART还为机器翻译提供了比反向翻译系统1.1的BLEU增加,只提供了目标语言的预训练。我们还报告了在BART框架内复制其他预训练方案的消融实验,以更好地衡量哪些因素对最终任务表现影响最大。
Introduction
自我监督方法在广泛的NLP任务中取得了显著成功(Mikolov等人,2013年;Peters等人,2018年;Devlin等人,2019年;Joshi等人,2019年;杨等人,2019年;刘等人,2019年)。最成功的方法是掩蔽语言模型的变体,它是去噪自动编码器,它被训练来重建单词的随机子集被屏蔽的文本。最近的研究表明,通过改善掩牌的分布(Joshi等人,2019),掩牌的预测顺序(Yang等人,2019),以及替代掩牌的可用环境(Dong等人,2019),取得了进展。然而,这些方法通常只关注特定类型的结束任务(例如,跨度预测、生成等),限制了它们的适用性。
在本文中,我们提出了BART,它对一个结合双向和自回归变压器的模型进行了预训练。BART是一个去噪自动编码器建立的序列到序列模型,适用于非常广泛的最终任务。预训练有两个阶段,(1)文本被任意的噪声函数破坏,而(2)学习一个序列到序列的模型来重建原始文本。BART使用了一个标准的基于trantor的神经机器翻译架构,尽管它很简单,但可以被视为概括BERT(由于双向编码器)、GPT(从左到右的解码器)和许多其他最近的预训练方案(见图1)。这种设置的一个关键优点是噪声的灵活性;任意转换可以应用于原始文本,包括更改其长度。我们评估了许多噪声方法,通过随机打乱原始句子的顺序和使用一种新的填充方案来找到最佳性能,其中任意长度的文本跨度(包括零长度)被替换为一个掩码标记。该方法通过强迫模型更多地推理整体句子长度,并对输入进行更长范围的转换,概括了BERT中的原始单词掩蔽和下一个句子预测目标。
BART在对文本生成进行微调时特别有效,但对理解任务也很有效。
BART还开辟了思考微调的新方法
Model
BART是一种去噪自动编码器,它将损坏的文档映射到其派生出来的原始文档。它被实现为一个序列到序列的模型与一个双向编码器在损坏的文本和一个从左到右的自回归解码器。对于预训练,我们优化了原始文档的负对数似然值。
Architecture
BART使用了来自(Vaswanietal.,2017)的标准序列到序列的转换器架构,除了,在GPT之后,我们将ReLU激活函数修改为GeLU(Hendrycks&Gimpel,2016),并从N(0,0.02)初始化参数。对于我们的基本模型,我们在编码器和解码器中使用6层,对于我们的大型模型,每个层使用12层。该架构与BERT中使用的架构密切相关,有以下差异:(1)解码器的每一层额外对编码器的最终隐藏层执行交叉注意(就像变压器序列到序列模型);(2)BERT在单词预测之前使用了一个额外的前馈网络,而BART没有。总的来说,BART包含的参数比同等大小的BERT模型多10%。
Pre-training BART
BART的训练是通过破坏文档,然后优化一个重建损失——解码器的输出和原始文档之间的交叉熵。与现有的去噪自动编码器不同,
它是针对特定的噪声方案而定制的,BART允许我们应用任何类型的文件损坏。在极端情况下,关于源的所有信息丢失,BART相当于语言模型。
Token Masking
在BERT(Devlinetal.,2019)之后,随机令牌被采样并替换为[MASK]元素。
Token Deletion
从输入中删除随机标记。与令牌掩蔽相比,模型必须决定哪些位置缺少输入。
Text Infifilling
许多文本跨度被采样,跨度长度来自泊松分布(λ=3)。每个跨度都被替换为一个[MASK]标记。0个长度的跨度对应于[MASK]标记的插入。
