







编辑:Happy
首发:AIWalker

本文是南开大学程明明与南洋理工大学Chen ChangeLoy等人关于深度学习时代的低光图像增强的综述。本文从低光图像增强的数据集、网络架构、损失函数、学习机制等不同角度对其进行了系统性的总数;为评估不同方法的泛化性与鲁棒性还提出了一个大尺度低光图像数据集;与此同时,针对低光图像增强存在的挑战以及未来有研究价值的方向进行了探讨。强烈推荐给各位low-level领域的同学!
Abstract
低光图像增强(Low-light image enhancement, LLIE)旨在提升低光环境下所采集图像的感知质量。该领域的近期进展主要由深度学习方法(包含不同学习策略、网络架构、损失函数、训练数据等)主导。本文进行了系统性综述以覆盖更多角度的理解,涵盖算法以及未解决问题。
为最大化验证现有方法的泛化性能,我们提出了一个大尺度低光图像与视频数据,这些图像/视频采用不同的收集在不同亮度条件下拍摄所得。除此之外,我们首次提供了一个包含多种主流LLIE方法的在线平台,它可以通过用户友好的交互方式重现不同方法的效果。除了在公开数据与本文所提数据上验证所提方法定量与定性性能,我们还验证了他们对于低光人脸检测的性能。
该综述、所提出的数据集以及在线平台可以作为进一步研究的参考资源,并促进该领域的进一步发展。所提平台与所收集的算法、数据集、评估准则等等均已公开到github,链接如下:
https://github.com/Li-Chongyi/Lighting-the-Darkness-in-the-Deep-Learning-Era-Open
本文主要有以下几个方面的特性:
- 本文首个系统而全面的对基于深度学习的LLIE方法进行了综述;
- 本文提出一个包含不同收集在不同亮度条件下锁舌的大尺度低光图像/视频数据集并用于评估现有方法的泛化性能;
