







 提出一种新的GAN训练方法,从低分辨率图像开始逐步增加细节。该方法显著提升了图像生成质量和训练稳定性,实现1024*1024高清图像生成,并引入多项技术创新。
提出一种新的GAN训练方法,从低分辨率图像开始逐步增加细节。该方法显著提升了图像生成质量和训练稳定性,实现1024*1024高清图像生成,并引入多项技术创新。
《Progressive Growing of GANs for Improved Quality, Stability, and Variation》
文章目录
论文结构
- Introduction
- Progressive growing of GANs
- Increasing variation using
minibatch standard deviation - Normalization in generator and
discriminator
4.1 Equalized learning rate
4.2 Pixelwise feature vector
normalization in generator - Multi-scale statistical similarity
for assessing GAN results - Experiments
6.1 Importance of individual contributions in
terms of statistical similarity
6.2 Convergence and training speed
6.3 High-resolution image generation using
CelebA-HQ dataset
6.4 LSUN results
6.5 CIFAR10 inception scores - Discussion
摘要
原文
We describe a new training methodology for generative adversarial networks. The key idea is to grow both the generator and discriminator progressively: starting from a low resolution, we add new layers that model increasingly fine details as training progresses. This both speeds the training up and greatly stabilizes it, allowing us to produce images of unprecedented quality, e.g., CelebA images at 1024^2. We also propose a simple way to increase the variation in generated images, and achieve a record inception score of 8.80 in unsupervised CIFAR10. Additionally, we describe several implementation details that are important for discouraging unhealthy competition between the generator and discriminator. Finally, we suggest a new metric for evaluating GAN results, both in terms of image quality and variation. As an additional contribution, we construct a higher-quality version of the CelebA dataset.
总结
- 使用渐进的方式来训练生成器和判别器:先从生成低分辨率图像开始,然后不断增加模型层数来提升生成图像的细节
- 这个方法能加速模型训练并大幅提升训练稳定性,生成前所未有的的高质量图像(1024*1024)
- 提出了一种简单的方法来增加生成图像的多样性
- 介绍了几种限制生成器和判别器之间不健康竞争的技巧
- 提出了一种评价GAN生成效果的新方法,包括对生成质量和多样性的衡量
- 构建了一个CELEBA数据集的高清版本
研究背景
Research background
生成式模型的类别