Fine-tuning BART
由BART产生的表示可以用多种方式用于下游应用程序。
Sequence Classifification Tasks ;Token Classifification Tasks ;Sequence Generation Tasks ;Machine Translation
Comparing Pre-training Objectives
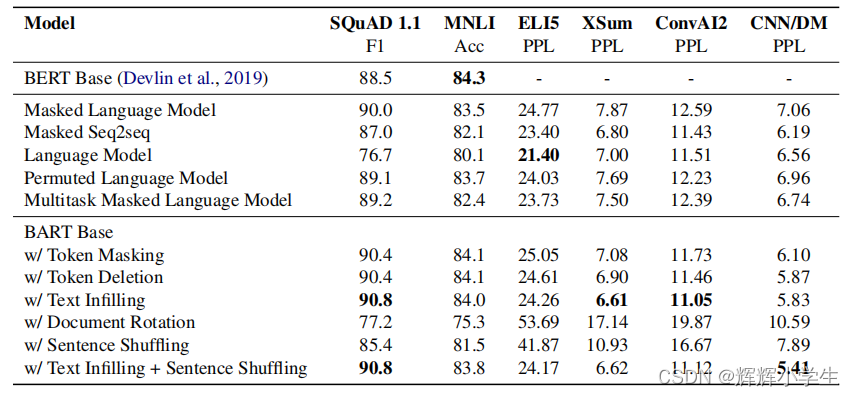
与以前的工作相比,BART在培训前支持更广泛的噪声方案。我们使用基本大小的模型(6个编码器层和6个解码器层,隐藏大小为768)比较一系列选项,在5个完整的任务的代表性子集上进行评估。
Comparison Objectives 略
Tasks
SQuAD
(Rajpurkaretal.,2016)在维基百科段落上的一个提取式问答任务。答案是从给定的文档上下文中提取的文本跨度。与BERT类似(Devlinetal.,2019)类似,我们使用连接的问题和上下文作为BART编码器的输入,另外将它们传递给解码器。该模型包括分类器对每个标记的开始和结束索引进行预测。
MNLI
(Willamsetal.,2017),一个双文分类任务,以预测一个句子是否包含另一个句子。微调后的模型将附加了一个EOS标记的两个句子连接起来,并将它们传递给BART编码器和解码器。与BERT相比,EOS标记的表示法用于对句子关系进行分类。
ELI5
一个长形式的抽象问题回答数据集。模型生成基于问题和支持文档的连接的答案
XSum
一个具有高度抽象的摘要的新闻摘要数据集。
ConvAI2
一个对话反应生成任务,基于背景和一个角色。
CNN/DM
这是一个新闻摘要数据集。这里的摘要通常与源句密切相关。
Results
Performance of pre-training methods varies signififi-
cantly across tasks 训练前方法的有效性高度依赖于任务。例如,一个简单的语言模型获得了最好的ELI5性能,但最差的阵容结果。
Token masking is crucial
基于轮换文档或排列句子的培训前目标在孤立时表现不佳。这些成功的方法要么使用令牌删除或掩蔽,要么使用自我注意掩蔽。删除似乎优于屏蔽生成任务。
Left-to-right pre-training improves generation
蒙面语言模型和置换语言模型在生成方面的表现不如其他模型,这是我们认为在预训练过程中不包括从左到右的自回归语言建模的唯一模型。
Bidirectional encoders are crucial for SQuAD
正如之前的工作(Devlinetal.,2019)所述,仅从左到右的解码器在SQuAD上表现很差,因为未来的上下文在分类决策中至关重要。然而,BART只有双向层数的一半就实现了类似的性能。
The pre-training objective is not the only important
factor
我们的排列语言模型的表现不如XLNet好(Yang等人,2019年)。其中某种差异可能是由于没有包括其他体系结构改进,如相对位置嵌入或段级递归。
Pure language models perform best on ELI5
ELI5数据集是一个离群值,比其他任务具有更高的困惑度,并且是唯一一个使其他模型优于BART的生成任务。纯语言模型表现最好,这表明当输出仅受到输入的松散约束时,BART的效果较差。
BART achieves the most consistently strong perfor
mance.
