







编辑:Happy
首发:AIWalker

paper:https://arxiv.org/abs/2103.11784
code:https://github.com/czczup/URST
本文是南京大学&港中文的路通&罗平等人在风格迁移领域的一次突破性探索,提出了首个可以进行超高分辨率(比如10000x10000大小)图像风格迁移的方案URST。针对现有风格迁移模型在图像块处理时存在的块间不一致问题,提出了一种新颖的“Thumbnail Instance Normalization”;与此同时,针对高分辨率图像风格迁移存在的“small stroke size”问题,提出了一种新颖的辅助损失。所提方案可以轻易与现有风格迁移网络组合并取得性能提升。
Abstract
本文提出一种非常简单的极限分辨率的风格迁移框架URST,首个可以处理任意高分辨率(比如
10000
×
10000
10000\times 10000
10000×10000)图像的进行风格迁移的方案。当处理超高分辨率图像时,受限于较大的内存占用与small stroke size问题,现有风格迁移方法往往难以真正应用。
URST通过以下两种策略避免了超高分辨率图像导致的内存问题:(1) 将图像划分成小的图像块进行处理;(2)提出一种新颖的Thumbnail Instance Normalization (TIN)进行块级风格迁移。具体来说,TIN可以提取缩略图的规范化统计信息并应用到小图像块上,确保了不同块之间的风格一致性。
总而言之,相比已有方案,本文所提URST具有这样几个优点:
- 通过将图像拆分为小块并采用TIN成功的对任意高分辨图像进行风格迁移;
- 受益于所提感知损失,所提方法在超高分辨率图像上取得了超过其他SOTA方案的效果;
- 所提URST可以轻易的嵌入到现有风格迁移方案中,无需进行训练即可提升其性能。
Introduction
超高分辨率图像风格迁移存在两个关键性挑战:
- 超高分辨图像需要非常大的内存占用,甚至超出现有GPU的最大显存;
- 过小的笔画描边会导致不自然的纹理。
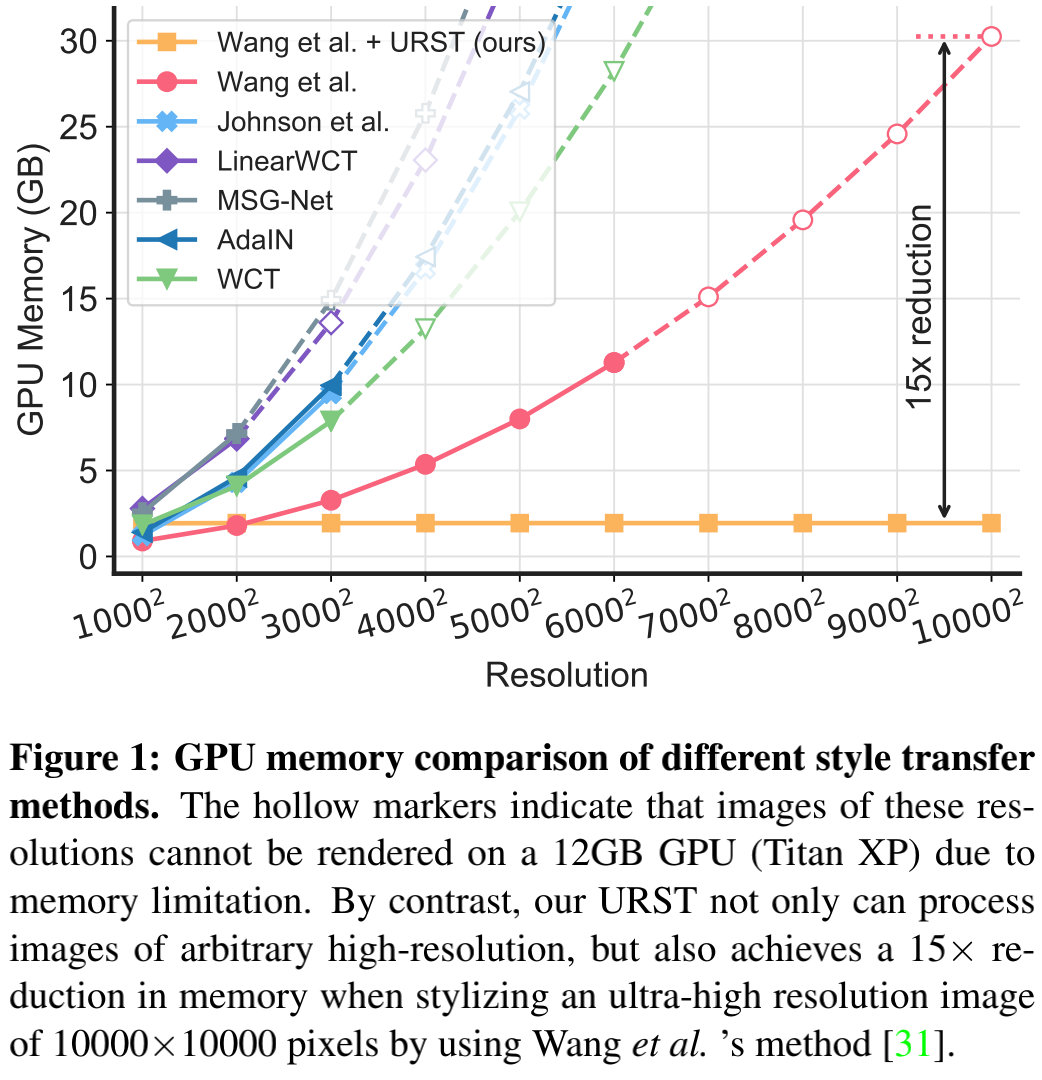
