









编辑:Happy
首发:AIWalker
前段时间MLP-Mixer提出后,引发了视觉架构圈的一篇轰动,包含但不限于以下几篇文章:
- “重参数宇宙”再添新成员:RepMLP,清华大学&旷视科技提出将重参数卷积嵌入到全连接层
- 新坑!谷歌提出MLP-Mixer:一种无卷积、无注意力,纯MLP构成的视觉架构
- MLP再添新砖,Facebook入局!ResMLP:完全建立在MLP上的图像分类架构
- CV圈杀疯了!继谷歌之后,清华、牛津等学者又发表三篇MLP相关论文,LeCun也在发声
由此引发了关于“MLP->CNN->Transformer->MLP”怪圈的“恐慌”。今天,港中文李鸿升团队从一个更广义的视角对Transformer、深度卷积以及MLP-Mixer进行了“大一统”,并由此提出Container,该方案在图像分类、目标检测以及实例分割方面取得显著的性能提升。

Abstract
CNN在计算机视觉领域无处不在,并且具有无数有效、高效的改进。近年来,NLP领域中的Transformer已开始在CV领域发力并逐步占领不少CV子领域的高地。尽管早期的用户仍继续采用CNN骨干,但最新的一些网络则逐渐变成了无CNN的Transformer方案。近期另一项令人惊讶的发现表明:不带任何卷积或者Transformer,仅由简简单单的MLP构成的方案可以取得非常有效的视觉表达。
尽管CNN、Transformer以及MLP-Mixer可能会被视作完全独立的架构,我们提供了一个统一视角表明:它们均是更广义方案下通过神经网络集成空间上下文信息的特例。我们提出了CONTAINER(CONText AggregatIon NEtwoRK),一种用于多头上下文集成(Context Aggregation)的广义构建模块,它可以类似Transformer捕获长距离相互作用,同时可以类似局部卷积探索归纳偏置进而导致更快的收敛速度。
仅需22M参数量,所提CONTAINER在ImageNet数据集取得了82.7%的的top1精度,以2.8%优于DeiT-Small;此外仅需200epoch即可达到79.9%的top1精度。不用于难以扩展到下游任务的Transformer方案(因为需要更高分辨率),该方案CONTAINER-LIGHT可以嵌入到DETR、RetinaNet以及Mask-RCNN等架构中用于目标检测、实例分割任务并分别取得了6.6,7.6,6.9指标提升。相比DeiT,在DINO框架(自监督学习)下,所提方法取得了令人非常由前途的结果。
总而言之,本文有以下几点贡献:
- 提出了关于主流视觉架构的一个统一视角;
- 提出了一种新颖的模块CONTAINER,它通过可学习参数和响应的架构混合使用了静态与动态关联矩阵(Affinity Matrix),在图像分类任务中表现出了很强的结果;
- 提出了一种高效&有效的扩展CONTAINER-LIGHT在检测与分割方面取得了显著的性能提升。
Method
首先,我们对神经网络中常用的近邻/上下文集成模块提供了一个广义视角;然后,我们对三个主流架构进行回顾并表明它们是该广义视角下的特例;最后,我们提出了所提CONTAINER及其高效版本CONTAINER-LIGHT。
Contextual Aggregation for Vision
假设输入为
X
∈
R
C
×
H
×
W
X \in R^{C\times H \times W}
X∈RC×H×W,它首先平展为一系列词
{
X
i
R
C
∣
i
=
1
,
c
…
,
N
}
,
N
=
H
W
\{X_i \R^C | i=1,c\dots, N\}, N= HW
{XiRC∣i=1,c…,N},N=HW并送入到网络中。视觉网络通常采用堆叠带残差连接的模块方式,可定义如下:
Y
=
F
(
X
,
{
W
i
}
)
+
X
Y = \mathcal{F}(X, \{W_i\}) + X
Y=F(X,{Wi})+X
我们首先定义关联矩阵
A
∈
R
N
×
N
\mathcal{A} \in R^{N \times N}
A∈RN×N用于表示用于上下文集成的近邻,上述工时可以重写如下:
Y
=
(
A
V
)
W
1
+
X
Y = (\mathcal{A}V)W_1 + X
Y=(AV)W1+X
其中
V
∈
R
N
×
C
V\in R^{N\times C}
V∈RN×C表示X的变换:
V
=
X
W
2
V = XW_2
V=XW2。
W
1
,
W
2
W_1, W_2
W1,W2均为可学习参数。
A
i
,
j
\mathcal{A}_{i,j}
Ai,j表示
X
i
X_i
Xi与
X
i
X_i
Xi之间的关联值。V与关联矩阵相乘则在特征值之间进行的信息流动。这种上下文集成模块(Context Aggregation Block, CAB)的建模能力可以通过引入多个关联矩阵提升,使得网络可以在X之间构建多个上下文关联路径。上式的多头版本定义如下:
Y
=
C
o
n
c
a
t
(
A
1
V
1
,
⋯
,
A
M
1
V
M
)
W
2
+
X
Y = Concat(\mathcal{A}_1V_1, \cdots, \mathcal{A}M1V_M)W_2 + X
Y=Concat(A1V1,⋯,AM1VM)W2+X
A
m
\mathcal{A}_m
Am表示不同头的关联矩阵,不同的关联矩阵可以捕获不同的相关性,进而可以提升上下文集成的表达能力。注:上下文集成过程中仅仅产生了空间信息流动,而未发生跨通道信息交互,同时不存在非线性激活函数。
The Transformer, Depthwise Convolution and MLP-Mixer
Transformer, Depthwise Convolution以及MLP-Mixer是计算机视觉中三个独立的基础模块。接下来,我们将表明:通过定义不同的关联矩阵,它们均可以通过前述上下文集成模块表示。
Transformer 在Transformer的自注意力机制中,关联矩阵通过投影query-key对之间的相似性建模。以带M头为例,m头的关键矩阵
A
m
s
a
\mathcal{A}_m^{sa}
Amsa可以写成如下形式:
A
m
s
a
=
S
o
f
t
m
a
x
(
Q
m
K
m
T
/
C
/
M
)
\mathcal{A}_m^{sa} = Softmax(Q_m K_m^T/\sqrt{C/M})
Amsa=Softmax(QmKmT/C/M)
其中,
K
m
,
Q
m
K_m, Q_m
Km,Qm分别表示m头的key与query。自注意力中的关联矩阵可以动态生成并可以捕获实例级信息。然而,这种表达方式会带来二阶计算复杂度,对于高分辨率特征而言,计算量尤其大。
Depthwise Convolution 卷积操作可以同时进行空域与通道信息集成。这与上述上下文集成模块不同。然而,深度卷积是组卷积的极限特例。考虑到CAB的头数等于通道数C,我们定义如下卷积关联矩阵:
A
m
i
j
c
o
n
v
=
{
K
e
r
[
m
,
0
,
∣
i
−
j
∣
]
,
∣
i
−
j
∣
≤
k
0
,
∣
i
−
j
∣
>
k
\mathcal{A}_{mij}^{conv} = \begin{cases} Ker[m,0,|i-j|], |i-j| \le k \\ 0, |i-j| > k \end{cases}
Amijconv={Ker[m,0,∣i−j∣],∣i−j∣≤k0,∣i−j∣>k
其中,
A
m
i
j
\mathcal{A}_{mij}