除了ELI5之外,使用文本填充的BART模型在所有任务上都表现良好。
Large-scale Pre-training Experiments
最近的研究表明,当预训练扩展到大批量时,下游性能可以显著提高(Yang等人,2019;Liu等人,2019)和语料库。为了测试BART在这种情况下的表现如何,并为下游任务创建一个有用的模型,我们使用与RoBERTa模型相同的规模来训练BART。
Experimental Setup略
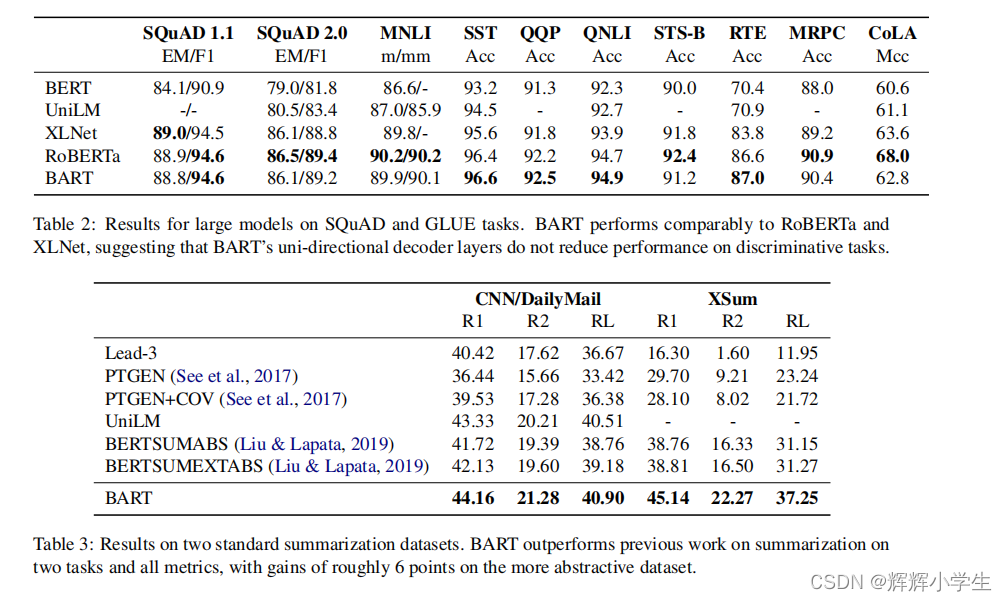
表2比较了BART与最近几种研究充分的SQuAD和GLUE任务的性能(Warstadt等人,2018;Socher等人,2013;多兰和布罗克特,2005;阿吉尔等人,2007;威廉姆斯等人,20018;达根等人,2006年;莱韦斯克等人,2011年)。最直接的可比性基线是RoBERTa,它使用相同的资源进行了预先训练,但目标不同。总的来说,BART的表现类似,在大多数任务上,模型之间只有很小的差异。这表明BART在生成任务上的改进并不以牺牲分类性能为代价。
Generation Tasks
我们还实验了几个文本生成任务。BART作为从输入到输出文本的标准序列到序列模型进行了微调。在微调过程中,我们使用标签平滑交叉熵损失(Pereyraetal.,2017),平滑参数设置为0.1。在生成过程中,我们将波束大小设置为5,在波束搜索中删除重复的三元图,并在验证集上使用最小、最大、长度惩罚来调整模型(Fanetal.,2017)。
Summarization
为了与最先进的总结数据集进行比较,我们在两个总结数据集CNN/DailyMail和XSum上呈现结果,它们具有不同的属性。CNN/《每日邮报》上的总结往往与源句相似。提取模型在这里做得很好,甚至前三个源句的基线也具有很高的竞争力。然而,BART的表现优于所有现有的工作。相比之下,XSum具有高度的抽象性,而提取性模型的性能较差。BART在之前的工作上,在所有胭脂指标上领先了大约6.0分——这代表了在这个问题上的显著进步。定性地说,样品质量较高(见6)。
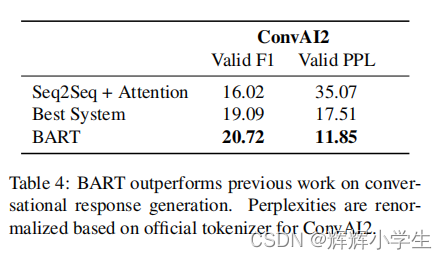
Dialogue
我们评估了CONVAI2上的对话响应生成(Dinan等人,2019年),在该过程中,代理必须基于之前的背景和文本指定的角色生成响应。BART在两个自动化指标上优于之前的工作。
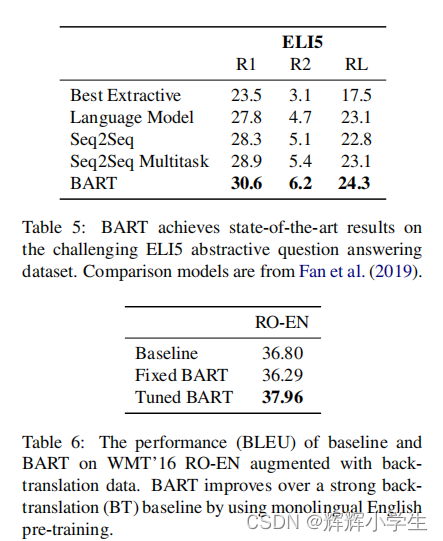
Abstractive QA
