






Cross-domain Correspondence Learning for Exemplar-based Image Translation
基于示例的图像翻译的跨域对应学习
作者:Pan Zhang, Bo Zhang, Dong Chen, Lu Yuan, Fang Wen
期刊:CVPR(2020)
摘要
本文提出了一个基于示例的图像翻译的通用框架 ,它在给定一个示例图像。输出具有与范例中语义对应对象一致的样式(例如,颜色、纹理)。本文建议共同学习跨域对应和图像翻译,这两项任务相互促进,因此可以在弱监督下学习。来自不同域的图像首先与建立密集对应的中间域对齐。然后,网络根据样本中语义对应的补丁的出现来合成图像。
解决问题
直接学习从语义分割掩码到样本图像的映射,大多数将样本的样式编码为潜在样式向量,网络从中合成具有与样本相似的所需样式的图像。然而,风格代码只描述了范例的全局风格,而不管特定的相关信息。从而导致一些地方风格在最终的形象中被“冲刷掉”。 为了解决这个问题,必须在图像翻译之前建立输入和范例之间的跨域对应关系。

网络架构
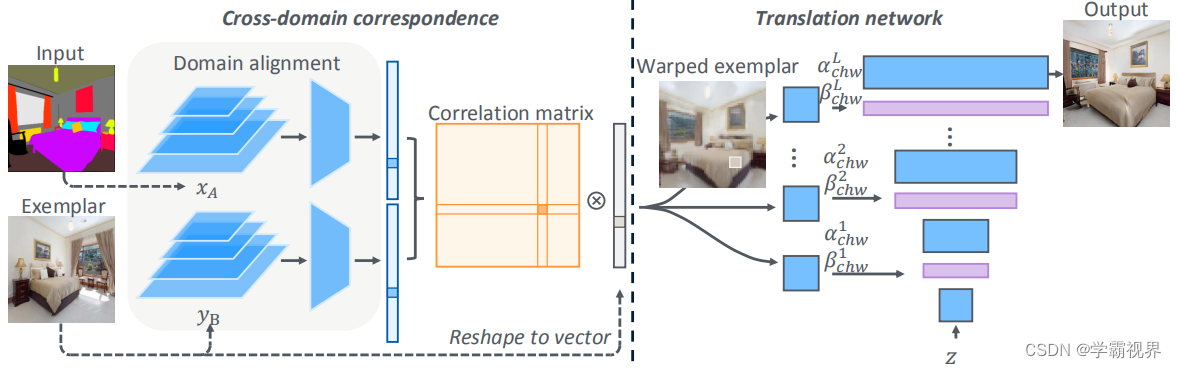
网络包含两个部分:跨域对齐网络和图像生成网络
大致流程:
跨域对齐网络:把两个域的图像映射到一个中间域,在中间域上找到二者的匹配关系,然后利用匹配关系扭曲示例图像。
图像转换网络:利用多层卷积和扭曲的示例图像逐步生成高质量的目标域图像。
跨域对齐网络:
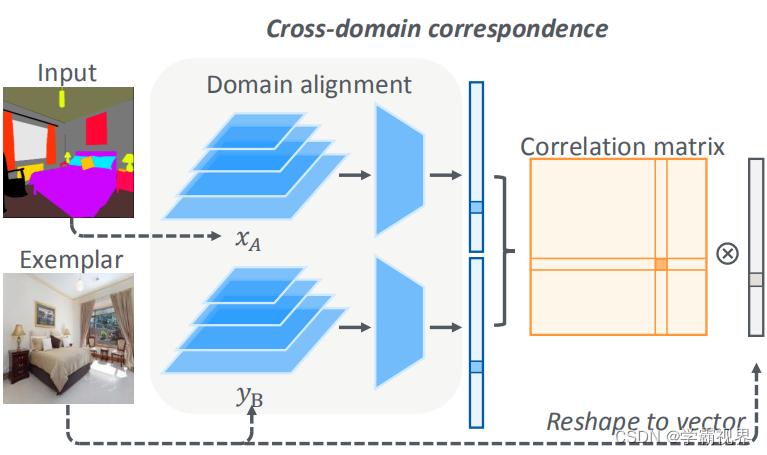
步骤一:输入图像XA是A域的,示例YB是B域的,把他们映射到同一个中间域S的话就可以较为方便地找到他们之间的语义对应关系,将 x A 和 y B 馈入特征金字塔网络通过利用局部和全局图像上下文来提取多尺度深度特征,提取的特征图进一步转换为 S 中的表示XS和YS。

步骤二:都转换到S域之后就要找到他们之间的语义相关性,首先计算一个S域中他们俩的相关矩阵;

根据 M 扭曲 yB 并获得扭曲的样本,具体来说:通过选择yB中最相关的像素加权平均。

图像生成网络:
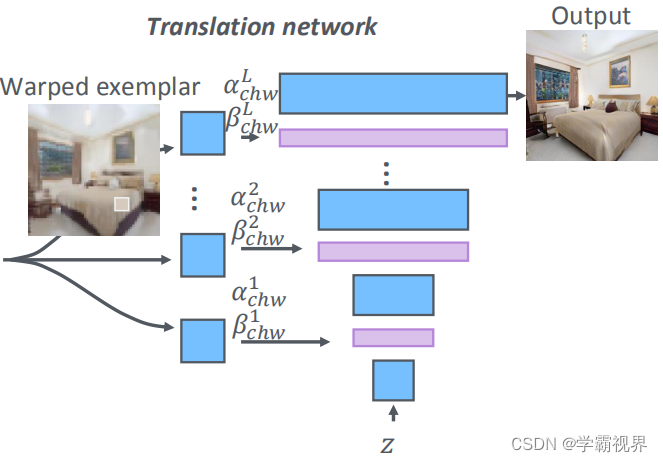
翻译网络有 L 层,通过逐步卷积逐步注入扭曲后的示例样式,每一次注入风格都是通过位置归一化和空间自适应非规范化。最终得到输出图片。
文献阅读笔记的翻译是来自于: 学霸视界(xbsj.cool)推荐大家使用,可以免费翻译PDF!















 544
544











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