- 本文提供了一个包含多种主流LLE方法的在线平台,它可以让用户以更友好交互方式重现不同方法的效果。
Technical Review and Discussion
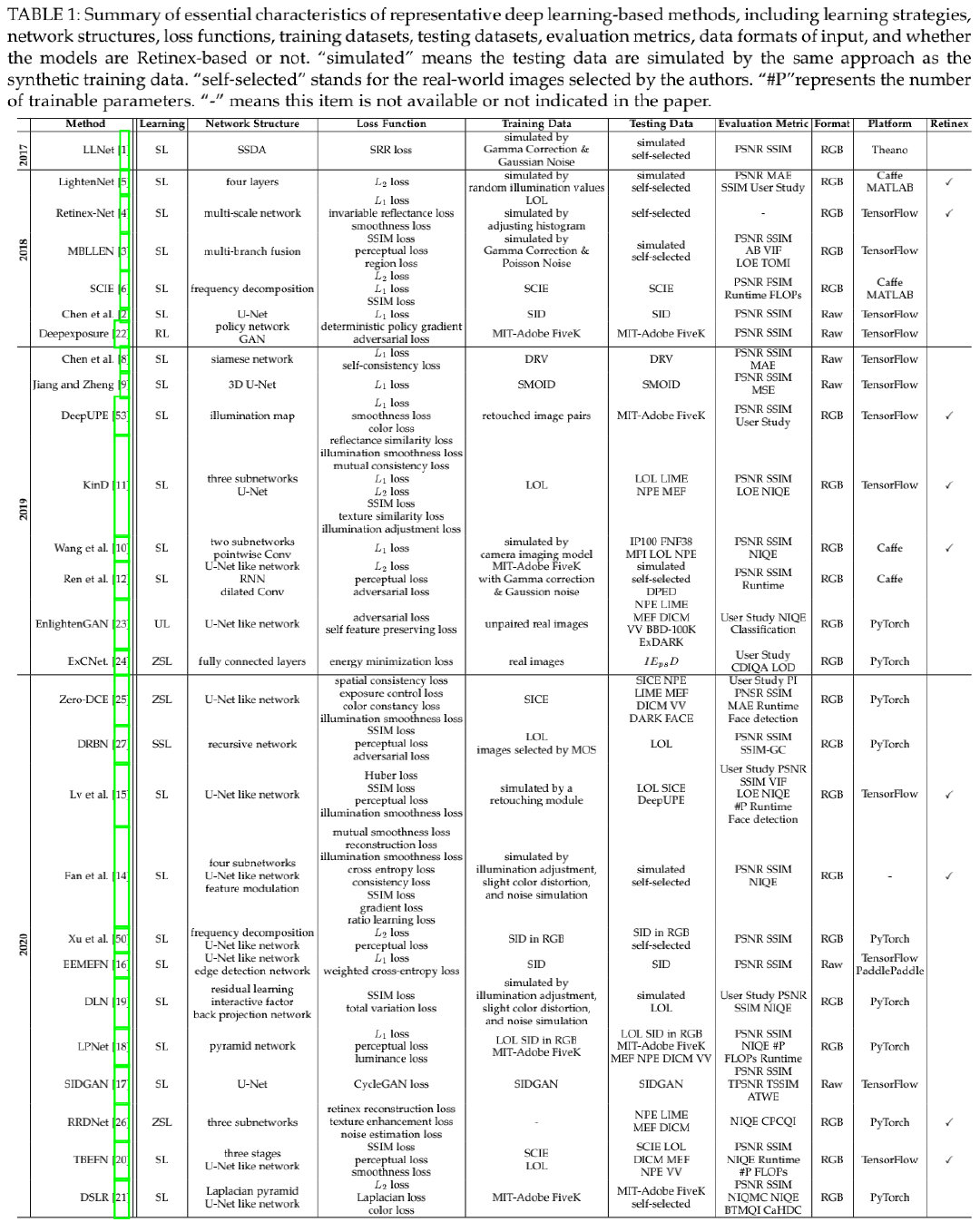
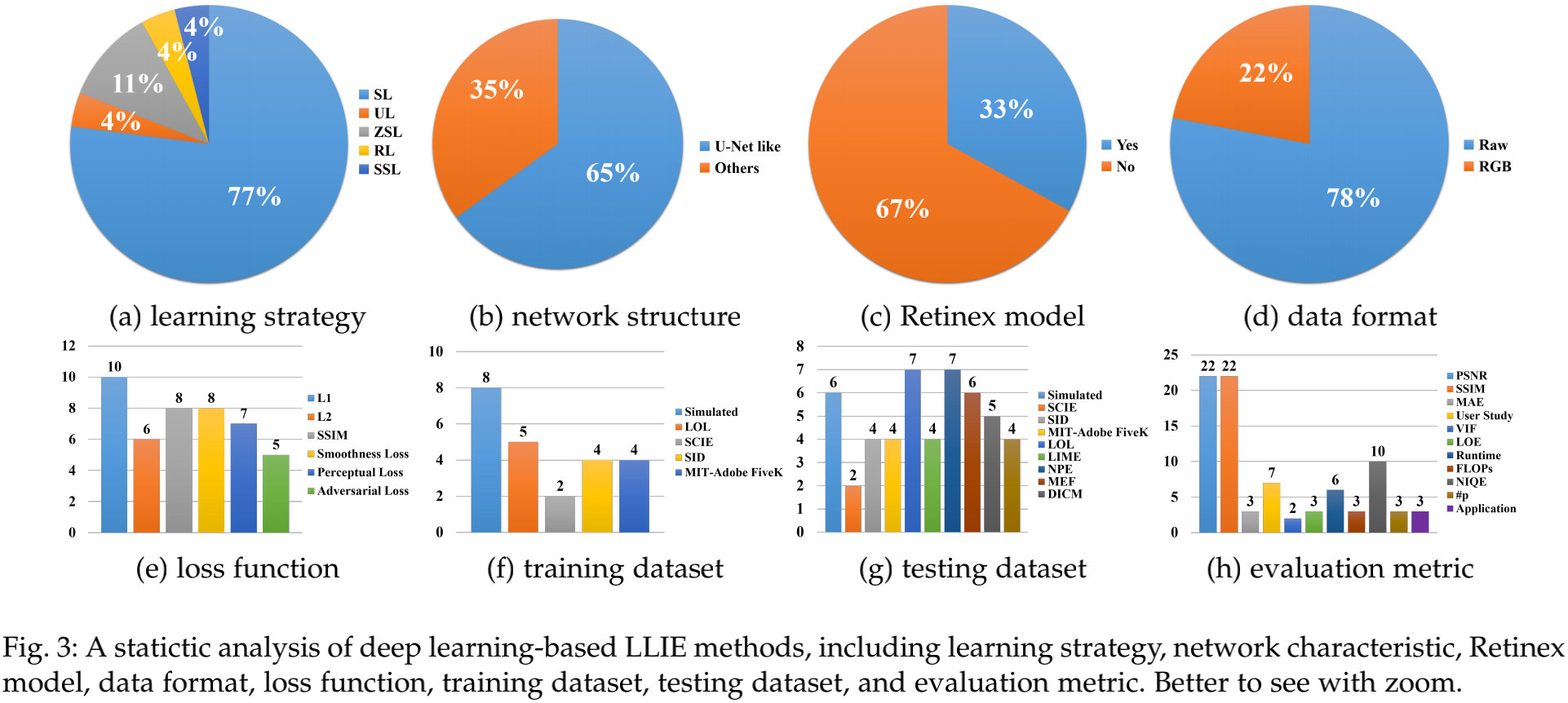
上表给出了最近几年主流的基于深度学习的LLIE方案,并从不同角度对其进行了划分。下图从不同角度对这些方法进行了划分,并列出了所占比例。接下来,我们将不同角度对LLIE方法进行了说明。
Network Structure
从Fig3-b可以看来,UNet及类UNet架构占据LLIE的65%。这是因为:UNet可以有效的集成多尺度特征并同时采用低级与高级特征。这种特性对于取得令人满意的地低光增强非常重要。
尽管如此,有这样几个问题可能被当前的LLIE网络结构忽略了:
- 经过多个卷积层处理后,由于比较小的像素值,极低光图像的梯度可能会在梯度反向传统过程中消失,这可能会导致模型性能并影响网络的收敛;
- UNet中的跳过连接可能会引入噪声和冗余特征到最后的结果。如何有效的滤除噪声并同时集成低级与高级特征应该仔细考虑;
- 尽管针对LLIE提出了部分设计和成分,但它们往往是从其他相关low-level中修改而来。在设计网络时,低光图像的特征同样应当考虑在内。
Combination of Deep Model and Retinex Theory
从Fig3-c可以看到:近三分之一的方法采用了深度学习+Retinex组合的方式进行设计,采用不同的子网络估计Retinex的不同成分,并估计亮度以引导网络的学习。尽管这种组合可以在深度学习与Retinex之间进行很好的恶桥接,但可能同时引入各自的弱点到最终的模型:
- Retinex的理想假设可能会影响最终的结果;
- 深度学习的过拟合可能仍存在;