我们使用最近提出的ELI5数据集来测试该模型生成长自由形式答案的能力。我们发现BART通过1.2rouge-L,但数据集仍然具有挑战性,因为答案只是问题的弱规格。
Translation
我们还评估了WMT16罗马英语的性能,并补充了Sennrich等人(2016)的反向翻译数据。我们使用一个6层变压器源编码器将罗马尼亚语映射到一个BART能够降噪成英语的表示中,遵循3.4中引入的方法。实验结果见表6。我们将我们的结果与基线变压器架构(Vaswanietal.,2017)与变压器大变压器设置(基线行)进行了比较。我们在固定的BART和调优的BART行中展示了我们的模型的两个步骤的性能。对于每一行,我们在原始的WMT16罗马尼亚-英语上进行实验,并添加了反向翻译数据。我们使用的光束宽度为5,长度惩罚为α=1。初步结果表明,在没有反向翻译数据的情况下,我们的方法效果较差,而且容易发生过拟合——未来的工作应该探索额外的正则化技术。
Qualitative Analysis
BART在总结指标上显示了很大的改进,比之前的最先进水平提高了6个点。为了理解BART在自动化指标之外的性能,我们定性地分析了它的生成。表7显示了由BART生成的示例摘要。例子取自训练前语料库创建后发表的维基新闻文章,以消除模型的训练数据中所描述的事件的可能性。继Narayan等人(2018)之后,我们在总结文章之前删除了文章的第一句话,因此没有容易的文档提取摘要。
不出所料,模型输出是流利的语法英语。然而,模型输出也是高度抽象的,很少从输入中复制一些短语。输出通常也是事实准确的,并整合了来自整个输入文档的支持证据和背景知识(例如,正确填写姓名,或推断PG&E在加州运营)。在第一个例子中,要推断鱼类是在保护珊瑚礁免受全球变暖的影响,就需要从文本中进行非常重要的推断。然而,关于这项研究发表在《科学》杂志上的说法并没有得到消息来源的支持。这些样本表明,BART预训练已经学会了自然语言理解和生成的强大结合。
Related Work 略
Conclusions
我们引入了BART,这是一种预训练方法,它可以学习将损坏的文档映射到原始文档。BART在鉴别任务上取得了与RoBERTa相似的性能,同时在许多文本生成任务上取得了新的最新结果。未来的工作应该探索新的方法来破坏培训前的文档,也许可以根据特定的最终任务来定制它们。

























 480
480

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