Amij表示m头时
X
i
X_i
Xi与
X
j
X_j
Xj之间的关联值。注:不同于自注意力中的关联矩阵随输入动态变化,卷积中的关联矩阵时静态的。
MLP-Mixer 近期新提出的MLP-Mixer不依赖于任何卷积或者自注意力模块,MLP-Mixer的核心为转置MLP操作,它可以表示为:
X
=
X
+
(
V
T
W
M
L
P
)
T
X=X + (V^TW_{MLP})^T
X=X+(VTWMLP)T。对此我们可以定义如下关联矩阵:
A
m
l
p
=
(
W
M
L
P
)
T
\mathcal{A}^{mlp} = (W_{MLP})^T
Amlp=(WMLP)T
其中
W
M
L
P
W_{MLP}
WMLP表示可学习参数。这种简单的工时表明:转置MLP操作本身即视一种上下文集成操作。相比自注意力与深度卷积,转置MLP关联矩阵是静态的、稠密的、参数不共享。
上面简单的统一揭示了Transformer、深度卷积以及MLP-Mixer之间的相似与区别。也就是说,每个模块都可以通过定义不同的关联矩阵而得到。这种发现驱使我们构建一种更强有力、高效的基础模块CONTAINER用于视觉任务。
The CONTAINER Block
正如前面所提到:不同的架构或采用静态,或采用动态关联矩阵进而具有了各自不同的优势。我们所提模块CONTAINER通过可学习参数组合两种两类型的关联矩阵。单头CONTAINER定义如下:
Y
=
(
(
α
A
(
X
)
⏞
Dynamic
+
β
A
⏞
Static
)
V
)
W
2
+
X
Y = ((\alpha \overbrace{\mathcal{A}(X)}^\text{Dynamic} + \beta \overbrace{\mathcal{A}}^\text{Static})V)W_2 + X
Y=((αA(X)
Dynamic+βA
Static)V)W2+X
其中,
A
(
X
)
\mathcal{A}(X)
A(X)表示由X动态生成,而
A
\mathcal{A}
A表示静态关联矩阵。接下来,我们呈现几个关于CONTAINER模块的特例。
- α = 1 , β = 0 , A ( X ) = A s a \alpha = 1, \beta=0,\mathcal{A}(X)=\mathcal{A}^{sa} α=1,β=0,A(X)=Asa:带自注意力的朴素Transformer模块;
- α = 0 , β = 1 , M = C , A = A c o n v \alpha=0, \beta=1, M=C, \mathcal{A} = \mathcal{A}^{conv} α=0,β=1,M=C,A=Aconv:深度卷积模块。在深度卷积中,每个通道具有不同的静态关联矩阵。
- α = 0 , β = 1 , M = 1 , A = A m l p \alpha=0, \beta=1, M=1, \mathcal{A} = \mathcal{A}^{mlp} α=0,β=1,M=1,A=Amlp: MLP-Mixer模块。当 M ≠ 1 M \ne 1 M=1时,我们称之为为MH-MLP:即将通道拆分为M个组,每个组实行不同的MLP以捕获静态关联。
- α = L , β = L , A ( X ) = A s a , A = A m l p \alpha=\mathcal{L}, \beta=\mathcal{L},\mathcal{A}(X) = \mathcal{A}^{sa}, \mathcal{A} = \mathcal{A}^{mlp} α=L,β=L,A(X)=Asa,A=Amlp:该模块同时融合了动态与静态信息,但静态关联集成了MLP-Mixer矩阵。我们称之为CONTAINER-PAM。
