









【2020CVPR】
代码地址:https://panzhang0212.github.io/CoCosNet/
Zhang, Pan, Bo Zhang, Dong Chen, Lu Yuan, and Fang Wen. “Cross-domain Correspondence Learning for Exemplar-based Image Translation.” arXiv preprint arXiv:2004.05571 (2020).
任务:基于参考图像的图像转换
概述
本文研究的问题是基于语义图像和风格参考图像的图像转换问题。
本文提出的模型先将输入语义图像和输入参考风格图像分别通过编码器进行领域对齐,并使用特征计算两者每个像素点之间的相似度,并根据该相似度得到变形的参考图像,再将其使用positional normalization和spatially-variant denormalizaiton(类似于AdaIN)的方法,在从固定噪声生成最终图像的过程中将该风格注入图像。
损失函数由伪参考图像对损失、领域对齐损失、语义约束损失、风格约束损失、相似度矩阵正则化和生成对抗损失组成。
模型结构
 A域的输入语义图像
x
A
x_A
xA,B域的输入参考风格图像
y
B
y_B
yB,
x
B
x_B
xB为
x
A
x_A
xA对应的在B域的图像(但是风格和
y
B
y_B
yB不一样)
A域的输入语义图像
x
A
x_A
xA,B域的输入参考风格图像
y
B
y_B
yB,
x
B
x_B
xB为
x
A
x_A
xA对应的在B域的图像(但是风格和
y
B
y_B
yB不一样)
先将输入语义图像和输入参考风格图像分别通过编码器进行领域对齐,并使用该计算两者每个像素点之间的相似度,并根据该相似度得到变形的参考图像,再将其使用类似于AdaIN的方法,在从固定噪声生成最终图像的过程中将该风格注入图像
1、领域对齐网络
首先分别使用各自的编码器将
x
A
x_A
xA和
y
B
y_B
yB转换到共享域S特征
x
S
x_S
xS和
y
S
y_S
yS
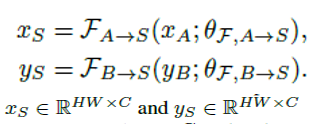
再使用两者特征经过channel-wise的归一化后计算每个像素点之间的匹配度
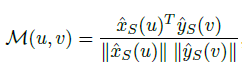
将该相似度作为系数,将输入风格参考图像作为基,通过加权求和得到变形的参考图像
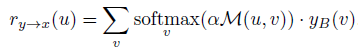
2、转换网络
从一个固定的常量编码z开始,通过卷积层生成最终的图像
每个block使用positional normalization和spatially-variant denormalizaiton来将变形的参考图像融入进生成图像
整体方法类似于AdaIN,positional normalization指归一化时每张图像按照每个像素点求均值和方差(即同一位置的不同通道的均值和方差),spatially-variant denormalization指将变形的参考图像r_{y->x}经过卷积层,从而得到每个位置的放大系数和偏置
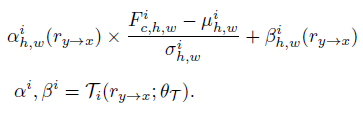
最终生成图像为
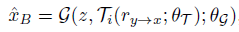
整体网络结构如下,其中style encoderx7表示分别使用7个style encoder得到生成器中对应每个block中spatially-variant denormalization中每个对应位置的α和β
Domain adaptor中卷积层为conv-IN-LeakRelU,两个域先各自使用domain adaptor,然后再使用shared adaptive feature block

损失函数
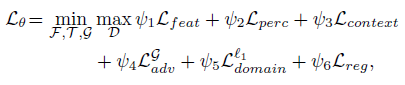
1、伪参考图像对损失
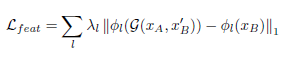
先对
x
B
x_B
xB进行随机的变形得到
x
B
′
x'_B
xB′,再将其作为输入参考风格图像,与对应的
x
A
x_A
xA进行图像,将生成图像与
x
B
x_B
xB约束两者在预训练的VGG19模型上各层的特征距离
2、领域对齐损失
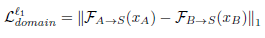
约束配对的图像转换公共域S时两者特征的距离,在计算前两者分别进行channel-wise的归一化
3、参考图像转换损失
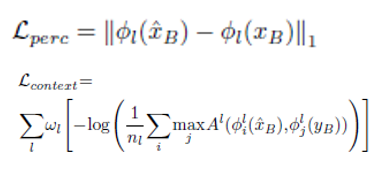
分别使用两个损失来约束生成图像的高层语义信息和
x
B
x_B
xB相近,风格信息和
y
B
y_B
yB相近
使用预训练的VGG19网络,高层语义使用relu4_2层,风格信息使用relu2_2至relu5_2层
4、相关度正则化
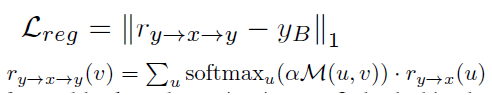
r
y
−
>
x
r_{y->x}
ry−>x是之前使用
x
A
x_A
xA和
y
B
y_B
yB每个像素点之间的相关度作为系数,
y
B
y_B
yB图像作为基,进行加权求和得到的变形参考图像,
r
y
−
>
x
−
>
y
r_{y->x->y}
ry−>x−>y则是同样将相关度作为系数,将
r
y
−
>
x
r_{y->x}
ry−>x作为基,重新进行加权求和试图将图像变换回
y
B
y_B
yB
5、生成对抗损失
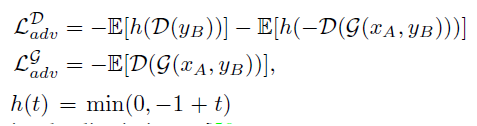
数据集
训练时所有图像选取256*256大小
1、ADE20k:20k张自然场景图,每张图有150类的分割mask
2、ADE20k-outdoor:从ADE20k中选出的户外图像
3、CelebA-HQ:使用Canny边缘检测器从图像中抽取人脸边缘
4、Deepfashion:52712张穿着时尚衣服的人物图像,使用OpenPose抽取人身体上的关键点
评价指标
1、FID
2、SWD(sliced Wasserstein distance)

随机生成16384张图像,并在每个尺度的拉普拉斯金字塔中选择128个由3通道的7*7像素组成的描述子,对于生成图像和真实图像各自的每个尺度的描述子分别按通道进行归一化,然后计算SWD距离来估计两者统计上的相似度
低像素尺度的描述子相似度代表了图像结构,而高像素尺度的描述子相似度代表了边缘和噪声等像素级别的性质
3、语义一致性
使用在ImageNet上预训练的VGG模型的高层级特征(relu3_2,relu4_2,relu5_2)计算生成图像和输入语义图像(
x
A
x_A
xA)之间的特征余弦距离
4、风格相关性
使用度量颜色和纹理等的低层级特征(relu1_2,relu2_2)来度量生成图像和输入参考图像(
y
B
y_B
yB)之间的距离
实验
1、生成图像对比

2、人类主观评价

3、跨领域的相关度
利用correlation matrix可以计算输入语义图像和输入参考风格图像之间不同点的对应关系

4、定量指标

语义一致性

风格相关性

5、ablation study

6、图像编辑
给定一张图像及其对应的mask,对语义mask进行修改,再将原图像作为参考风格图像

7、人脸化妆
只需对一个人进行化妆的编辑,就可以将其作为参考风格图像,对其他图像进行同样的变换















 3754
3754











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