当组合深度学习与Retinex设计网络时,如何从两者中“取其精华去其糟粕”应该慎重考虑。
Data Format
正如Fig3-d所示,Raw数据是大多数据方法的首选。尽管RAW数据会受限于特定的传感器,但其包含更多的色域以及更高的动态范围。因此,基于RAW数据的深度模型可以重建更清晰的细节、高对比度,具有更好的色彩信息,同时降低了噪声和伪影问题。
尽管如此,由于智能手机的便捷采集性,RGB形式的图像也被不少方法采用并作为输入。在未来的研究中,RAW数据到RGB格式的平滑变化将更有助于LLIE的研究。
Loss Function
从Fig3-e可以看到:LLIE常采用的损失函数为L1, L2, SSIM,感知损失,平滑损失等。除此之外,按照不同的需求,颜色损失、曝光损失、对抗损失同样也得到了应用。
Training Datasets
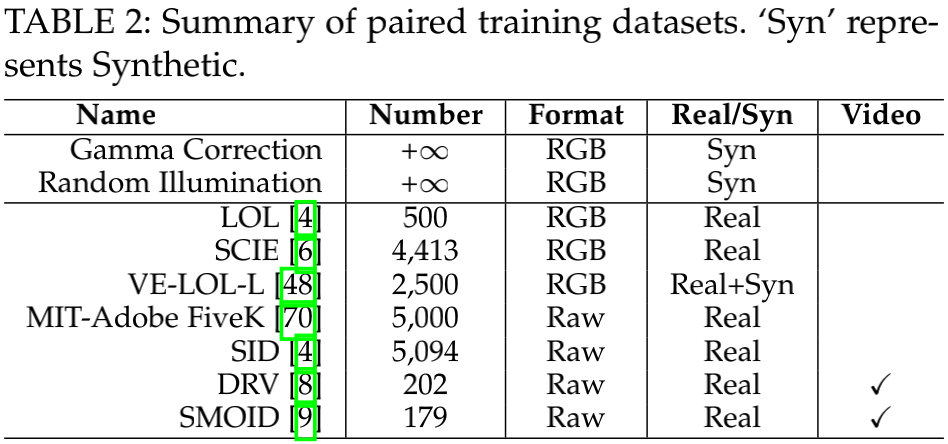
从Fig3-f可以看到:不同的成对训练数据被提出并用于LLIE方案的训练。这些数据包含真实数据与合成数据,相关信息见下表。
Testing Dataset
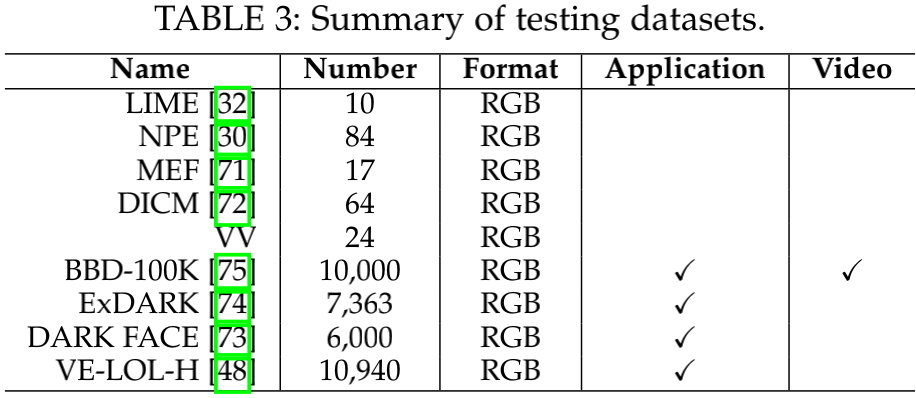
除了上述训练数据集外,还有一些测试数据集,相关信息如下表所示。
Benchmarking and Empirical Analysis
在这部分内容中,我们将对现有基于深度学习的LLIE方法进行分析并突出存在的关键挑战。为方便分析,我们提出了一个大尺度低光图像/视频数据以验证不同深度学习方法的性能。除此之外,我们开发了首个在线平台,它包含多种深度学习LLIE方法,用户能够以更友好的交互方式重建不同方法的效果。本文对比的方法有13中,它们分别是:
- 监督学习方案:LLNet、LightenNet、Retinex-Net、MBLLEN、KinD、KinD++、TBEFN、DSLR;
- 无监督方案:EnlightenGAN;
