






1 简介
本文在对MONAI例程“Medical Image Classification Tutorial with the MedNIST Dataset”简要总结的基础上,归纳了应用MONAI框架进行医学图像分类的一般步骤。随后,基于Breast Ultrasound Image数据集,逐步介绍如何把MONAI例程快速地应用到新的数据集上,帮助初学者轻松掌握MONAI框架,并尽快地应用到自己研究的专有数据集上。
2 例程代码总结
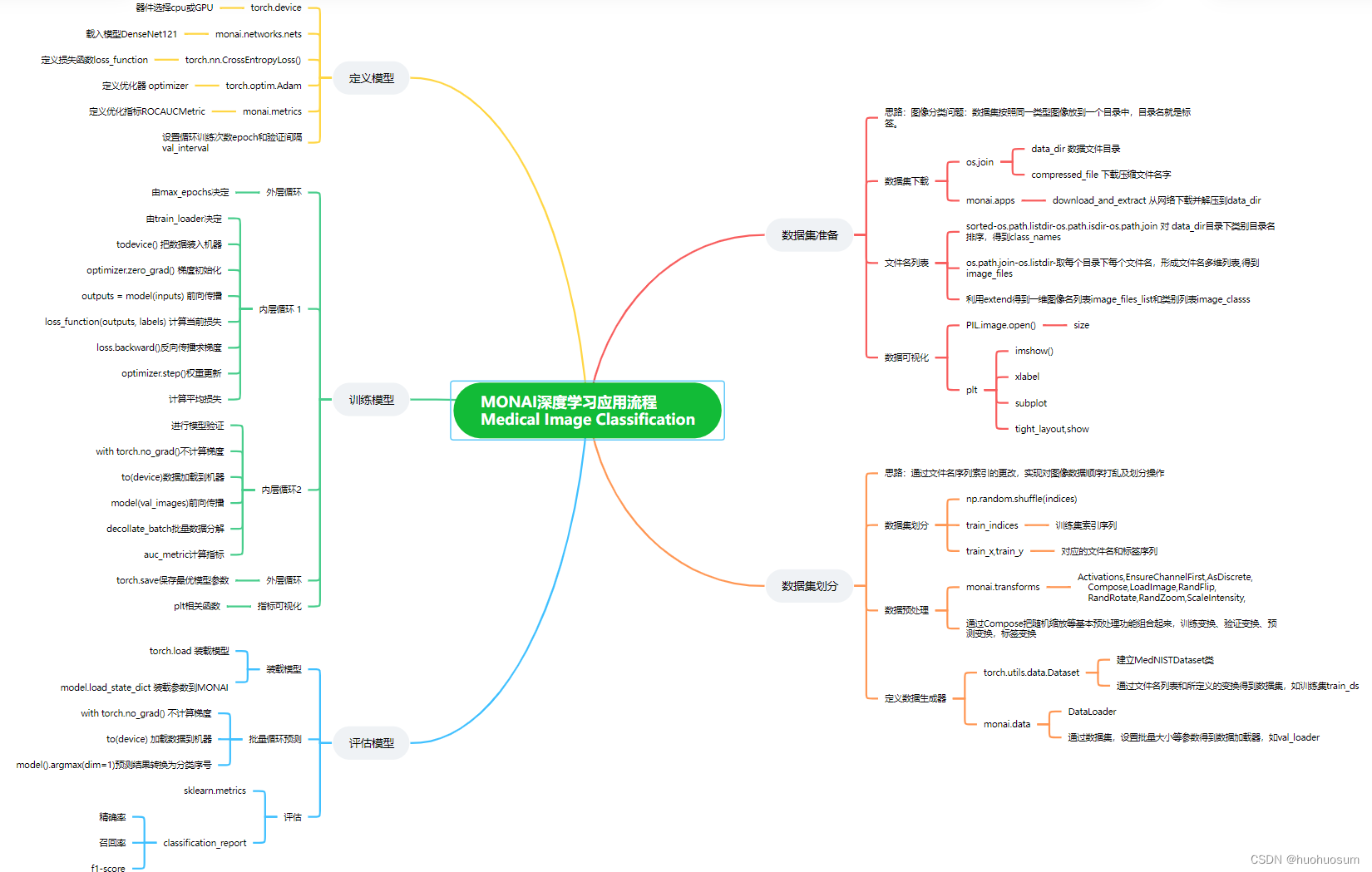
上图对例程代码进行了归纳,基于DenseNet121模型训练与评估过程分为五个阶段:
- 数据准备
利用monai框架函数down_and_extract从网络下载并提取数据集,数据集分为6个文件夹,每个文件夹包含了一类图像数据。再利用os软件包的listdir等函数,结合列表表达式得到文件名列表和标签列表。在深度学习框架中,一般通过对文件名列表的操作,实现对数据的排序和数据集划分等操作。 - 数据集划分
借助索引,先通过对文件名列表和标签列表操作,划分训练集、验证集和测试集;再借助monai框架的transformm函数定义三种数据集上采用的不同变换;最后定义monai数据集和数据加载器。 - 定义模型
通过torch框架和monai框架的函数,完成模型、损失函数、优化算法的定义。 - 训练模型
按照torch的训练与验证步骤,对所有样本以批量方式进行训练。模型训练包含前向传播、反向传播、损失计算和权重更新等过程;而模型验证无需计算梯度,只包含前向传播和交叉熵计算过程。所有训练完成只有,保存最佳模型参数。 - 评估模型
评估模型采用测试数据集,先加载最优模型,进行前向传播得到预测值,再通过sklearn框架函数计算预测结果的精确率、召回率和f1-score等指标,全面评估模型性能。
3 在新数据集应用代码
3.1 数据集简介