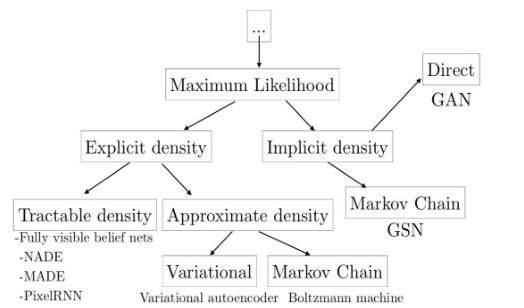
•显性密度模型
- 易解显性模型:定义一个方便计算的密度分布,主要的模型是Fully visible belief nets,简称FVBN,也被称作Auto-Regressive Network
- 近似显性模型:可以定义任意的密度分布,使用近似方法来求解
隐性密度模型
- GAN
• 神经自回归网络(PixelRNN/CNN)
通过链式法则把联合概率分布分解为条件概率分布的乘积使用神经网络来参数化每个P
PixelRNN逐像素生成,效率很低,PixelCNN效果不如PixelRNN
• VAE-GAN
编码器:使P(z|x)逼近分布P(z),比如标准正态分布,同时最小化生成器(解码器)和输入x的差距
解码器:最小化输出和输入x的差距,同时要骗过判别器
判别器:给真实样本高分,给重建样本和生成样本低分
图像生成的评价指标
• 可以评价生成样本的质量
• 可以评价生成样本的多样性,能发现过拟合、模式缺失、模式崩溃、直接记忆样本的问题
• 有界性,即输出的数值具有明确的上下界
• 给出的结果应当与人类感知一致
• 计算评价指标不应需要过多的样本
• 计算复杂度尽量低
推荐阅读:GAN评价指标最全汇总 - 知乎 (zhihu.com)
研究意义
•
创建了首个大规模高清人脸数据集CelebA-HQ数据集,使得高清人脸生成的研究成为可能
•
首次生成了1024*1024分辨率的高清图像,确立了GAN在图像生成领域的绝对优势,大大加速了图像生成从实验室走向实际应用
•
从低分辨率逐次提升的策略缩短了训练所需的时间,训练速度提升2-6倍
渐进式训练
•
生成器和判别器层数由浅到深,不断增长,生成图像的分辨率从4*4开始逐渐变大
•
生成器和判别器的增长保持同步,始终互为镜像结构
•
当前所有被添加进网络的层都是可训练的
•
新的层是平滑的添加进来,以防止对现有网络照成冲击
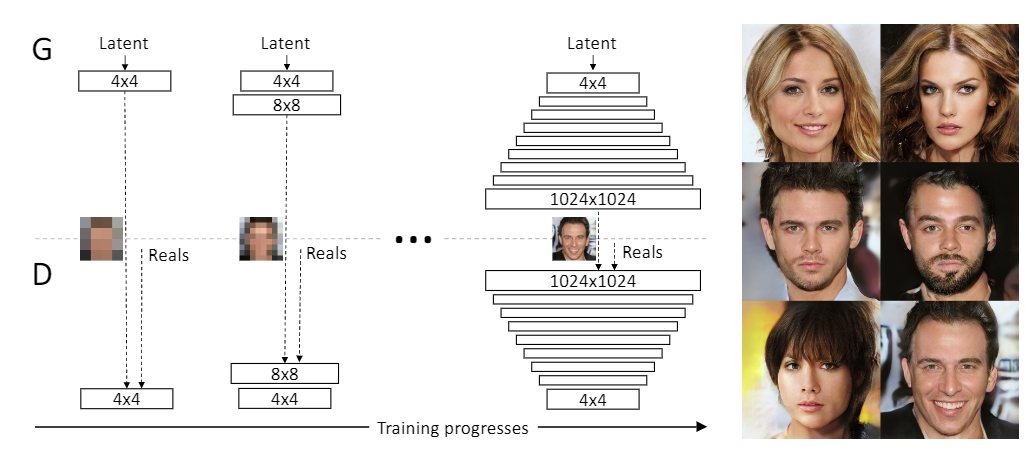
•
新增加一个层时为过渡期,通过加权系数ɑ对上一层和当前层的输出进行加权
•
ɑ从 0 线性增长到 1
•
在过渡期,判别器对真实图像和生成图像同样都进行ɑ加权
•
生成器中的上采样使用最近邻Resize,判别器中的下采样使用平均池化
•
toRGB和fromRGB使用1*1卷积
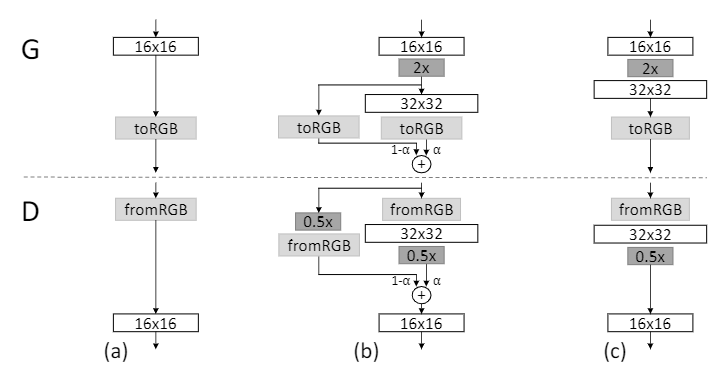
Figure 2: When doubling the resolution of the generator (G) and discriminator (D) we fade in the new layers smoothly. This example illustrates the transition from 16 × 16 images (a) to 32 × 32images ©. During the transition (b) we treat the layers that operate on the higher resolution like a residual block, whose weight α increases linearly from 0 to 1. Here 2× and 0.5× refer to doubling and halving the image resolution using nearest neighbor filtering and average pooling, respectively. The toRGB represents a layer that projects feature vectors to RGB colors and fromRGB does the reverse; both use 1 × 1 convolutions. When training the discriminator, we feed in real images that are downscaled to match the current resolution of the network. During a resolution transition, we interpolate between two resolutions of the real images, similarly to how the generator output combines two resolutions.
