






1 简介
MONAI网站提供了2D分类/分割、3D分类/分割等例程代码如下图所示,通过学习例程代码,初学者能够尽快掌握MONAI框架,但是由于开源框架软件版本更新较快、各模块功能难以协调等原因,这些例程往往无法在Kaggle平台直接运行。本文对MONAI官网第二个例程,即2D分割例程2D image segmentation with Unet的代码在Kaggle平台进行了修改和调试,并对修改后的例程代码进行了详细注释,为大家提供参考。本例程的数据集是由MONAI框架的函数生成随机圆圈图像,非常适合展示面向分割应用模型的训练与评估过程。
2 代码详解
通过前文 CSDN的学习,我们了解在Kaggle平台应用MONAI框架进行模型训练与评估的一般流程,主要分为:环境配置、数据准备、模型定义与参数设置、模型训练与评估等环节。
2.1 建立环境
(1)安装monai软件
Kaggle平台预装了与机器学习相关的很多框架,包括大名鼎鼎的sklearn等,但是没有monai软件,需要我们通过!pin install手动安装。代码及注解如下所示:
# 安装monai软件
!pip install monai代码成功运行界面如下图所示:
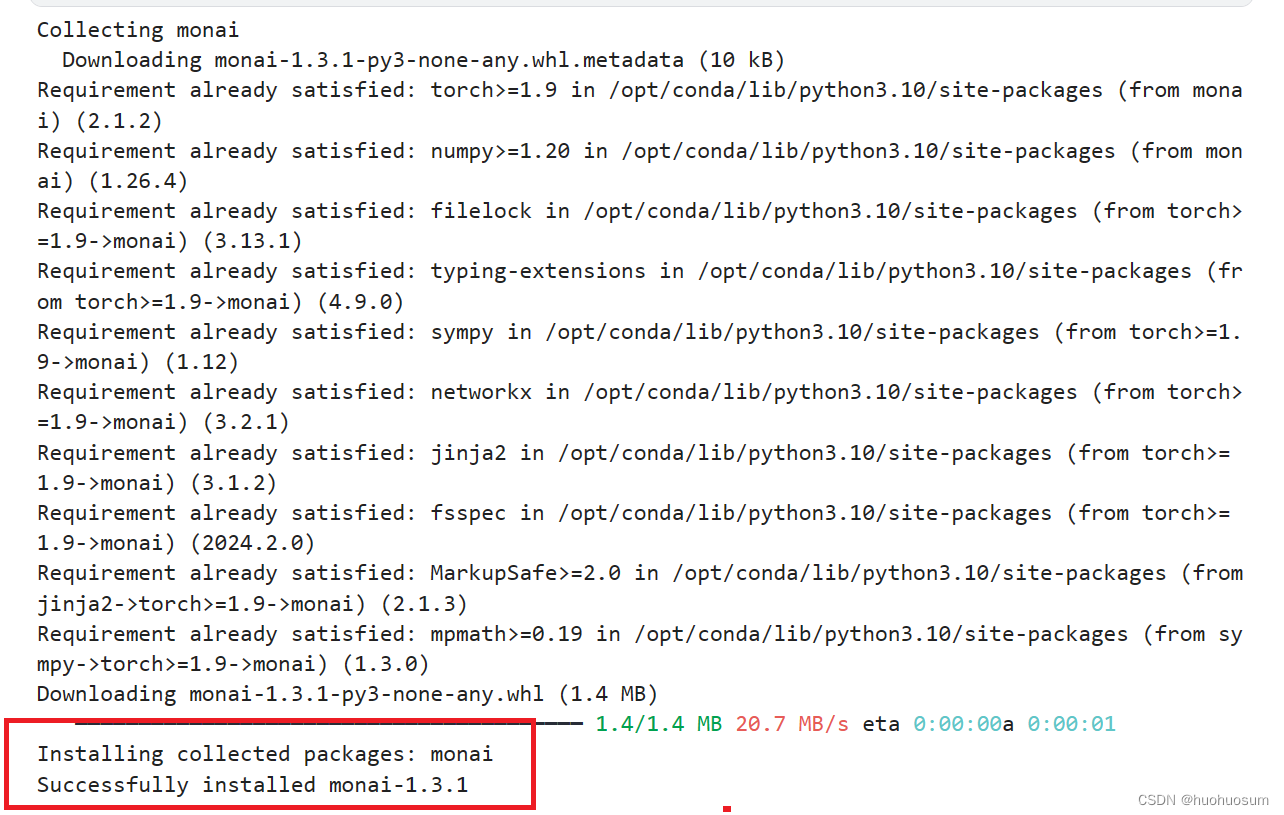
看到红框内Successfully installed monai的语句,说明成功下载并安装了monai软件,且当前版本为1.3.1。此外,我们还可以通过monai.__verison__查看monai的版本号。
# 查看版本号
monai.__version__结果如下图所示:

通过模块.__versoin__命令,我们可以查看模块版本,避免模块版本不一致导致的兼容性问题。
(2)导入基础软件包
通过下列代码,我们导入了文件目录操作、图像可视化以及pytorch训练相关软件包:
import logging # 导入日志库
import os # 导入文件目录操作系统库
import sys # 导入python系统特定参数和函数
import tempfile # 导入临时文件处理功能
from glob import glob # 导入glob函数,可使用*创建文件列表,替代条件列表表达式
import torch # 导入pytorc模块
from PIL import Image # 从PIL导入Image模块
from torch.utils.tensorboard import SummaryWriter # 导入摘要数据类,便于记录训练信息第一次成功运行,会生成下图所示的警告信息,这不影响后续代码运行,可以忽略。

(3)导入monai相关软件包
import monai #导入monai框架
# 导入monai.data模块生成图像函数reate_test_image_2d,
# 训练过程记录列表 list_data_collate
# 从批量分解为单元函数 decollate_batch
# 数据装载器 DataLoader
from monai.data import create_test_image_2d, list_data_collate, decollate_batch, DataLoader
# 从monai.inferers模块导入滑动窗口推理函数,用大小一致的小窗口分割结果整合出大分辨图像分割结果
from monai.inferers import sliding_window_inference
# 从monai.metrics模块导入Dice测量
from monai.metrics import DiceMetric
# 从monai.transforms模块导入激活函数、通道优先函数,连续到离散函数,组合函数,字典图像加载函数
# 基于阳性阴性标签的随机裁剪函数、随机旋转90度函数以及强度归一化函数等。
from monai.transforms import (
Activations,# 激活函数
EnsureChannelFirstd,# 通道优先函数,在数据形状左侧再增加一个维度。
AsDiscrete,# 把连续结果变换为离散值,如概率变为0或1
Compose,# 把变换函数首位相接组合在一起
LoadImaged,# 字典方式加载图像,输入是数据和掩模的文件名字典,输出是图像数据和掩模数据字典
RandCropByPosNegLabeld,# 根据阳性和阴性标签占比随机裁剪合适大小的图像区域,
#可以把高分辨率图像拆分多个低分辨率推向
RandRotate90d,#随机90度旋转
ScaleIntensityd,#图像强度归一化到(0,1)范围内。
)
# 导入 monai提供的可视化函数,在kaggle状态还无法正常运行
from monai.visualize.img2tensorboard import plot_2d_or_3d_image代码运行后,如果没有报错,说明所有模块及函数都正确导入。
(4)打印MONAI配置信息
我们可以通过一下语句打印Kaggle平台上的MONAI环境配置信息,并设置python的日志设置信息,代码如下:
# 打印monai配置信息和python日志设置信息
monai.config.print_config()
logging.basicConfig(stream=sys.stdout, level=logging.INFO)代码运行结果如下:

从中可以看出,相关软件包的安装版本,以及哪些可选的软件包尚未安装。我们可以根据实际应用要求,决定是否安装上述安装包。
2.2 生成数据集
(1)建立临时工作目录temp
Kaggle平台的工作目录是/kaggle/working,用户程序中间结果都保存在该目录下。在开始数据准备之前,先工作目录下建立临时文件夹temp。为了代码安全,我们一般不直接创建目录,而是先判断是否存在该目录:如果该目录不存在,直接创建,否则先删除再创建。代码及注释如下:
# 建立临时目录tempdir
import os #导入os软件包,进行目录及文件操作
import shutil#导入shutil软件包,用于删除目录
tempdir = r'/kaggle/working/temp/'# 设置临时目录
if os.path.exists(tempdir):#如果已存在该目录
shutil.rmtree(tempdir) # 删除该目录
os.makedirs(tempdir) # 建立临时工作目录代码运行结果如下图所示:左侧图是代码运行前的状态,右图是代码运行后的目录结构图,可以考到temp文件已成功创建。