针对第一个问题,现有方法往往采用轻量型网络、模型剪枝、知识蒸馏等方法降低显存占用。然而这些方法仅仅能起到缓和的作用,以上图为例,随着分辨率的提升,显存的占用呈指数增长,很快超出了现有GPU的峰值。这就驱动我们设计一种更有效的策略用于超高分辨率图像的风格迁移。

超高分辨率图像的笔画边缘过小会呈现出不自然的现象,可参考上图(b)。增大笔画边缘是一种广泛采用的解决上述问题的方法;此外扩大风格迁移网络的感受野是另一种解决方案。然而这些方法并不适用于超高分辨率风格迁移。
为解决上述问题,本文提出了URST用于对任意高分辨率图像在有限内存约束下进行风格迁移,效果可参考上图(d)。
Method
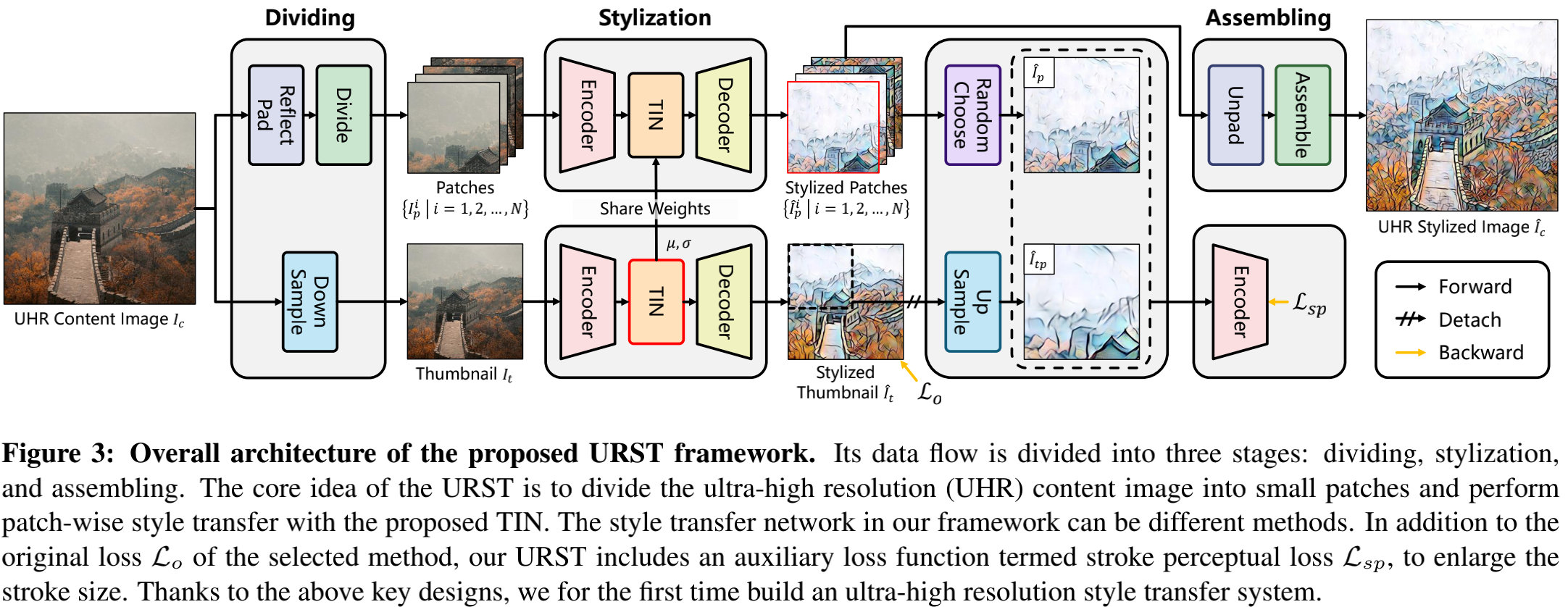
上图给出了本文所提URST的整体框架示意图。所提方案包含三个关键设计思想:
- 一种灵活的块级风格迁移,它可以将高计算量的风格迁移任务拆分为多个地计算量的块级风格迁移;
- 提出一种新颖的缩略图实例规范化TIN,它可以提取缩略图规范化统计信息并将其应用到小图像块上以确保不同块间的风格一致性;
- 精心设计了一种笔画感知损失以聚焦于笔画边缘的感知差异,促使风格迁移网络生成大的笔画边缘。
受益于上述特性,本文所提URST可以轻易嵌入到现有风格迁移方案中并进行超高分辨率风格迁移。所提URST以高分辨率图像 I c I_c Ic作为输入,URST的数据流包含三个阶段:
- dividing stage:我们首先对每个内容图像生成缩略图 I t I_t It,然后将内容图像拆分为多个小的图像块 { I p i ∣ i = 1 , 2 , ⋯ , N } \{I_p^i | i=1,2,\cdots,N\} {Ipi∣i=1,2,⋯,N};
- stylization stage: 缩略图 I t I_t It首先被送入到风格迁移网络以收集规范化统计信息;然后这些统计信息被用于对小图像块进行风格化并得到风格化图像块 { I ^ p i ∣ i = 1 , 2 , ⋯ , N } \{\hat{I}_p^i | i=1,2,\cdots,N\} {I^pi∣i=1,2,⋯,N};
- assembling stage: 所有的风格化图像块集成得到一个超高分辨率风格图像 I ^ c \hat{I}_c I^c。