- α = L , β = L , A ( X ) = A s a , A = A c o n v \alpha=\mathcal{L}, \beta=\mathcal{L},\mathcal{A}(X) = \mathcal{A}^{sa}, \mathcal{A} = \mathcal{A}^{conv} α=L,β=L,A(X)=Asa,A=Aconv:该模块同时融合了动态与静态信息,但静态关联集成了深度卷积矩阵。该静态关联矩阵包含了平移不变局部约束,使其更适用于视觉任务。此为我们实验中的默认配置。
所提CONTAINER非常容易实现并可以轻易嵌入到现有神经网络中。上述不同版本的CONTAINER会产生不同的架构、不同的性能,并呈现出不同的优势于局限性。因为动态矩阵与静态矩阵可以线性组合,CONTAINER模块的计算复杂度与朴素Transformer相当。
The CONTAINER Network Architecture
在这里,我们将提供实验中的基础架构。前文的统一表达使得我们可以方便与自注意力、深度卷积以及MLP进行对比。
受启发于已有工作,所提架构包含4个阶段。不同于ViT/DeiT的固定分辨率,所提方法采用逐渐降低图像分辨率的方式。逐渐下采样可以保留图像细节,这对于下游任务(比如分割、检测)非常重要。每个阶段包含多个级联模块,每个模块包含两个子模块:(1) 用于集成空域信息的子模块,我们称之为空域集成模块;(2) 用于融合通道信息的子模块,我们称之为前向模块。
在该文中,我们固定通道融合模块为2层MLP;设计一种更佳的空域集成模块时本文的主要聚焦点。这四个阶段分别包含2-3-8-3个级联模块;每个阶段采用块嵌入融合 p × p p\times p p×p的块为向量。对于这四个阶段,p值分别为4-4-2-2。不同阶段的特征维度则为128-26-320-512。该架构具有与DeiT-S相近的参数量。
The CONTAINER-LIGHT Network
与此同时,我们还提出了一个高效版本CONTAINER-LIGHT,它采用了与CONTAINER相同的基础架构,但关闭了前三个阶段的动态关联矩阵。这种配置使其可以大幅降低计算量,进而可以高效处理大分辨率图像并在下游任务取得优异性能。
$$
\mathcal{A}_m^{CONTAINER-LIGHT} = \begin{cases}
\mathcal{A}_m^{conv}, \text{ Stage}=1,2,3 \
\alpha \mathcal{A}_m^{sa} + \beta \mathcal{A}_m^{conv}, \text{ Stage}=4
\end{cases}
$$
Experiments
接下来,我们在ImageNet、目标检测、实例分割以及自监督学习等任务上对所提方案进行系统分析。
ImageNet Classification
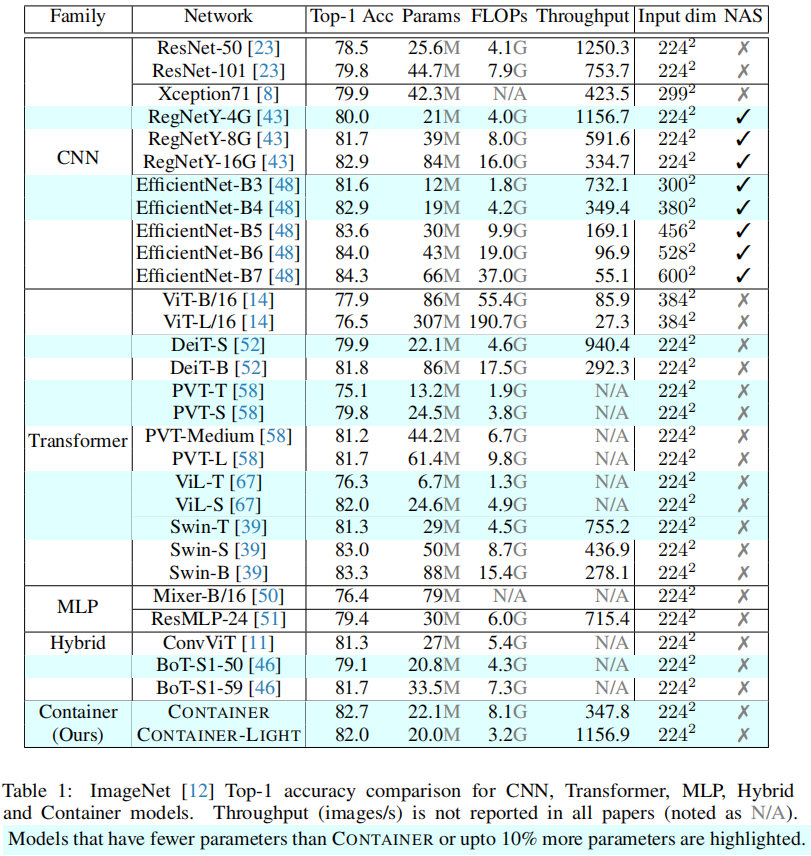
上表对CNN、Transformer、MLP以及本文Container进行了对比,从中可以看到:
- 相比ViT,DeiT,所提Container与Container-light具有更佳指标,同时具有更少参数量;
- 相比PVT、Swin等分层架构,所提方法同样具有更佳的性能;
- 所提方案仅弱于使用了NAS技术的EfficientNet与RegNet;
- Container-light不仅具有高精度,同时具有更低的FLOPs,更快的吞吐量。
Detection with RetinaNet
下表对比了RetinaNet框架下不同方案的性能对比,从中可以看到:
- 相比ResNet50,所提方案取得了43.8mAP,在 A P S , A P M , A P L AP_S,AP_M, AP_L APS,APM,APL指标上分别超出7.0,7.2,10.4,同时具有相当的参数量和复杂度;