•
渐近式增长使训练更加稳定
•
为了证明渐进式增长与loss设计是正交的,论文中分别尝试了WGAN-GP和LSGAN两种loss
•
渐进式增长也能减少训练时间,根据输出分辨率的不同,训练速度能提升2-6倍
•
WGAN-GP损失函数,使用gradient penalty策略来代替WGAN中的weight clipping,以使得判别器继续满足Lipschitz连续条件,同时判别器中无法再使用BN层
Minibatch标准差
•
不需要任何参数或超参数
•
在判别器中,对于每个channel的每个像素点分别计算batch内的标准差并取平均,得到一个代表整体标准差的标量
•
复制这个标准差把它扩展为一个feature map,concat到现有维度上
•
加到判别器的末尾处效果最好
•
其他的一些增加生成多样性的方法,可以比这个方法效果更好,或者与此方法正交
均衡学习率
Equalized learning rate
•
使用标准正态分布来初始化权重,然后在运行阶段对权重进行缩放,缩放系数使用He初始化中求得的标准差
•
之所以进行动态的缩放,而不是直接使用He初始化,与当前流行的自适应随机梯度下降方法(比如Adam)中的尺度不变性相关
•
自适应随机梯度下降方法,会对频繁变化的参数以更小的步长进行更新,而稀疏的参数以更大的步长进行更新;比如在使用Adam时,如果某些参数的变化范围(标准差)比较大,那么它会被设置一个较小的学习速率
•
通过这样的动态缩放权重,在使用自适应随机梯度下降方法时,就可以确保所有权重的变化范围和学习速率都相同
生成器中的像素归一化
Pixelwise normalization
•
希望能控制网络中的信号幅度
•
在生成器的每一个卷积层之后,对feature中每个像素在channel上归一化到单位长度
•
使用“局部响应归一化”的变体来实现
•
这样一个非常严格的限制,不过却并没有让生成器的性能受到损失
•
对于大多数数据集来说,使用像素归一化后结果没有太大变化,但可以在网络的信号强度过大时进行有效抑制
评价指标
Evaluation method
•
MS-SSIM能发现GAN大尺度的模式崩溃,但对细节上颜色、纹理的多样性不敏感,并且也不能直接用来评估两个图像数据集的相似性
•
作者认为,一个成功的生成器,它生成的图像在任意尺度上,与训练集应该都有着良好的局部结构相似性
•
基于此设计了一种基于多尺度统计相似性的评价方法,来比较两个数据集的局部图像块之间的分布
•
随机选取了16384张图片,使用拉普拉斯金字塔抽取图像块,来进行图像的多尺度表达,尺寸从16*16开始,每次增大一倍一直到原始大小
•
每个分辨率尺度上挑选128个描述子
•
每个描述子是一个7x7x3的像素块,3为颜色通道数
•
总共有16384128=2.1M个大小为773=147的描述子
•
对每个描述子,在各个颜色channel上进行均值和标准差的归一化
•
使用 sliced Wasserstein distance (SWD) 来计算两组图像间各个描述子的距离
•
SWD是一种对Wasserstein distance(推土机距离)的近似,因为两个高维分布间的WD不方便计算
•
比较小的SWD,表示两个图像数据集间的图像外观和整体方差都比较接近