由于该方案中的风格迁移网络可以是任意方法(比如AdaIN、LinearWCT),为方便起见,我们定义所选择方法原始损失为 L 0 \mathcal{L}_0 L0,在训练过程中,我们首先采用原始损失基于缩略图优化风格迁移网络。
除了原始损失外,该URST还引入了一种辅助损失函数,称之为笔画感知损失(stroke perceptual loss),用于进一步改善超高分辨率风格迁移的质量。该损失的核心在于:对风格块 I ^ p \hat{I}_p I^p与上采样块 I ^ t p \hat{I}_{tp} I^tp之间的笔画边缘进行感知差异惩罚。
Patch-wise Style Transfer
为处理超高分辨率图像,我们提出了块级风格迁移。给定超高分辨率内容图像 I c I_c Ic,我们采用 K × K K\times K K×K滑动窗口按照stride=S将其拆分为重叠块 { I p i ∣ i = 1 , 2 , ⋯ N } \{I_p^i | i=1,2,\cdots N\} {Ipi∣i=1,2,⋯N}。考虑到GPU的内存限制,这些图像块将以batch方式逐步送入到网络中。在完成所有快处理后,我们再将所有块合并为超高分辨率图像 I ^ c \hat{I}_c I^c。
相比已有方法采用完整图像作为输入,所提框架可以灵活的处理任意高分辨率图像,同时也可以轻易嵌入到现有风格迁移方法(比如AdaIN、WCT、LinearWCT)中。正如前面所提到的,由于不同块的统计特性独立性,不同图像块的风格化可能存在不一致性问题。
Thumbnail Instance Normalization
IN是风格迁移领域常用的一种规范化层,给定输入
x
∈
R
N
×
C
×
H
×
W
x\in R^{N \times C \times H \times W}
x∈RN×C×H×W,IN描述如下:
I
N
(
x
)
=
γ
(
x
−
μ
(
x
)
σ
(
x
)
)
+
β
IN(x) = \gamma(\frac{x - \mu(x)}{\sigma(x)}) + \beta
IN(x)=γ(σ(x)x−μ(x))+β