- 所提方案同样超过了更大的骨干X-101-64以及纯Transformer的架构,如PVT-S, ViL-S, SWIN-T;
- 相比更大的Transformer骨干(比如ViL-M,ViL-B),所提方法具有相当的性能,但具有更少的参数量和计算量。
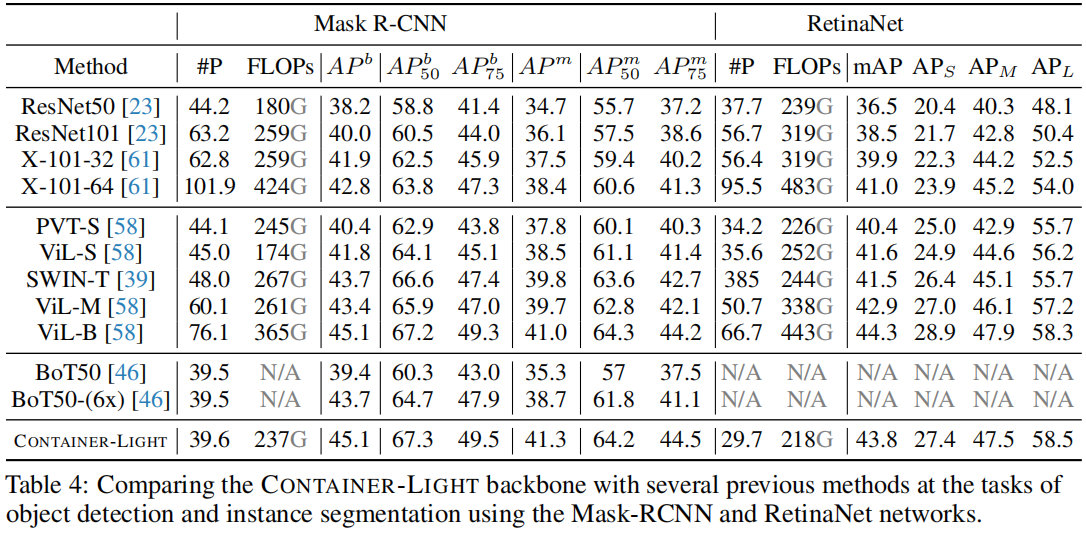
上表还给出了Mask-RCNN框架的不同方案性能对比,从中可以看到:所提方法同样大幅优于ResNet50、ResNet1010以及PVT、ViL、SWIN-T、BoT等方案。
Detection with DETR

上表给出了DETR框架下不同方案的性能对比,从中可以看到:相比ResNet50骨干,所提方案取得了显著性能提升,提升高达6.6mAP。
Self supervised Learning
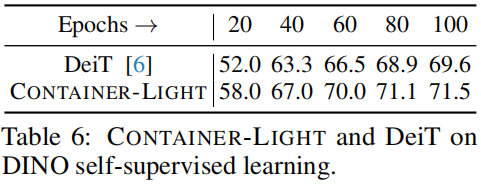
上表给出了自监督学习框架下不同方案的性能对比,可以看到:Container-light大幅超过了DeiT。
参考code
class Attention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., seq_l=196):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
#Uncomment this line for Container-PAM
#self.static_a = #nn.Parameter(torch.Tensor(1, num_heads, 1 + seq_l , 1 + seq_l))
#trunc_normal_(self.static_a)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
#Uncomment this line for Container-PAM
#attn = attn + self.static_a
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
推荐阅读
- “重参数宇宙”再添新成员:RepMLP,清华大学&旷视科技提出将重参数卷积嵌入到全连接层
- 新坑!谷歌提出MLP-Mixer:一种无卷积、无注意力,纯MLP构成的视觉架构
- MLP再添新砖,Facebook入局!ResMLP:完全建立在MLP上的图像分类架构
- CV圈杀疯了!继谷歌之后,清华、牛津等学者又发表三篇MLP相关论文,LeCun也在发声
- 突破置换模块计算瓶颈,MSRA开源轻量版HRNet,超越主流轻量化网络!|CVPR2021
- EfficientNet v2来了!更快,更小,更强!
- CVPR2021|“无痛涨点”的ACNet再进化,清华大学&旷视科技提出Inception类型的DBB
- TNT|为充分利用局部与全局结构信息,华为诺亚提出全新Transformer:TNT
- 金字塔Transformer,更适合稠密预测任务的Transformer骨干架构
- 来自Transformer的降维打击:ReID各项任务全面领先,阿里&浙大提出TransReID
- ResNet被全面超越了,是Transformer干的:依图科技开源“可大可小”T2T-ViT,轻量版优于MobileNet
- CNN与Transformer的强强联合!谷歌最新开源BoTNet,ImageNet达84.7%准确率



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