(2)仿真生成数据
图像分割任务需要图像和掩模数据对,monai.data模块的create_test_image_2d函数可以轻松的实现上述功能,该函数的应用具体代码及注释如下所示:
# 生成图像create_test_image_2d应用示例
# 通过create_test_image_2d函数随机创建一张大小为128×128,掩模类型数目为1的数据和掩模
im, seg = create_test_image_2d(128, 128, num_seg_classes=1)
# 导入matplotlib.pyplot 绘图和可视化模块
import matplotlib.pyplot as plt
# 建立4×8英寸绘图窗口
plt.figure("image",(8,4))
# 创建1×2绘图布局中第一个绘图区
plt.subplot(1,2,1)
# 在该绘图区可视化im图像
plt.imshow(im)
# 在x坐标轴打印图像形状和图像最大最小值
plt.xlabel(f"{im.shape,im.max(),im.min()}")
# 创建1×2绘图布局第二个绘图区
plt.subplot(1,2,2)
# 在该绘图区可视化掩模seg图像
plt.imshow(seg)
#在x坐标轴打印图像形状和图像最大最小值
plt.xlabel(f"{seg.shape,seg.max(),seg.min()}")上述代码的分别生成了大小为128×128的圆圈图像和分割掩模图像,运行结果如下图所示:
 PIL是Python提供的图像处理软件库,很容易实现图像的加载、变换及保存等功能。我们利用PIL.image进行生成图像的保存,图像文件是后续数据集生成及数据加载的基础。图像保存示例代码及注释如下所示:
PIL是Python提供的图像处理软件库,很容易实现图像的加载、变换及保存等功能。我们利用PIL.image进行生成图像的保存,图像文件是后续数据集生成及数据加载的基础。图像保存示例代码及注释如下所示:
# 保存文件示例
# 把im从(0,1)范围线性变换到(0,255)范围,并把数据类型转换为uint8,便于后续处理
# 再把uint8的图像数据保存到/kaggle/working/temp文件夹下,命名为img0.png
Image.fromarray((im * 255).astype("uint8")).save(os.path.join(tempdir, f"img{0:d}.png"))
# 把seg从(0,1)范围线性变换到(0,255)范围,并把数据类型转换为uint8,便于后续处理
# 再把uint8的图像数据保存到/kaggle/working/temp文件夹下,命名为seg0.png
Image.fromarray((seg * 255).astype("uint8")).save(os.path.join(tempdir, f"seg{0:d}.png"))文件保存代码运行结果如下:

在temp文件夹下,已保存seg0.png和img0.png两个文件。通过修改save函数的参数,可以把图像数据保存到其他指定的目录位置。
接下来,我们综合运行以上数据生成和图像保存代码,循环生成40组图像和掩模数据,并保存到temp文件夹下。代码及详细注释如下:
# 建立数据
# create a temporary directory and 40 random image, mask pairs
# 提示信息
print(f"generating synthetic data to {tempdir} (this may take a while)")
# 40次循环操作
for i in range(40):
# 生成圆圈图像和模板
im, seg = create_test_image_2d(128, 128, num_seg_classes=1)
# 通过Image函数的fromarray和save把生成的随机图像及模板保存到临时文件夹。
Image.fromarray((im * 255).astype("uint8")).save(os.path.join(tempdir, f"img{i:d}.png"))
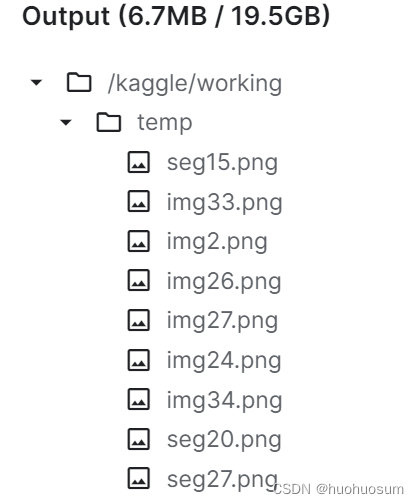
Image.fromarray((seg * 255).astype("uint8")).save(os.path.join(tempdir, f"seg{i:d}.png"))代码运行结果如下图所示:
 稍等一会,可以在temp文件夹下面看到很多seg和img文件。
稍等一会,可以在temp文件夹下面看到很多seg和img文件。