(Breast Ultrasound Image)是一个包含乳腺超声图像的分类和分割数据集。该数据集包括了 2018 年收集的乳腺超声波图像,涵盖了 25 至 75 岁的 600 名女性患者。数据集由 780 张图像组成,每张图像的平均大小为 500*500 像素。这些图像被划分为三类:正常、良性和恶性。而在良性和恶性乳腺超声图像中,还包含了对应胸部肿瘤的详细分割标注,为深入研究和精准诊断提供了关键信息。这份数据集为乳腺癌研究提供了丰富的图像资源和宝贵支持。
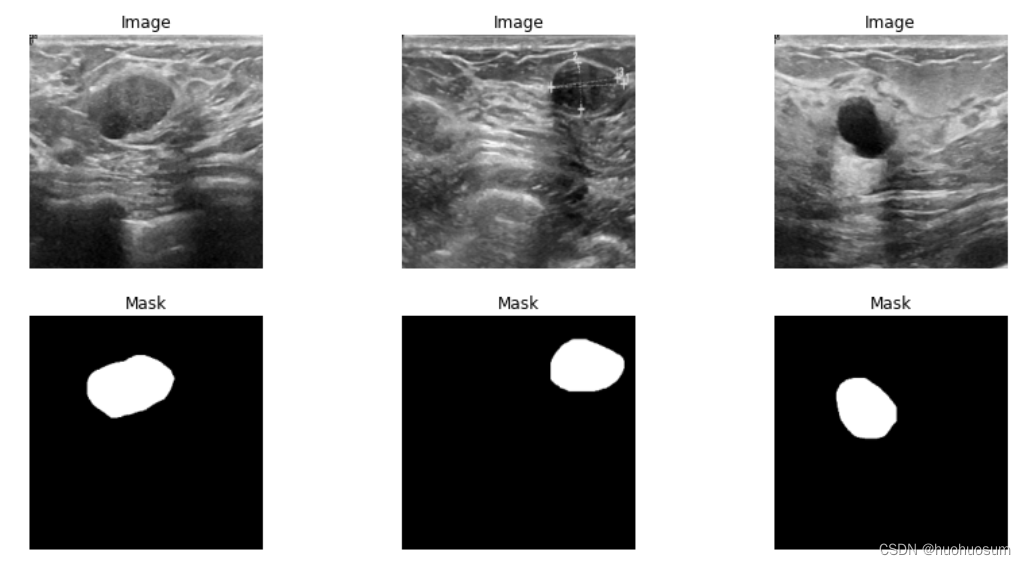
下面我们将根据该数据集的特点,对Medical Image Classification Tutorial with the MedNIST Dataset进行适应性修改,训练出能正确区分正常乳腺、良性肿瘤乳腺和恶性肿瘤乳腺的神经网络。
3.2 代码修改思路
通过对比MedNIST数据集和BUSI数据集的不同,可以发现BUSI数据集的图像有以下特点:
(1)BUSI数据集图像尺寸大小不一致;
(2)BUSI数据集图像通道数量为3;
(3)BUSI数据集每类目录下,除了原始图像数据外还包括掩模数据。
我们需要对BUSI数据集进行修改,使其大小一致,通道数修改为1。
此外,还需调整模型训练相关参数,比如批量大小改为16,训练循环次数改为50,以适应数据集的变化。
3.3 关键代码修改验证
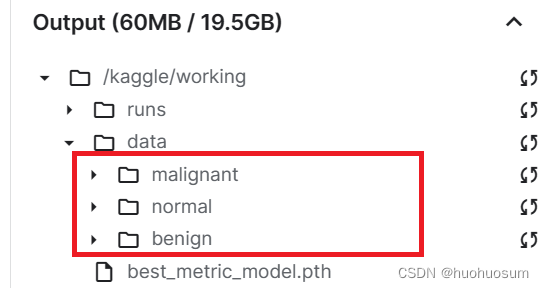
(1)在kaggle建立数据目录
source_dir = r'/kaggle/input/breast-ultrasound-images-dataset/Dataset_BUSI_with_GT'
target_dir = r'/kaggle/working/data'
import shutil # 删除工作目录,避免后续操作错误
if os.path.exists(target_dir):
shutil.rmtree(target_dir)
# 建立目录
# 列表表达式,获得source_dir目录下的所有数据目录,即类别列表
class_names = sorted(x for x in os.listdir(source_dir) if os.path.isdir(os.path.join(source_dir, x)))