然而,我们发现IN并不适用于块级风格迁移,会导致块间风格不一致问题,可参考下图。

在上图(a)中,我们对输入作为整体进行规范化;在上图(b)中我们将输入拆分为四块分贝进行规范化。这就导致最终的结果存在风格不一致问题。
基于上述分析,我们提出一种简单的IN变种,称之为TIN。该以块
x
∈
R
N
×
C
×
H
×
W
x\in R^{N \times C \times H \times W}
x∈RN×C×H×W和缩略图
t
∈
R
N
×
C
×
H
t
×
W
t
t \in R^{N \times C \times H_t \times W_t}
t∈RN×C×Ht×Wt作为输入,通过如下方式进行处理:
T
I
N
(
x
,
t
)
=
γ
(
x
−
μ
(
t
)
σ
(
t
)
)
+
β
TIN(x,t) = \gamma (\frac{x-\mu(t)}{\sigma(t)}) + \beta
TIN(x,t)=γ(σ(t)x−μ(t))+β
通过这种方式,TIN可以确保不同块间的风格一致性间,上图©。
Stroke Perceptual Loss
所提方法驱动我们提出一种辅助损失增大笔画边缘,该损失定义如下:
L
s
p
(
I
^
p
,
I
^
t
p
)
=
∥
F
l
(
I
p
^
)
−
F
l
(
I
^
t
p
)
∥
2
\mathcal{L}_{sp}(\hat{I}_p, \hat{I}_{tp}) = \| \mathcal{F}_l(\hat{I_p}) - \mathcal{F}_l(\hat{I}_{tp}) \|^2
Lsp(I^p,I^tp)=∥Fl(Ip^)−Fl(I^tp)∥2
注:
F
l
\mathcal{F}_l
Fl表示VGG第l层的输出特征。因此,整体损失函数定义如下:
L
=
L
o
+
λ
L
s
p
\mathcal{L} = \mathcal{L}_o + \lambda \mathcal{L}_{sp}
L=Lo+λLsp
Experiments
为验证所提方法的有效性,我们将其与AdaIN、WCT等方法进行了对比,见下图。

从上图可以看到:(1) IN导致了明显的块间风格不一致问题;(2) 所提方法取得了与全图相似的效果且显存占用更低。

