







系列文章
目录
摘要
本文目的是从上游大型模型进行知识蒸馏以应用于下游自动摘要任务,主要总结了自动摘要目前面临的难题,BART模型的原理,与fine tune 模型的原理。对模型fine tune部分进行了代码复现,通过fine tune使得student模型能够在一块8G显存的GPU上进行训练。
论文标题:
- PRE-TRAINED SUMMARIZATION DISTILLATION
url: https://arxiv.org/pdf/2010.13002.pdf - BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
url:https://arxiv.org/abs/1910.13461
自动摘要目前的问题
- 自动摘要的输入长度不定,输出长度也不定
- 需要被摘要的文本无统一结构,因此难以根据文章结构学习出合适的模型。
- 传统的抽取式摘要不能很好概括文本信息
seq2seq
在推理模式中,即当我们想解码未知的输入序列时,我们会经历一个过程:
1)将输入序列编码为状态向量
2)从大小为1的目标序列开始(仅是序列开始字符)
3)将状态向量和1个字符的目标序列提供给解码器,以生成下一个字符的预测。
4)使用这些预测来采样下一个字符(argmax)。
5)将采样的字符追加到目标序列
6)重复上述过程直到生成序列结束字符或达到字符数限制。
模型
BART
BART是一种用于序列到序列模型预处理的去噪自编码器。它的训练方法是:
(1)用任意的噪声函数破坏文本,
(2)学习一个模型来重建原始文本。
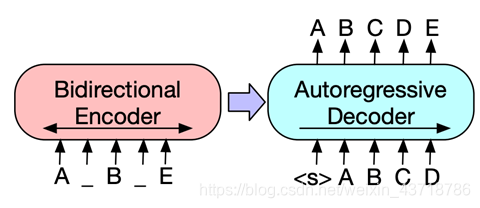
- 双向编码(类似BERT),单向解码
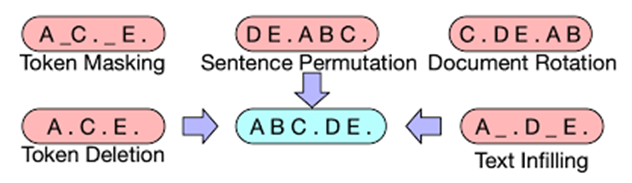
- 训练前的任务包括随机打乱原始句子的顺序和一个新的填充方案,其中文本的范围被一个单一的掩码标记取代
Fine-Tune
从一个训练好大型任务中直接迁移部分参数,再使用下移任务的训练集数据进行微调
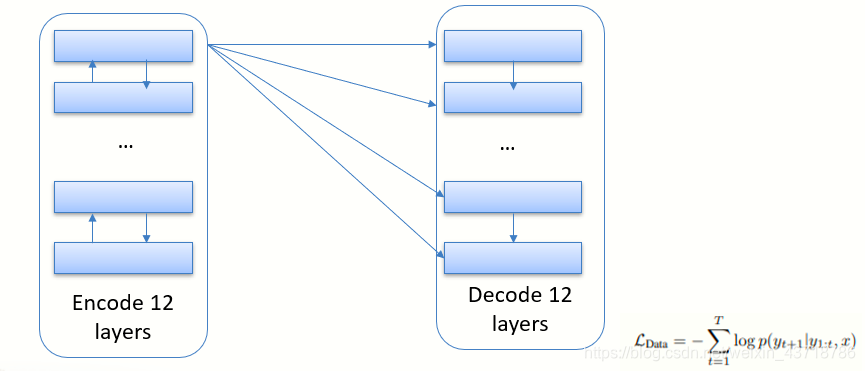
- Fine-Tune从一个模型(teacher model)进行参数的迁移得到新模型(student model)
- 这篇论文student model复制teacher model的全部层,通过实验选取效果最好的3层decode:0, 5, 11.