for i in range(len(class_names)): # 在target目录下新建类别目录
if not os.path.exists(os.path.join(target_dir,class_names[i])):
os.makedirs(os.path.join(target_dir,class_names[i]))
新建目录结果如下图所示:
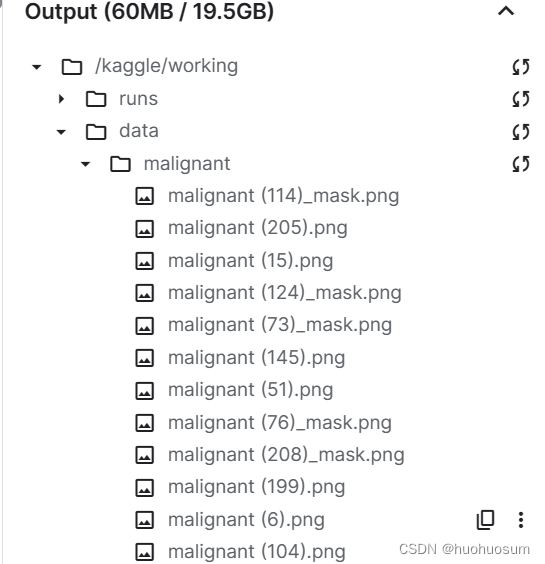
(2)读取、缩放图像并保存到工作目录
for i in range(len(class_names)):
src_list = os.listdir(os.path.join(source_dir,class_names[i]))
for j in range(len(src_list)):
img_tmp = PIL.Image.open(os.path.join(source_dir,class_names[i],src_list[j]))
img_tmp = img_tmp.resize((256,256))
img_gray = img_tmp.convert("L")
img_gray.save(os.path.join(target_dir,class_names[i],src_list[j]))
图像拷贝效果如下图所示:
(3)修改root_dir和data_dir
root_dir = r'/kaggle/working/'
data_dir = os.path.join(root_dir, "data")
将原例程中的工作目录指向我们新建的数据复制目录。
(4)文件名索引中去掉掩模文件
新的数据集中有掩模文件,如果把掩模文件也作为训练数据,会降低模型性能,因此,有必要在生成文件名列表时,排除掩模文件。通过观察掩模文件命名规则可知,所有原始图像文件都是以).png结尾,可以借助os.endswith()取出所有后缀名为_mask.png的文件。代码如下:
class_names = sorted(x for x in os.listdir(data_dir) if os.path.isdir(os.path.join(data_dir, x)))