- 半监督方案:DRBN;
- Zero-shot方案:ExCNet、Zero-DCE、RRDNet。
A New Low-light Image and Video Dataset
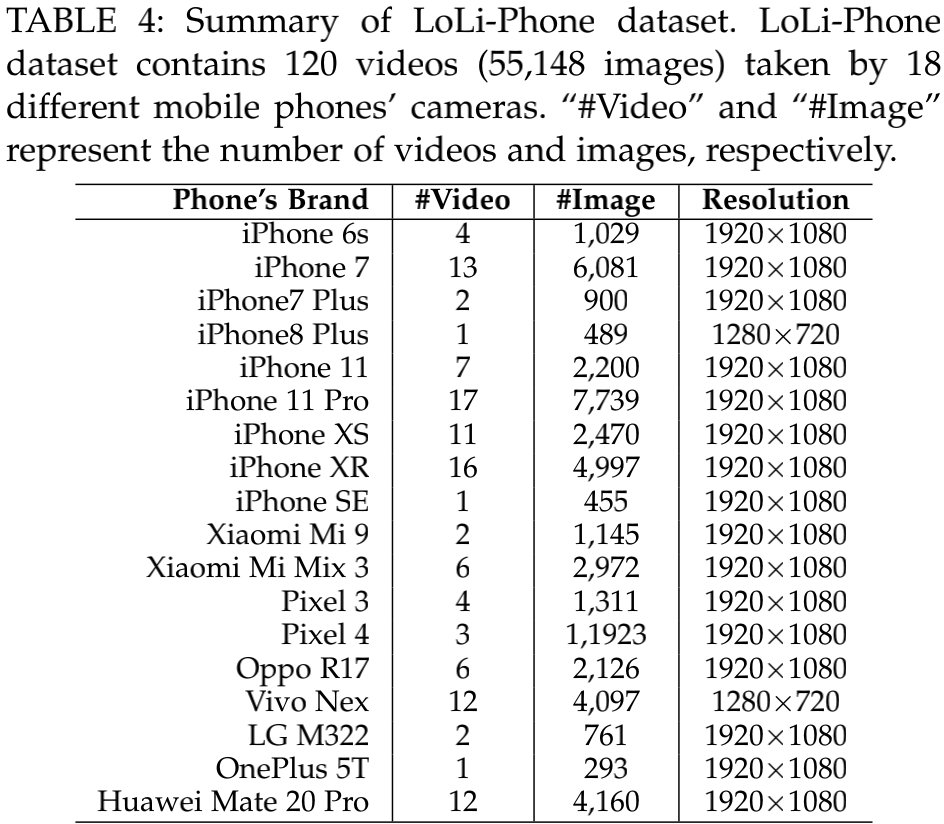
本文提出一个大尺度低光图像/视频数据集LoLi-Phone,以进行不同LLIE方案系统而详细的验证对比。LoLi-Phone是目前为止最大的真实低光图像数据。数据与采集设备信息见下表与下图:

Online Evaluation Platform
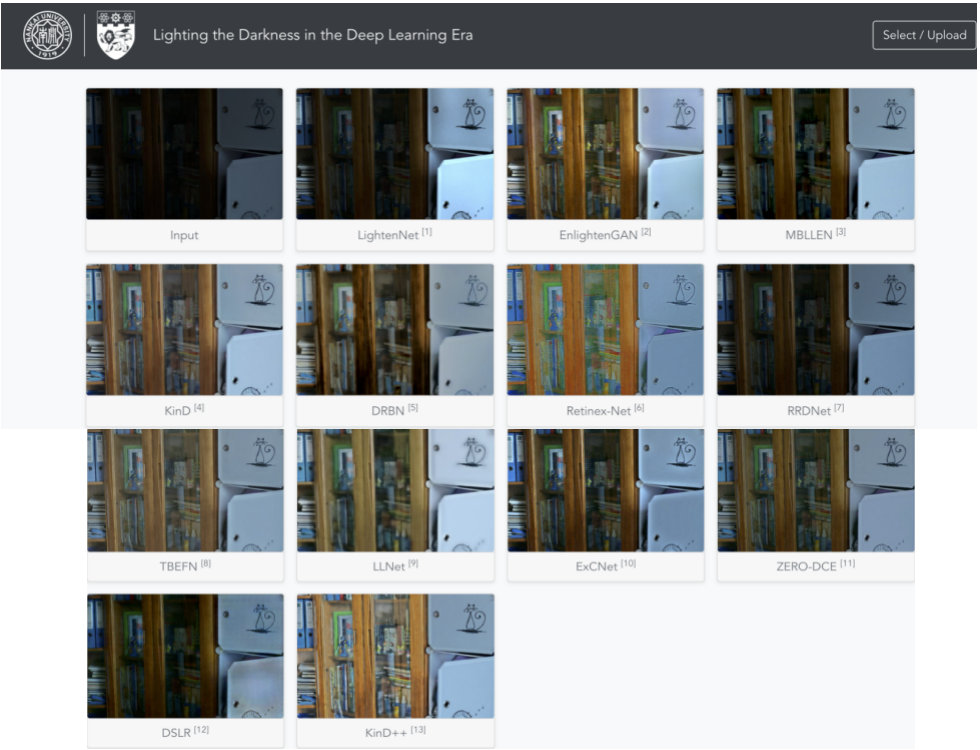
不同方法可能采用不同的深度学习框架,比如Caffe、Theano、TensorFlow以及Pytorch,因此,不同的方法依赖于不同的配置、GPU版本以及硬件信息。这样复杂的需求对于研究员极度不友好,尤其对于出入门者,甚至没有GPU资源的研究员。为缓解该问题,我们开发了在线LLIE平台,称之为LoLi-Platform,链接为:http://mc.nankai.edu.cn/ll/
截止目前,该平台支持13种主流深度学习LLIE方法。其显示截面如下:
Benchmark Results
为更好的定量与定性对比不同的方法,除了LoLi-Phone外,我们还在LOL与MIT-Adboe FiveK数据集上进行了对比。

上图对比了不同方法在LOL与FiveK数据上的效果对比,可以看到:
- 在LOL测试数据集上有以下几点发现:
- 所有方法均提升了输入图像的亮度和对比,但没有一个能成功进行色彩重建;
- LLNet产生了比较的结果;
- LightenNet、RRDNet生成欠曝结果,而MBLLEN、ExCNet则生成过曝结果;
- KinD、KinD++、TBEFN、DSLR、EnlightenGAN、DRBN则引入明显的伪影;