2.3 数据可视化
我们要处理的图像和掩模数据放到了/kaggle/working/temp目录下,图像是以img*.png命名,掩模是以seg*.png命名。在正式开始进入monai的深度学习流程之前,可以通过可视化这些数据集。这里我采用的是matplot.pyplot模块下的函数完成图像数据的读取与可视化,具体代码和详细注释如下:
# 随机读取3张图像及其对应的掩模图
# 2×3布局显示上述图像
import random # 导入python 随机数软件包
import os # 导入目录文件操作包
import matplotlib.pyplot as plt # 导入绘图及可视化工具
plt.figure("name",(12,8)) # 创建8×12英寸的绘图窗口
j=1 # 子窗口标号
for k in range(3): # 设置3次循环,
i = random.randint(0,40) # 产生0-39的随机数,作为文件名序号
img = plt.imread(os.path.join(tempdir,f'img{i:d}.png'))#随机读取图像文件
seg = plt.imread(os.path.join(tempdir,f'seg{i:d}.png'))#随机读取掩模文件
plt.subplot(2,3,j)# 创建第j个子区域
plt.imshow(img)#绘制图像
plt.xlabel(f"image({i})")#在x坐标轴添加文件序号
plt.subplot(2,3,j+3)#创建第J+3个绘图子区域
plt.imshow(seg,cmap='gray')#以灰度模式绘制掩模图
plt.xlabel(f"mask({i})")#在x坐标轴添加文件序号
j=j+1#循环变量递增代码成功运行后结果如下图所示:
 从中可以看出,生成的仿真数据和掩模数据时一一对应的,说明保存的数据没有问题。当然如果是在自己的电脑上运行代码,不用这么麻烦,可以直接进入目录文件夹查看。
从中可以看出,生成的仿真数据和掩模数据时一一对应的,说明保存的数据没有问题。当然如果是在自己的电脑上运行代码,不用这么麻烦,可以直接进入目录文件夹查看。
2.4 定义数据集及数据加载器
知道了数据的存储路径,就可以通过文件名列表进行数据集划分(xx_datalist),实施组合变换(trans),最终得到用于深度学习训练的数据加载器(dataloader)。
(1) 文件名列表
glob提供了利用文件通配符*获取文件名列表的方法,只要知道了数据文件的路径及命名规则,就能提取出该目录下面满足命名规则的文件名列表。glob函数返回的文件名列表顺序是随机的,需要sorted函数进行排序,使得图像和掩模文件序列能够一一对应,方面后续的训练。实现代码和注释如下:
#通过glob函数得到图像和掩模文件名列表。
images = sorted(glob(os.path.join(tempdir, "img*.png")))
segs = sorted(glob(os.path.join(tempdir, "seg*.png")))
assert(len(images)==len(segs)) # 确保图像和掩模数量相同还可以打印images和segs部分序列,确认文件序号是否一一对应,代码如下:
# 分别打印出图像和掩模的前十项文件名
images[0:10],segs[0:10]代码运行结果如下:

可以看出,经过排序后,images和segs文件名列表是一一对应。在准备数据时,一定要验证每一步的结果是否符合预期,有助于减轻后期的调试工作量。
(2) 数据集划分
机器学习的数据集一般划分为训练集、验证集和测试集。在模型训练阶段分为训练集和验证集,训练集用来更新模型权重,验证集用来评估模型性能以选择最优模型。当数据规模较小时(比如小于 1000),训练接和验证集的划分通常按照7:3来划分。本例只有40个数据样本,随意把20个样本作为训练集,20个样本作为验证集。数据集的划分可以通过切片操作实现,代码及详细注解如下所示:
#通过列表表达式,分别获得训练数据掩模字典和验证数据掩模字典,长度为20
train_files = [{"img": img, "seg": seg} for img, seg in zip(images[:20], segs[:20])]
val_files = [{"img": img, "seg": seg} for img, seg in zip(images[-20:], segs[-20:])]monai框架要求文件名为字典列表的方式,即{"img": img, "seg": seg},通过上述的字典表达式就可以分别得到训练集和验证集的字典列表。通过下面的语句可以打印出训练集文件名列表和验证集文件名列表。
train_files[0:10] # 打印前10项字典元素结果如下图所示:

val_files[0:10] #验证集前十项文件名字典结果如图所示:

(3) 定义变换
接下来,分别定义训练集和验证集变换。monai.transforms允许Compose组合多个变换函数,实现数据从文件名转换为深度学习框架所需数据结构形式。训练集的变换一般会包括一些数据增广操作,而验证集的变换往往只有最基本的图像加载、强度归一化等操作,具体代码及详细注释如下:
# 设置图像变换
# define transforms for image and segmentation
train_transforms = Compose(
[
LoadImaged(keys=["img", "seg"]),#按照字典方式读入数据和掩模
EnsureChannelFirstd(keys=["img", "seg"]),# 通道优先,数据形状变为[1,M,N]
ScaleIntensityd(keys=["img", "seg"]),# 将强度归一化到(0,1)范围
# 按照阳性阴性比例0.5来裁剪4个区域,每个区域大小为96×96
RandCropByPosNegLabeld(
keys=["img", "seg"], label_key="seg", spatial_size=[96, 96], pos=1, neg=1, num_samples=4
),
# 按照0.5概率随机旋转90°
RandRotate90d(keys=["img", "seg"], prob=0.5, spatial_axes=[0, 1]),
]
)
val_transforms = Compose(
[
LoadImaged(keys=["img", "seg"]),#验证集按照字典方式读入数据和掩模
EnsureChannelFirstd(keys=["img", "seg"]),# 确保通道优先
ScaleIntensityd(keys=["img", "seg"]),# 强度归一化
]
)
代码运行后,没有报错信息,说明程序运行成功。
(4) 定义数据集及数据加载器
monai.data模块提供了数据集函数Dataset和数据加载器Dataloader,可以非常方便根据数据所在目录和设定的变换,定义数据集,并从数据集逐步加载批量数据用于模型训练。因此,我们先要定义xx_ds数据集,再构造xx_loader加载器。先通过一个例子,看看图像和掩模数据通过数据加载器后的形状。具体代码及注释如下:
# define dataset, data loader
# 根据训练集文件列表和训练集变换,生成数据集
check_ds = monai.data.Dataset(data=train_files, transform=train_transforms)
# use batch_size=2 to load images and use RandCropByPosNegLabeld to generate 2 x 4 images for network training
# 建立数据加载器,批量为2,CPU为4,按照monai的方式collate_fn数据
check_loader = DataLoader(check_ds, batch_size=2, num_workers=4, collate_fn=list_data_collate)
# 安全的获取第一个样本
check_data = monai.utils.misc.first(check_loader)
print(check_data["img"].shape, check_data["seg"].shape)
# 修改不同的batch_size和num_workers,图像与掩模的形状是不同的代码成功运行结果如下图所示:

因为我们设置批量大小batch_size为2,线程数num_workers为4,因此数据第一维度为8;灰度图像通道数为1,图像尺寸为96×96。monai框架中模型所需数据形状为4维的。从加载器中得到的图像数据和掩模数据形状是一致的,说明前面的操作是正确的。
现在我们定义模型训练和验证用的数据集和数据加载器。代码及注释如下:
#建立训练和验证数据加载器
# create a training data loader
# 通过 monai.data.Dataset定义训练数据集
train_ds = monai.data.Dataset(data=train_files, transform=train_transforms)
# use batch_size=2 to load images and use RandCropByPosNegLabeld to generate 2 x 4 images for network training
# 定义数据加载器,便于训练迭代数据
train_loader = DataLoader(
train_ds,#训练数据集
batch_size=2,#批量为2
shuffle=True,#随机方式
num_workers=4,#4个CPU进程一同加载
collate_fn=list_data_collate,#按照monai方式堆叠记录数据
pin_memory=torch.cuda.is_available(),#当调用GPU时固定内存,提高传输效率
)
# create a validation data loader
# 定义验证数据集
val_ds = monai.data.Dataset(data=val_files, transform=val_transforms)
# 定义验证数据加载器
val_loader = DataLoader(val_ds, batch_size=1, num_workers=4, collate_fn=list_data_collate)
# 增加后处理变换,先通过激活函数把输出转换为(0,1)之间的概率,在通过离散化得到分割结果
post_trans = Compose([Activations(sigmoid=True), AsDiscrete(threshold=0.5)])2.5 定义模型及参数
医学图像分割采用Unet网络,monai.networks.nets提供了包含Unet在内的很多经典网络结构,下面我们介绍monai框架下的模型定义、损失函数选择和优化算法设置等过程,代码及注释如下:
# 定义模型及参数、损失函数和优化算法
# create UNet, DiceLoss and Adam optimizer
# 定义运算设备是CPU还是GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Unet模型参数设置
model = monai.networks.nets.UNet(
spatial_dims=2,
in_channels=1,
out_channels=1,
channels=(16, 32, 64, 128, 256),
strides=(2, 2, 2, 2),
num_res_units=2,
).to(device)
# 损失函数
loss_function = monai.losses.DiceLoss(sigmoid=True)
# Adam优化器
optimizer = torch.optim.Adam(model.parameters(), 1e-3)2.6 模型训练
模型训练是基于pytorch框架的,在每次训练循环中,通过数据加载器每步从数据集中加载一个批量的图像和掩模数据到CPU或GPU,按照前向传播、计算损失函数、反向传播、更新权重的过程训练模型。在验证过程,在禁止梯度计算、锁定权重条件下,对验证数据进行前向传播。代码及详细注释如下所示:
# 训练过程
# start a typical PyTorch training
# 定义DICE测量函数
dice_metric = DiceMetric(include_background=True, reduction="mean", get_not_nans=False)
val_interval = 2 # 模型验证间隔,各一个epoch验证一次
best_metric = -1 # 最佳测量结果
best_metric_epoch = -1 # 最佳测量对应的epoch
epoch_loss_values = list() # 训练损失列表
metric_values = list() # 测量值裂帛啊
writer = SummaryWriter() # 过程记录
for epoch in range(10): # 10次训练,10次遍历训练集
print("-" * 10)
print(f"epoch {epoch + 1}/{10}") # 每次训练显示的信息
model.train() # 开始训练,初始化函数
epoch_loss = 0#训练损失初始化
step = 0#阶段初始化
for batch_data in train_loader:#从训练接迭代获取训练数据
step += 1 # 步骤递增
#把图像及掩模加载到设备,注意图像及标签格式应该为(batch_size,channel,M,N)
#可以通过reshape(1,-1),或者unsequeeze()得到
inputs, labels = batch_data["img"].to(device), batch_data["seg"].to(device)
