










最近需要做sqlite的并发优化,会有一些多主机多进程的操作失败问题,所以学习一下,顺便为了翻阅,做一个笔记收集。
未完成。。。。。。。。。。。。。。。。。。。
to be continued
目前只对我某时刻最关注的点做笔记,默认简单的就跳过了。
工作和时间原因,顺序有些乱,可能随时遇到问题就插进去了。
锁机制与事务类型
https://www.cnblogs.com/lijingcheng/p/4454884.html
sqlite3源代码注释说明
等等等。。。
关键点
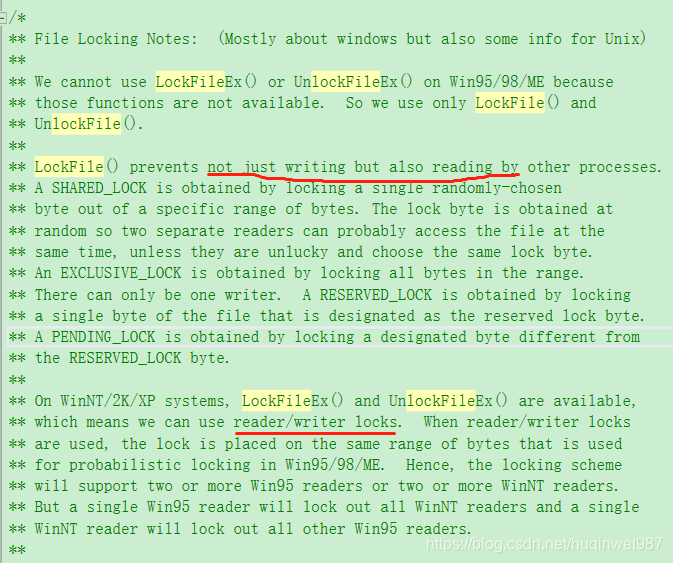
读share、写(内存)reserve、写(磁盘)exclusive。(问题:reserve)
share:池大小可以控制。池里得到一个字节,就算占了一个位置,一个锁(既然权限这么低,还锁什么锁?主要就是一方面可能池小能控制读,节省资源?另一方面应该是为了后续那几个操作可以安全进行,所以这算一个flag性质吧)。
reserved:只有一个,其他的可以拿share,高级的可能不行了。
pending:现有share还在,不能再拿了,类似要提交的状态了,等其他的锁都放掉,我就可以写磁盘了?也就是升级exclusive?(pending可以升级exclusive——sqlite3OsLock())
exclusive:完全互斥所有。(感觉少写几次磁盘才有性能,wal可以(但是跨主机共享的话,wal不能用)?transaction和stmt可以?stmt好像是省了编译过程,没说省写入过程)
锁的操作系统支持
LockFile()、UnLockFile()、LockFileEx()、UnLockFileEx(),理论可以跨linux和win。理论可以安全跨系统跨进程共享数据库。(WAL例外吧,WAL加速依赖的是系统缓存,跨系统怎么能共享内存呢?!!所以跨系统应该关闭WAL)
这里细节也不用太关注,一般都是高级系统了,旧系统功能稍微低级点,锁的情况更多
死锁的例子:
前边的帖子把insert详细的和reserved锁绑定了,说提交是exclusive,说两个事务都打开,如果两个终端都insert,会死锁,谁都不成功,但是我实测如下(只代表默认环境和默认命令)——如果第二个insert执行了但未commit,第一个再insert是失败的,而不是两个都是insert执行等待commit。
开始
1:begin
2:begin
1.insert
2.insert//失败:database is locked
1.commit
2.insert//需要自己主动重新执行
2.commit
完成
可能我默认的锁的控制级别和他不一样?也可能我的终端和代码实现中确切的这些阶段其实不对应?
BEGIN [DEFERRED /IMMEDIATE / EXCLUSIVE] TRANSCATION
实测,如果用begin immediate,那么另一个客户端连begin都不行了!
如果用begin deferred,可以双开deferred(注意,两个终端都用begin deferred,而不是一个加一个不加,这样实验更准确),结果和第一个过程一样!(这样描述,当第一个事务执行了insert,可能就换成了reserved锁,占了reserved锁,另一个想insert,也需要这个锁,但是reserved只能有一个,所以得不到,此时第一个需要commit,按他描述的,确实失败了,原来一个select都影响这么大,有了select,就占用了一个shared锁,不放开,commit就不成功!!!!)