- 在FiveK数据集上有以下几点发现:
- LLNet、KinD++、TBEFN、RRDNet生成了过曝结果;
- Retinex-Net、KinD++、RRDNet生成了伪影,同时又模糊问题。

上图给出了LoLi-Phone数据集上的效果对比,从中可以看到:
- 对于Figure7有以下几点发现:
- 所有方法均无法有效改进亮度并移除噪声;
- Retinex-Net、MBLLEN、DRBN生成了明显伪影;
- 对于Figure8有以下几点发现:
- 所有方法均增强了输入图像的亮度;
- 仅有MBLLEN、RRDNet取得视觉友好的增强效果,且无色片、伪影以及欠/过曝问题。
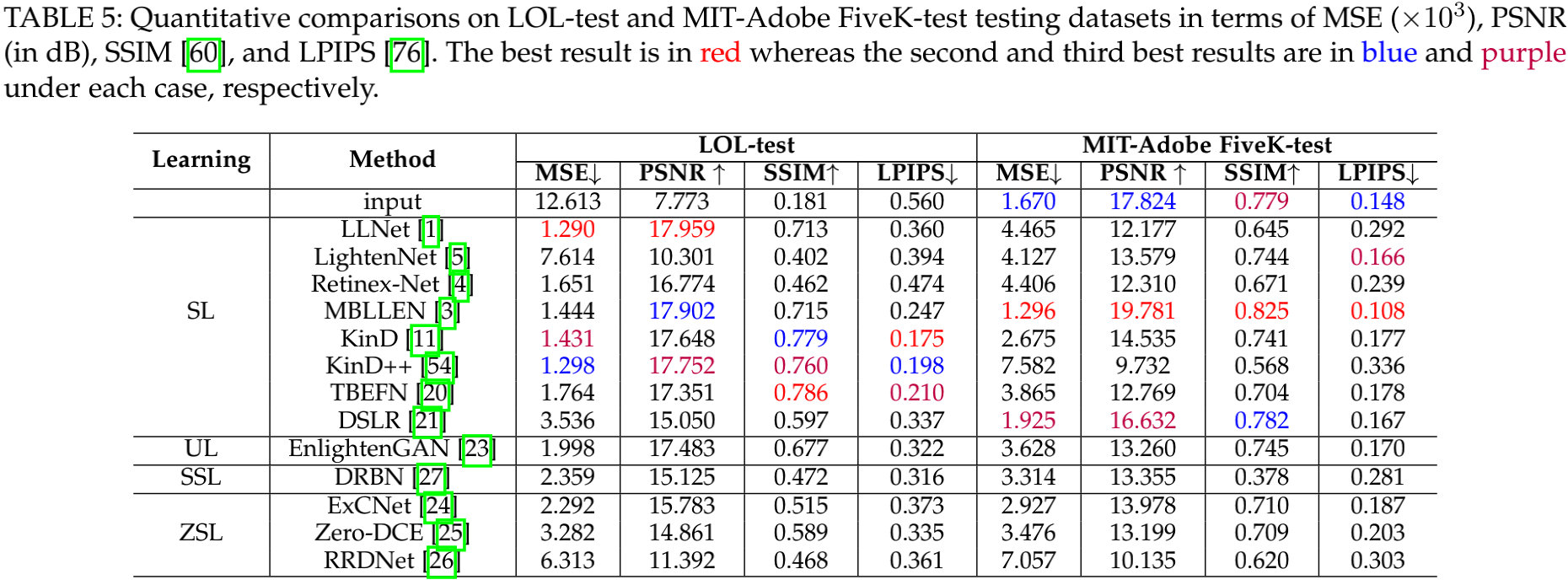
上表给出了不同方法在LOL与FiveK数据上的定量指标对比,可以看到:
- 有监督方案具有更高的指标;
- LLNet在LOL-test数据上取得了最佳MSE与PSNR;
- TBEFN在LOL-test数据上取得了最佳SSIM指标;
- KinD在LOL-test数据上取得了最佳LPIPS指标;
- 对于FiveK-test数据,MBLLEN取得了全面性的指标优先。
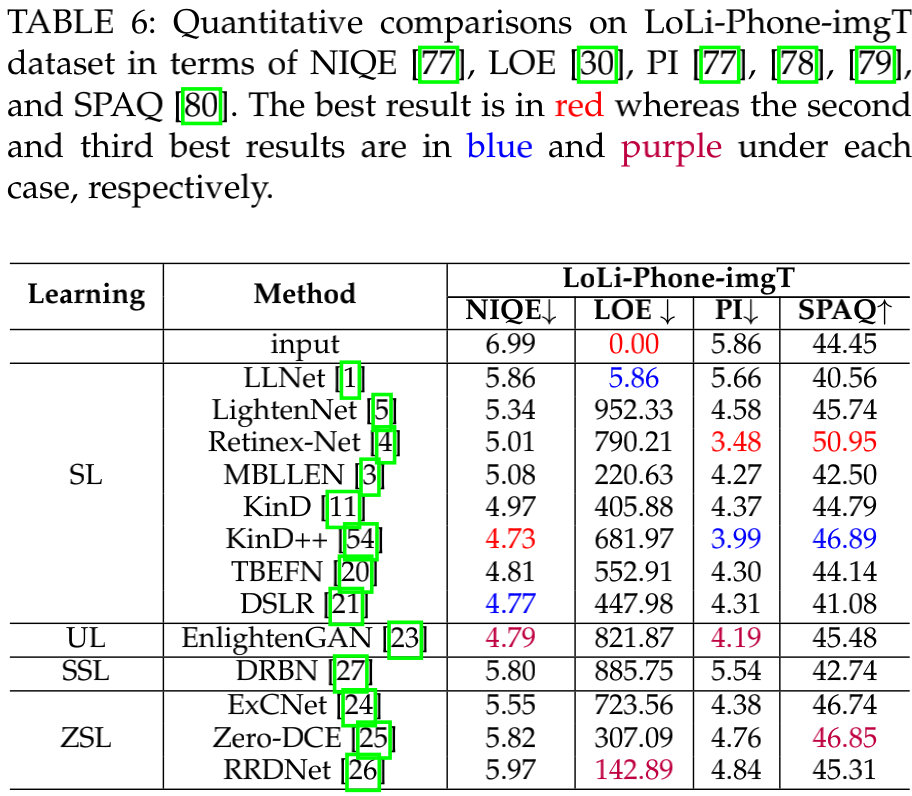
上表对比了不同方法在LoLi-Phone-imgT数据上的指标对比,可以看到:
- Retinex-Net、KinD++、EnlightenGAN具有相对更佳的性能;
- Retinex-Net取得了最佳PI与SPAQ指标,然而从视觉效果上看,它仍存在伪影和色偏问题;
- KinD++取得了最佳NIQE指标。
Computational Complexity
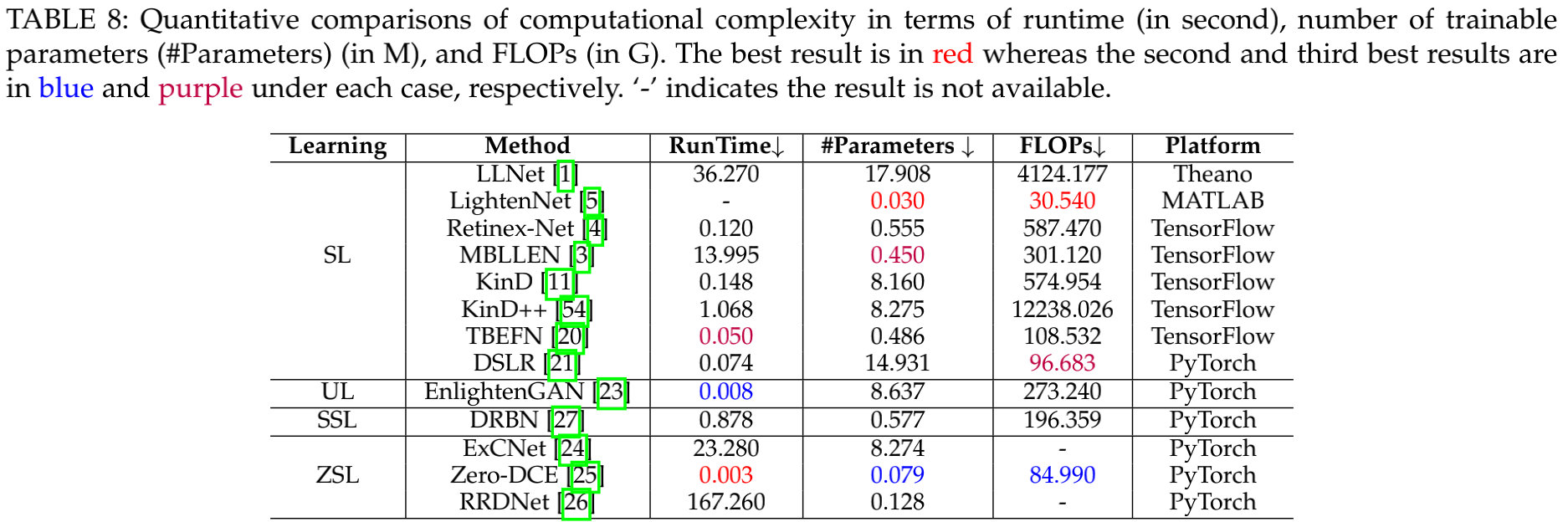
上表对比了不同方法的计算复杂度、参数量以及耗时对比。从中可以看到:
- Zero-DCE具有最快的推理速度;相反,ExCNet与RRDNet具有最长的推理耗时;
- LightenNet具有最少的可学习参数量;相反,LLNet与KinD++的计算量分别高达4124.18G与12238.03G。
Application-based Evaluation
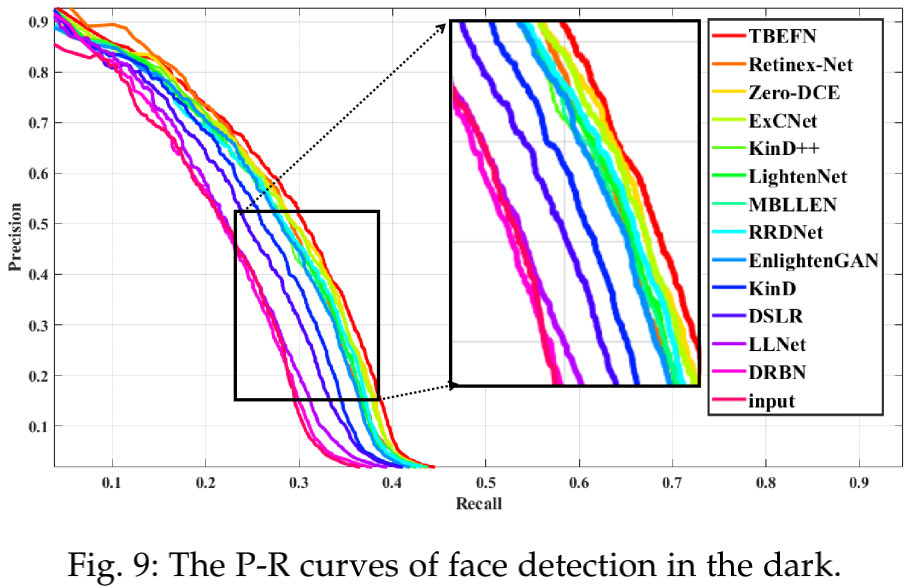
上图与下图给出了任务相关的质量评价与视觉效果对比。可以看到:所有方案均可以改善低光场景下的人脸检测。

Discussion
从上述实验结果,我们可以得到以下几点有意思发现与洞见:
- 在不同测试集、不同评估准则上,不同方法的性能变大非常大。在全参考IQA评估+通用测试数据上,MBLLEN、KinD++、DSLR表象更佳;在真实低光场景,Retinex-Net、KinD++去更好的无参考IQA得分;TBEFN具有更好的时序一致性;当考虑计算效率时,Zero-DCE表现最为突出;从人脸检测角度看,TBEFN、Retinex-Net、Zero-DCE排前三。总而言之,Retinex-Net、Zero-DCE、DSLR最大多数场景的更佳选择。
- 大多数方法在面对LoLi-Phone时出现失败现象,也就是说现有方案的泛化性能需要进一步改善。
- 从学习策略来看,监督学习可以取得更佳性能,但需要高计算资源与成对数据;相反,在真实场景,zero-shot学习更令人期待。
- 在视觉效果与量化IQA指标方面存在明显的gap,也就是说:好的视觉效果并不总是具有好的IQA得分。
- 基于深度学习的LLIE方法有助于低光人脸检测性能提升。
Future Research Directions
尽管LLIE取得极大的进展,但仍有改善的空间。本文从以下几个方面提出了有价值的参考:
- Effective Learning Strategies:当前主流的监督学习方法需要大量的成对训练数据,且可能导致特定数据过拟合问题;Zero-shot学习在真实场景具有更强的鲁棒性,且不需要成对训练数据。这意味着:zero-shot学习是一个极具潜力的研究方向。
- Specialized Network Structures:网络结构可以很大程度影响增强性能,之前的LLIE方案大量的采用了UNet架构,然而这种架构是否适合于LLIE仍有待于考证。局部自相似性、高效算子、NAS技术等思想可以考虑引入到LLIE的网络脚骨设计中,此外
transformer也许会是一个有意思的研究方向。 - Loss Function:损失函数约束了输入与GT之间的相关性并驱动网络的优化。在LLIE中,常用损失函数主要是从其他相关任务中借鉴而来,尚未有针对LLIE而设计的特定损失。更适合LLIE的损失函数设计仍有待于开发。
- Realistic Training Data:尽管已有不少用于LLIE的训练数据,但它们数量、灵活性相对于真实低光比较单一且简单。大尺度的真实LLIE数据收集与生成仍需要进一步研究。
- Standard Testing Data:目前没有一个可以全面接受的LLIE评估基准。研究员倾向于使用自有测试集,这使得所提方法具有一定倾向性。因此,高质量标准低光图像/视频测试集的构建需要进行构建。
- Task-Specific Evaluation Metrics:在某种程度上,常用的度量准则难以很好的反映图像质量。如何评价LLIE增强结果的好坏仍极具挑战,当前IQA要么聚焦于人类视觉感知,要么聚焦机器感知。同时考虑人类视觉感知与机器感知的度量指标有待于开发。
- Robust Generalization Capability:实验结果表明:现有方法在真实场景表现差强人意。这种泛化性能差主要有这样几个因素:合成数据、小尺度训练数据、低效网络结构、不真实的假设、不精确的先验。因此,很有必要探索更好的方式改善LLIE的泛化性能。