# 梯度初始化
optimizer.zero_grad()
# 前向传播,得到预测值,批量图像数据
outputs = model(inputs)
# 根据标签,批量计算损失函数
loss = loss_function(outputs, labels)
# 反向传播计算梯度
loss.backward()
# 更新权重
optimizer.step()
# 累加每个批量的损失函数
epoch_loss += loss.item()
# 计算每个epoch的加载次数
epoch_len = len(train_ds) // train_loader.batch_size
# 打印 显示每个step(批量)的损失
print(f"{step}/{epoch_len}, train_loss: {loss.item():.4f}")
# 把step损失和对应的批量批次放入writer中,
writer.add_scalar("train_loss", loss.item(), epoch_len * epoch + step)
epoch_loss /= step #鼻梁完成后,计算平均损失
epoch_loss_values.append(epoch_loss) # 平均损失追加为一个向量
print(f"epoch {epoch + 1} average loss: {epoch_loss:.4f}")#打印当前epoch及平均损失
# 每个epoch训练后,都判断是否需要验证,间隔一次验证一次
if (epoch + 1) % val_interval == 0:
model.eval()#模型评估初始化
with torch.no_grad():#不需要计算梯度,提高效率
val_images = None #初始化
val_labels = None
val_outputs = None
for val_data in val_loader:# 加载验证集
#验证集图像及掩模装入设备
val_images, val_labels = val_data["img"].to(device), val_data["seg"].to(device)
# 设置感兴趣区大小为96 96
roi_size = (96, 96)
# 批量为4
sw_batch_size = 4
# 使用滑动窗口预测,96 96 预测四次得到最终退昂
val_outputs = sliding_window_inference(val_images, roi_size, sw_batch_size, model)
# 从val_outputs分解出单个图像列表
val_outputs = [post_trans(i) for i in decollate_batch(val_outputs)]
# compute metric for current iteration
#计算预测与真实掩模图像的DICE
dice_metric(y_pred=val_outputs, y=val_labels)
# aggregate the final mean dice result
# 得到最终的DICE
metric = dice_metric.aggregate().item()
# reset the status for next validation round
# 初始化DICE测量值
dice_metric.reset()
# 形成DICE测量值列表
metric_values.append(metric)
if metric > best_metric:# 如果当前的DICE值大于已保存的最优值
best_metric = metric# 保存当前的DICE值作为最优值,并保存模型参数
best_metric_epoch = epoch + 1
torch.save(model.state_dict(), "best_metric_model_segmentation2d_dict.pth")
print("saved new best metric model")
print(
"current epoch: {} current mean dice: {:.4f} best mean dice: {:.4f} at epoch {}".format(
epoch + 1, metric, best_metric, best_metric_epoch
)
)
# 记录平均DICE值
writer.add_scalar("val_mean_dice", metric, epoch + 1)
# plot the last model output as GIF image in TensorBoard with the corresponding image and label
# 利用monai.visualization 输出曲线
plot_2d_or_3d_image(val_images, epoch + 1, writer, index=0, tag="image")
plot_2d_or_3d_image(val_labels, epoch + 1, writer, index=0, tag="label")
plot_2d_or_3d_image(val_outputs, epoch + 1, writer, index=0, tag="output")
print(f"train completed, best_metric: {best_metric:.4f} at epoch: {best_metric_epoch}")
writer.close()代码成功运行结果如下图所示:

经过10个epochs的训练,模型验证精度DICE值达到0.9895。
2.7 模型评估
为了验证模型泛化能力,一般在测试集上评估模型的性能。评估过程与上面介绍模型验证过程类似,这里不再赘述。代码如下,如有问题,欢迎留言讨论。
(1) 导入软件包
import logging
import os
import sys
import tempfile
from glob import glob
import torch
from PIL import Image
import monai
from monai.data import create_test_image_2d, list_data_collate, decollate_batch, DataLoader
from monai.inferers import sliding_window_inference
from monai.metrics import DiceMetric
from monai.networks.nets import UNet
from monai.transforms import (
Activations,
EnsureChannelFirstd,
AsDiscrete,
Compose,
LoadImaged,
SaveImage,
ScaleIntensityd,
)(2) 工作目录设置
# 创建预测输出文件夹
if os.path.exists(r'/kaggle/working/output'):
shutil.rmtree(r'/kaggle/working/output')
os.makedirs(r'/kaggle/working/output')
# 创建数据目录
tempdir = r'/kaggle/working/temp'
if os.path.exists(tempdir):
shutil.rmtree(tempdir)
os.makedirs(tempdir)(3) 评估过程(前向传播)
# 评估
monai.config.print_config()
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
print(f"generating synthetic data to {tempdir} (this may take a while)")
# 为了文件名排序相同,扩展名前加_
for i in range(20):
im, seg = create_test_image_2d(128, 128, num_seg_classes=1)
Image.fromarray((im * 255).astype("uint8")).save(os.path.join(tempdir, f"img{i:d}_.png"))
Image.fromarray((seg * 255).astype("uint8")).save(os.path.join(tempdir, f"seg{i:d}_.png"))
images = sorted(glob(os.path.join(tempdir, "img*.png")))
segs = sorted(glob(os.path.join(tempdir, "seg*.png")))
val_files = [{"img": img, "seg": seg} for img, seg in zip(images, segs)]
# define transforms for image and segmentation
val_transforms = Compose(
[
LoadImaged(keys=["img", "seg"]),
EnsureChannelFirstd(keys=["img", "seg"]),
ScaleIntensityd(keys=["img", "seg"]),
]
)
val_ds = monai.data.Dataset(data=val_files, transform=val_transforms)
# sliding window inference need to input 1 image in every iteration
val_loader = DataLoader(val_ds, batch_size=1, num_workers=4, collate_fn=list_data_collate)
dice_metric = DiceMetric(include_background=True, reduction="mean", get_not_nans=False)
post_trans = Compose([Activations(sigmoid=True), AsDiscrete(threshold=0.5)])
saver = SaveImage(output_dir="/kaggle/working/output/",output_postfix='mask',
output_ext='.png',separate_folder=False)# 不会对每个输出建立目录
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = UNet(
spatial_dims=2,
in_channels=1,
out_channels=1,
channels=(16, 32, 64, 128, 256),
strides=(2, 2, 2, 2),
num_res_units=2,
).to(device)
# output_postfix='trans', output_ext='.nii.gz'
model.load_state_dict(torch.load("best_metric_model_segmentation2d_dict.pth"))
model.eval()
with torch.no_grad():
for val_data in val_loader:
val_images, val_labels = val_data["img"].to(device), val_data["seg"].to(device)
# define sliding window size and batch size for windows inference
roi_size = (96, 96)
sw_batch_size = 4
val_outputs = sliding_window_inference(val_images, roi_size, sw_batch_size, model)
val_outputs = [post_trans(i) for i in decollate_batch(val_outputs)]
val_labels = decollate_batch(val_labels)
# compute metric for current iteration
dice_metric(y_pred=val_outputs, y=val_labels)
for val_output in val_outputs:
saver(val_output)
# aggregate the final mean dice result
print("evaluation metric:", dice_metric.aggregate().item())
# reset the status
dice_metric.reset()代码成功运行结果如下图所示:
 (4) 可视化结果
(4) 可视化结果
模型预测后,处理观察测量指标来判断模型预测性能之外,还可以可视化预测结果来直观看看模型的分给效果。模型预测结果放在output目录下,而生成的仿真数据放在temp目录下面,通过matplotlib.pyplot模块的下函数,可以很容易读出指定目录的数据并显示出来。下列代码可以实现从目录读取原始数据、掩模、以及预测分割结果,并通过九宫格显示出来。代码如下:
import matplotlib.pyplot as plt
# 可视化
images = sorted(glob(os.path.join(tempdir, "img*.png")))
segs = sorted(glob(os.path.join(tempdir, "seg*.png")))
preds = sorted(glob(os.path.join(r'/kaggle/working/output/', "img*.png")))
assert(len(images)==len(preds))
images,segs,preds
# os.listdir(r'/kaggle/working/output/')
#
ist = 3
plt.figure("name",(10,10))
plt.subplot(3,3,1)
img=plt.imread(images[ist])
plt.imshow(img)
plt.title('image')
plt.subplot(3,3,2)
seg =plt.imread(segs[ist])
plt.imshow(seg,cmap='gray')
plt.title('mask')
plt.subplot(3,3,3)
pred=plt.imread(preds[ist])
plt.imshow(pred,cmap='gray')
plt.title('pred')
plt.subplot(3,3,4)
img=plt.imread(images[ist+1])
plt.imshow(img)
plt.title('image')
plt.subplot(3,3,5)
seg =plt.imread(segs[ist+1])
plt.imshow(seg,cmap='gray')
plt.title('mask')
plt.subplot(3,3,6)
pred=plt.imread(preds[ist+1])
plt.imshow(pred,cmap='gray')
plt.title('pred')
plt.subplot(3,3,7)
img=plt.imread(images[ist+2])
plt.imshow(img)
plt.title('image')
plt.subplot(3,3,8)
seg =plt.imread(segs[ist+2])
plt.imshow(seg,cmap='gray')
plt.title('mask')
plt.subplot(3,3,9)
pred=plt.imread(preds[ist+2])
plt.imshow(pred,cmap='gray')
plt.title('pred')代码运行结果如下图所示:

上图第一列是原始图像,中间一列是对应的掩模图,而第三列是预测分割结果。对于简单的仿真图像,样本虽然不多,但是模型还是很快能学习到样本的特征,预测到较为合理的结果。
3 总结
MONAI官网2D分割例程无法在Kaggle平台直接运行,本文对2D分割例程进行了基于Kaggle平台的适应性修改,并逐步介绍了平台配置、数据准备、模型训练与验证等过程,最后还给出了模型评估的代码,便于大家借鉴参考!如有问题,欢迎大家一起讨论,共同进步!
参考
[1]MONAI官网链接: MONAI - Get Started















 5943
5943











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