Fine-Tune另外测评方法
Pseudo-labels
Fine-Tune的目的是获得和teacher模型一样的预测结果,即最小化损失函数:
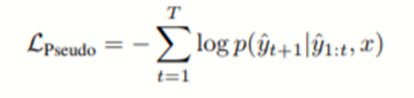
Direct Knowledge Distillation (KD)
理想条件是student模型对下一个词的预测所产生的概率分布和teacher模型相同。
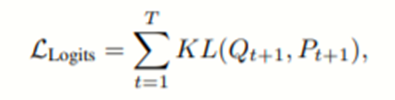
或者使得decode层输出隐状态相同
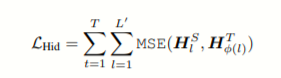
最终衡量标准
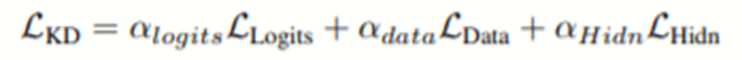
其中三个α基于不同损失函数以不同权重,其最终目的是使得加权损失函数最小
实验方案
beam search
预测的时候,假设词表大小为3,内容为a,b,c。beam size是2,decoder解码的时候:
1: 生成第1个词的时候,选择概率最大的2个词,假设为a,c,那么当前的2个序列就是a和c。
2:生成第2个词的时候,我们将当前序列a和c,分别与词表中的所有词进行组合,得到新的6个序列aa ab ac ca cb cc,计算每个序列的得分并选择得分最高2个序列,作为新的当前序列,假如为aa cb。
3:后面会不断重复这个过程,直到遇到结束符或者达到最大长度为止。最终输出得分最高的2个序列。
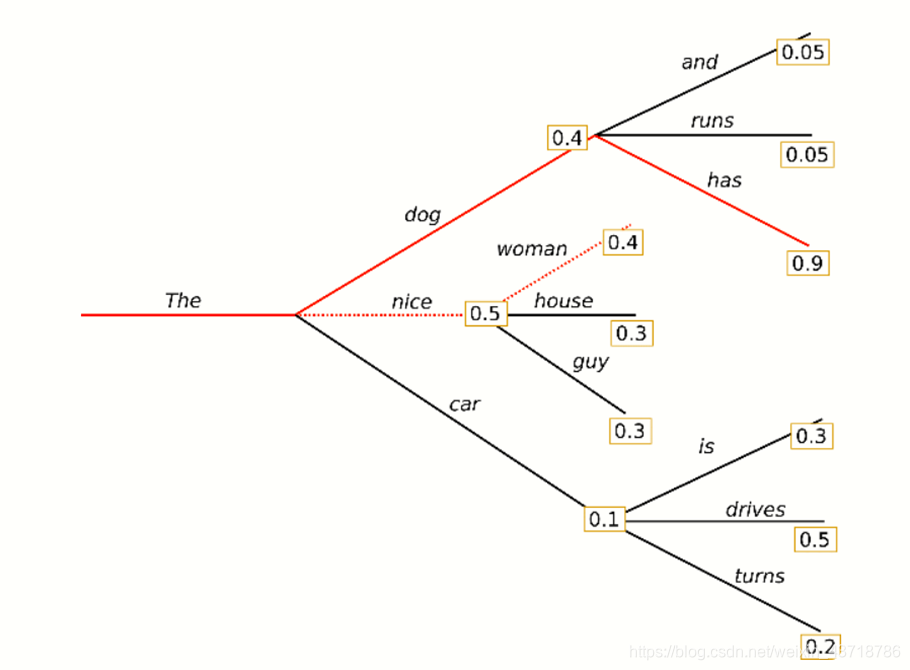
上图解释参考:
https://blog.csdn.net/weixin_43718786/article/details/116991489
提前停止
我们在任何满足满足以下条件的时间点停止训练:第五阶段结束,或者连续四次评估的分数不增加(一个完整的阶段)。
在使用全尺寸(完全复制)encod的实验中,我们在训练期间不改变它的参数。初步实验表明,这不会影响性能,但微调速度提高了5.6倍。
我们还冻结了位置和文字的embedding。
实验结果
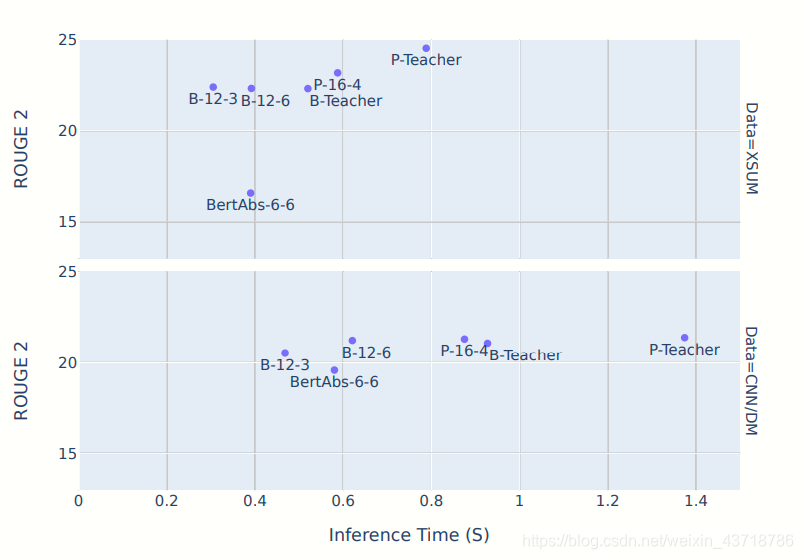
从结果来看,保持encode层不变,从12个decode层中抽取三层是非常有效的解决方案。(兼顾成绩与训练时间)
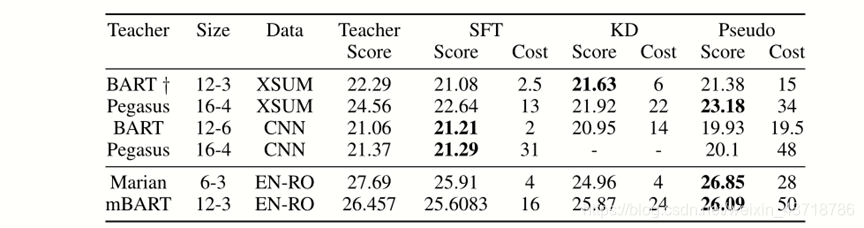 <
<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1151
1151

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