- Extension to Low-light Video Enhancement:不同于其他low-level领域视频增强(比如视频去模糊、视频降噪、视频超分)的快速发展,低光视频增强鲜少收到关注。低光图像增强的直接应用会导致不令人满意的结果与抖动问题。因此,如何采用近邻帧有效移除视觉抖动并加速推理值得深入研究。
- Integrating Semantic Information:语义信息对于低光增强非常重要,它将引导网络判别不同区域的增处理。如何有效地将语义信息集成到低光增强是一个有前途的方向。
推荐阅读
- Attention in Attention for Super-Resolution
- CMDSR | 为解决多退化盲图像超分问题,浙江大学&字节跳动提出了具有退化信息提取功能的CMDSR
- CVPR2021|超分性能不变,计算量降低50%,董超等人提出用于low-level加速的ClassSR
- CVPR2021 | 性能不变,计算量减少41%,国防科大提出加速图像超分高效推理的SMSR
- SANet|融合空域与通道注意力,南京大学提出置换注意力机制
- GhostSR|针对图像超分的特征冗余,华为诺亚&北大联合提出GhostSR
- RepVGG|让你的ConVNet一卷到底,plain网络首次超过80%top1精度
- Transformer再下一城!low-level多个任务榜首被占领
- 46FPS+1080Px2超分+手机NPU,arm提出一种基于重参数化思想的超高效图像超分方案
- CVPR2021|将无监督对比学习与超分相结合,国防科大提出了用于盲图像超分的无监督退化表达学习DASR


















 1014
1014

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











