







本文首发:AIWalker
欢迎关注AIWalker,近距离接触底层视觉与基础AI

https://arxiv.org/abs/2401.17270
https://github.com/AILab-CVC/YOLO-World
https://github.com/ultralytics/ultralytics
https://www.yoloworld.cc/
YOLO-World亮点
- YOLO-World是下一代YOLO检测器,旨在实时开放词汇对象检测。
- YOLO-World在大规模视觉语言数据集上进行了预训练,包括Objects 365,GQA,Flickr 30 K和CC 3 M,这使得YOLO-World具有强大的zero-shot开集Capbility与Grounding能力。
- YOLO-World实现了快速的推理速度;可以对用户给定词汇,所提重新参数化技术进一步加速推理和部署;
YOLO-World方案
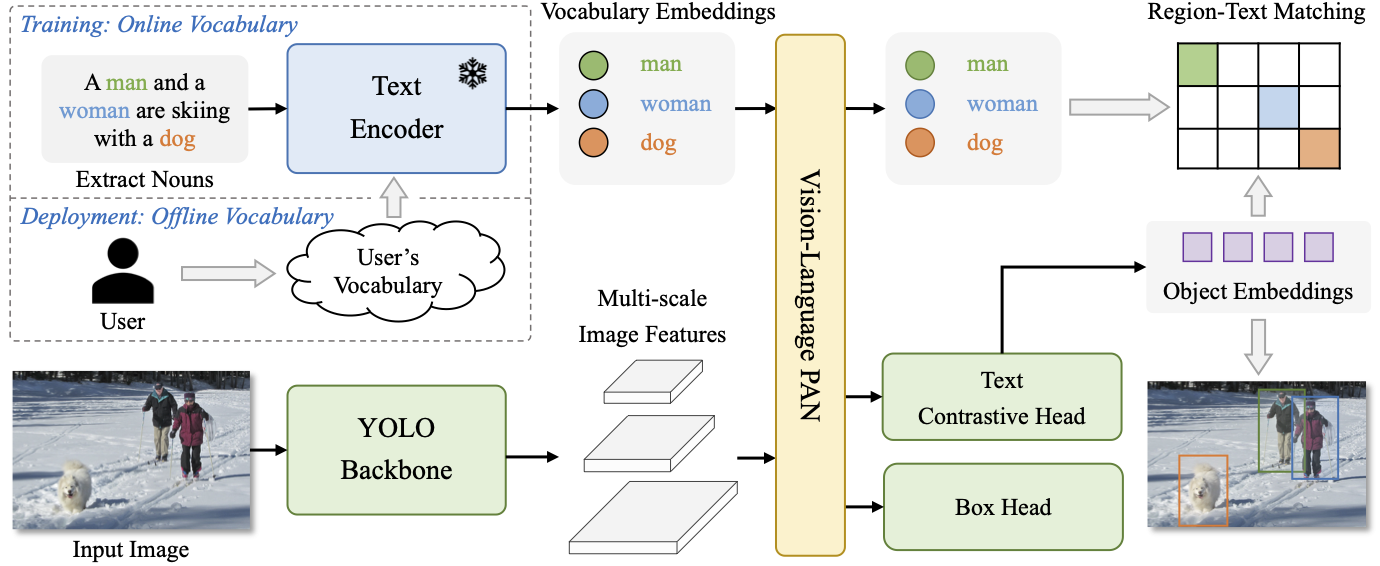
上图为YOLO-World整体架构示意图,它包含一个YOLO检测器、一个文本编码器以及RepVL-PAN。文本编码器首先将输入文本编码为文本嵌入信息;图像编码器对基于输入图像提取多尺度特征信息;RepVL-PAN通过跨模态融合增强文本与图像表征。
- YOLO Detector:编码器基于YOLOv8演变而来,YOLOv8由DarkNet骨干、PAN多尺度特征融合以及检测头构成;
- Text Encoder:采用CLIP预训练文本编码器对输入文本T提取对应的文本嵌入 W = TextEncoder ( T ) ∈ R C × D W = \text{TextEncoder}(T) \in \mathbb{R}^{C \times D} W=TextEncoder(T)∈RC×D,这里C表示名词数目,D表示嵌入维度。相比于Text语言编码器,CLIP文本编码器可以提供更好的视觉-语义能力。当输入文本是句子时,我们采用n-gram
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2520
2520

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