与此同时,我们还对比了所提损失函数的影响分析,见上图。可以看到:基于所提损失引导,这些模型可以生成更粗的线条与更稀疏的纹理,这有助于改善超高分辨率风格迁移。
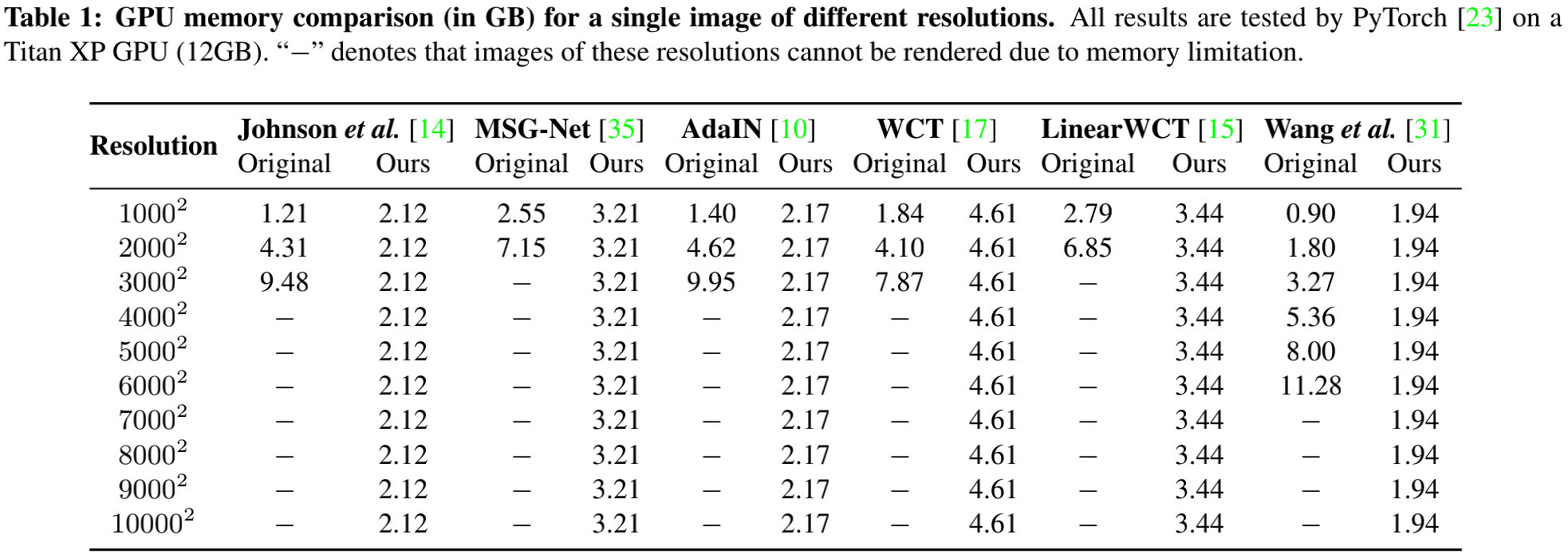
此外,我们还提供了不同风格迁移方案在不同输入分辨率输入时的显存占用对比。可以看到:大多方法甚至不能处理 4000 × 4000 4000\times 4000 4000×4000的高分辨率图像;而本文拖死方法甚至可以处理 10000 × 10000 10000\times 10000 10000×10000分辨率图像且显存占用不超过5GB。理论上,本文所提方法可以处理任意高分辨率图像。
最后,我们提供一个 12000 × 8000 12000\times 8000 12000×8000超高分辨率图像风格迁移效果图作为结尾。

推荐阅读
- 你的感知损失可能用错了,沈春华团队提出随机权值广义感知损失
- CVPR2021|超分性能不变,计算量降低50%,董超等人提出用于low-level加速的ClassSR
- SANet|融合空域与通道注意力,南京大学提出置换注意力机制
- GhostSR|针对图像超分的特征冗余,华为诺亚&北大联合提出GhostSR
- 图像超分中的那些知识蒸馏
- ICLR2021 | 显著提升小模型性能,亚利桑那州立大学&微软联合提出SEED
- RepVGG|让你的ConVNet一卷到底,plain网络首次超过80%top1精度
- Transformer再下一城!low-level多个任务榜首被占领
- 通道注意力新突破!从频域角度出发,浙大提出FcaNet
- 无需额外数据、Tricks、架构调整,CMU开源首个将ResNet50精度提升至80%+新方法
- 46FPS+1080Px2超分+手机NPU,arm提出一种基于重参数化思想的超高效图像超分方案
- 动态卷积超进化!通道融合替换注意力,减少75%参数量且性能显著提升 ICLR 2021



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