# 获取标签数量
num_class = len(class_names)
# 文件名列表
image_files = [
[os.path.join(data_dir, class_names[i], x) for x in os.listdir(os.path.join(data_dir, class_names[i]))
if x.endswith(").png")]
for i in range(num_class)
]
## 列表表达式得到每一类数据个数的列表,
num_each = [len(image_files[i]) for i in range(num_class)]
image_files_list = []# 定义文件名列表
image_class = []#定义目标种类列表
for i in range(num_class): # 将二维图像文件名整合为一维列表。
image_files_list.extend(image_files[i])# 图像文件名序列
image_class.extend([i] * num_each[i])# 标签序列,与图像文件名序列长度相同
num_total = len(image_class) # 标签序列的长度就是总共的样本数量,即文件名序列长度。
image_width, image_height = PIL.Image.open(image_files_list[0]).size # 所有文件的图像数据都是相同大小,
#通过图像文件名列表的第一个文件获得图像的尺寸
print(f"Total image count: {num_total}")#输出样本总数
print(f"Image dimensions: {image_width} x {image_height}")#输出图像数据的尺寸 64×64
print(f"Label names: {class_names}")# 输出标签种类
print(f"Label counts: {num_each}") # 输出每个标签对用的图像数据数量
运行结果如下:
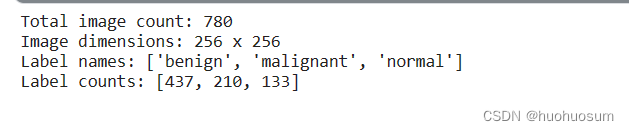