•
对不同分辨率的SWD来说,1616上的SWD代表大尺度上图像结构的相似性,而原始分辨率上的SWD则代表像素级的差异,比如噪声和边缘的锐度
消融实验
Ablation experiment
•
生成图像的分辨率为128x128,使用轻量级网络,在训练量达到10M时停止,网络还没有完全收敛
•
MS-SSIM的评价使用了10000张生成图像
•
一开始 batch size设为 64,之后改为 16
•
最终版本使用了更大的网络和更长时间的训练使得网络收敛,其生成效果至少可以与SOA相比较
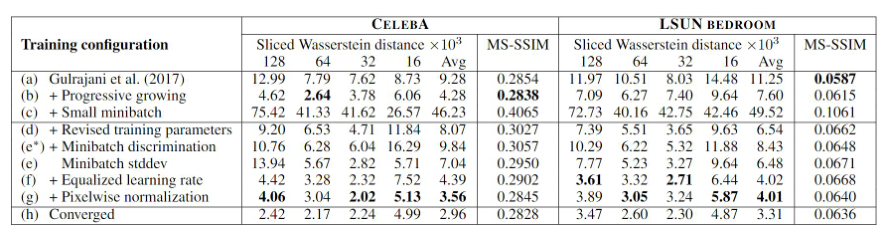
•
使用渐进式训练一方面可以提升生成质量,一方面可以减少训练的总时间
•
可以把渐进式的网络加深看做是一种隐式的课程学习,从而来理解生成质量的提升
实验结果
CELEBA-HQ
•
CELEBA数据集有202599张图像,分辨率从 43x55 到 6732x8984,不同图像质量差别很大
•
使用一个预训练的卷积自编码器来进行去除JPEG噪声
•
使用一个预训练的4倍超分辨率GAN来提升图像分辨率
•
基于CelebA中已有的脸部关键点标注,来进行人脸的截取和旋转矫正
•
处理了所有的CelebA图像,然后使用基于频谱的质量评价方式,选出最好的30000张生成图像
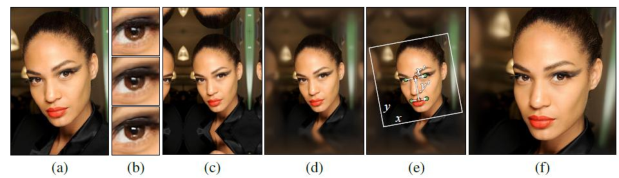
• 使用8个Tesla V100 GPU 并行训练了4天,此时SWD结果不再变化
• 根据当前的训练分辨率,使用自适应的batch size,来最大效率的使用显存
• 为了证明作者的改进与loss很大程度上是相互独立的,分别尝试了LSGAN和WGAN-GP两种 loss,LSGAN更不稳定但也能得到高清的生成图像
• 除了展示生成结果外,作者还进行了latent space的插值,和渐进式训练的可视化
• 插值方式是:随机生成一系列latent code,然后对他们使用时域的高斯模糊,最后把各latent code归一化到一个超球面上

论文总结
优点
•
ProGAN相比于更早的GAN网络,生成的质量普遍都很高
•
ProGAN在生成高分辨率的图像时也能够进行稳定的训练
•
目前的生成效果已经快令人信服了,特别是在CELEBA-HQ
数据集上
不足
•
离真正照片级的生成仍有很长一段距离
•
目前的生成还做不到对图像语义和约束的理解
•
他们使用时域的高斯模糊,最后把各latent code归一化到一个超球面上
[外链图片转存中…(img-87HHjwYf-1664845828841)]
论文总结
优点
•
ProGAN相比于更早的GAN网络,生成的质量普遍都很高
•
ProGAN在生成高分辨率的图像时也能够进行稳定的训练
•
目前的生成效果已经快令人信服了,特别是在CELEBA-HQ
数据集上
不足
•
离真正照片级的生成仍有很长一段距离
•
目前的生成还做不到对图像语义和约束的理解
•
生成图片的细微结构也还有改进的空间


















 686
686

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