从图中可以看出,整理后的数据集分为 三类,一共有780张图像,图像大小为256×256。
(5)模型参数
把批量大小修改为16,训练循环次数epoch设置为50,其他参数与原例程保持一致。
3.4 全部代码运行结果`
模型训练结果如图所示:
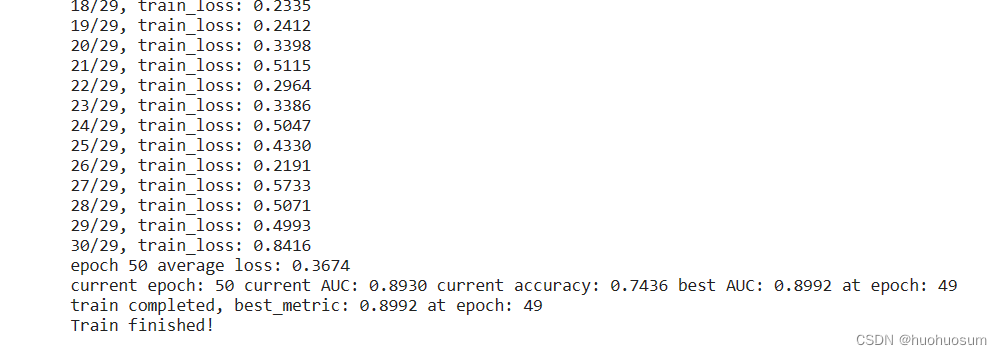
训练过程中损失函数与AUC变化曲线如图所示:
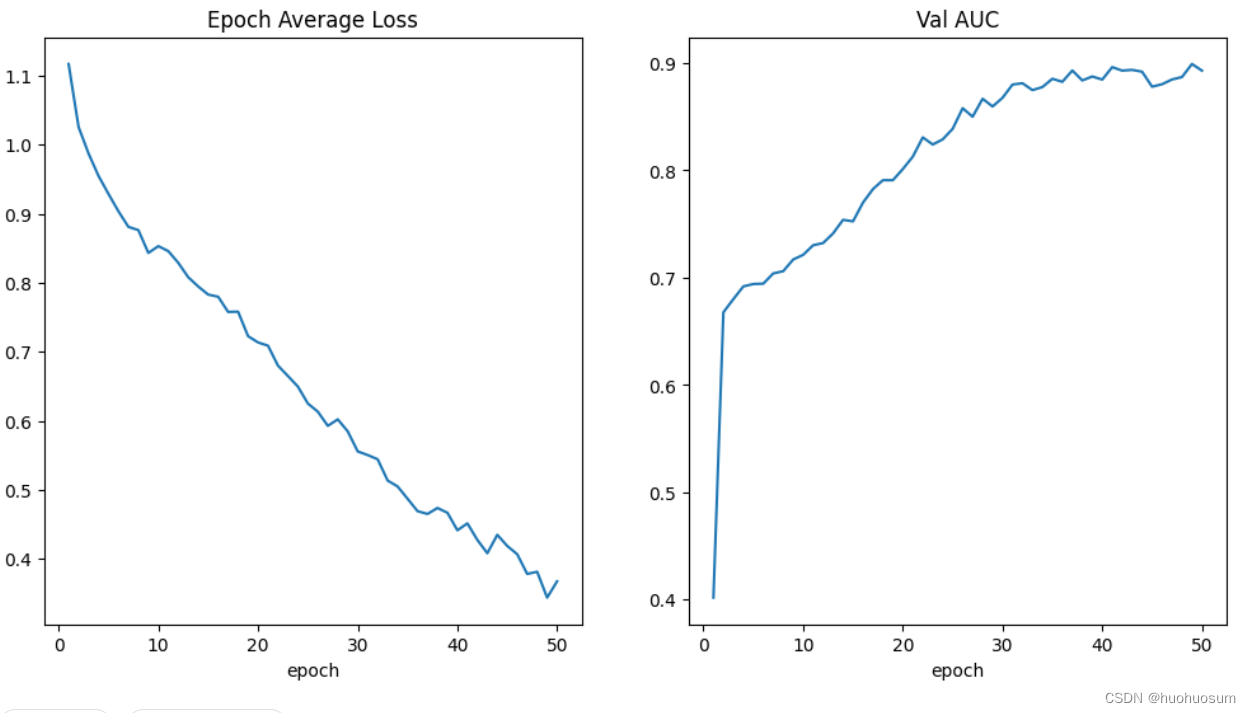
可以看出,随着训练次数的增加,损失不断减小,AUC不断增加。
在测试集上评估模型效果,精确率、召回率等指标如下图所示:
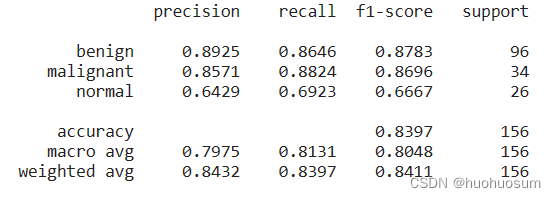
从结果可以看出,除了normal类型预测f1-score比较低外,其他两类的指标值均接近0.9,说明例程的模型也可以用于乳腺超声数据集。
4 总结
本文先总结归纳了MONAI框架进行医学图像分类的基本步骤,然后经过对BUSI数据集进行分析,提出了例程代码修改思路,并逐步展示了如何修改MONAI例程代码以适应新的数据集应用,为初学者上手MONAI提供了参考。现在模型的估计效果还不是最优,我认为有两个原因,一个是数据量比较少,只有700多张图像,而MedNIST有万张图像,可以支撑模型实现0.99的预测准确率;二是超声图像数据在缩放过程丢失了一些信息,可能会降低模型的识别能力。如果要提高模型预测性能,可以从两方面着手:一是进行数据增广,提高数据多样性;二是增加训练次数,从训练曲线上看,损失函数和AUC都有持续优化的趋势。
[2]: Al-Dhabyani W, Gomaa M, Khaled H, Fahmy A. Dataset of breast ultrasound images. Data in Brief. 2020 Feb;28:104863. DOI: 10.1016/j.dib.2019.104863

















 5972
5972

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