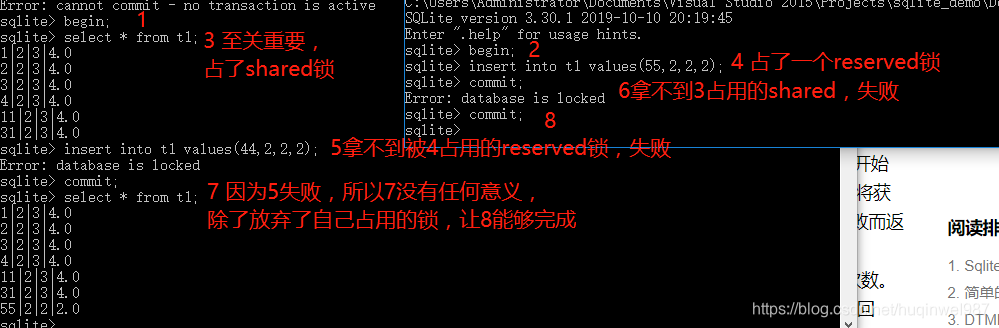
如果用begin exclusive,那么其他终端不能begin exclusive,但是能begin(应该是shared),此时,哪怕终端1没有输入insert,终端2仍然不能输入insert(不同于默认或者deferred的“先到先得”——谁先insert,谁先占坑),属于先天残疾。
其实,select都办不到(本例没输入begin;但是先begin;select同样无效)
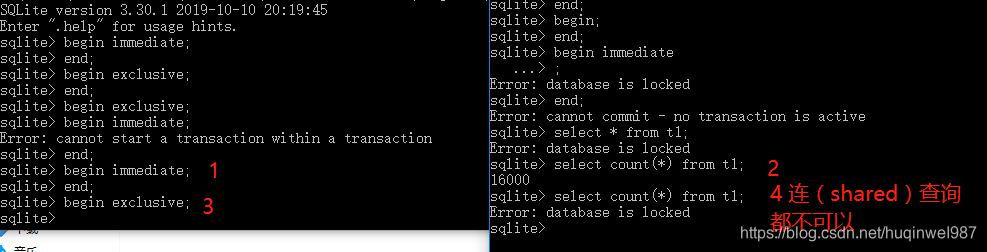
多种事务混合不同时机和类型:不好确定,很多情况,比如先开普通1,再开exclusive2,那么普通1仍然不可以insert,先开普通1,但是先insert,只是未commit,exclusive2根本打不开。总之,他还是会遵守大原则,分支情况太多,比较难描述,需要的话还是自己根据自己的需求实际调试一下。——begin immediate好像对应RESERVERD(实测也一样表现,已经打开的还在,但是不能提交了)
不负责的小结:单机可以用deferred,或者说多个deferred事务开启后,谁先insert谁先exclusive(也许是pending?pending是锁的状态,不是begin带的选项,pending可以“升级”到exclusive)
代码中的“事务”和在终端手动显性“begin”一个事务,不一定是一样的,也许你执行一个语句,整个流程都封装在execute内部了。
线程模式:
https://www.cnblogs.com/feng9exe/p/10682567.html
单线程模式、多线程模式、串行模式(多进程没说?这帖子没提到多进程,但是“采用串行模式,所有线程公用同一个数据库连接”,指的是多进程么?)
编译时设定、初始化设定、运行时设定。
事务和插入的区别:每秒能支持50000条数据,但是每秒只能支持几十个事务,主要是写磁盘的限制(所以有手动选择bigin-end时机,wal和stmt之类的吧,当然这些东西场合、时机、效果都不同,不是并列关系)
unlocked、shared、reserved、pending、exclusive,前边有,不赘述。这些锁状态在终端中不一定是显性指定的,可能你进行了某种操作,自动就变了状态,我也有演示。
线程的锁有前置关系?必须先拿低级,再拿高级(也是源码说明)
锁状态的顺序问题、一些允许的时机:
** UNLOCKED -> SHARED
** SHARED -> RESERVED
** SHARED -> (PENDING) -> EXCLUSIVE
** RESERVED -> (PENDING) -> EXCLUSIVE
** PENDING -> EXCLUSIVE
eFileLock枚举、
sqlite3OsUnlock解锁(lower a locking level???),pagerUnlockDb调用前者
此连接推荐了一套设置,在此我就不参考了,每个人的情况不同。
sqlite中db连接的含义与跨系统多进程
据我了解,与mysql不同,sqlite理论上是没有网络连接这个概念的,“db”就是直接被“打开”,那么db是什么?打开是什么?db其实就是一个文件,所谓的多个连接,如上,应该是靠系统支持的锁文件接口来实现互斥的。那么多个连接对数据库的写操作,无论是线程、进程、还是物理主机,我认为属于同一种性质(WAL模式除外),无论开几个终端,开几个C++进程的open,应该是等价的(可以用来还原情景)。那么如果这个假设成立,只要用begin immediate,应该就可以实现安全的互斥写操作。
stmt
其实不是字符串,也没这个结构体,本质是Vdbe结构体,里边可以预编译,让语句执行更快。
reset+bind循环,节省掉finalize和prepare,就快(实测)。
关键是,也对应不好stmt和各种时机阶段的关系,stmt主要就是prepare、bind、step、reset、finalize,都封装过了。
stmt没被很好的初始化(prepare)也可能导致misuse(misuse另一种情况就是sql语句拼错了)。
stmt的加速机制,不赘述了,就是只执行一次prepare,只编译一次,节省了时间,但是我不明白,只编译一次,怎么绑进去不同的变量的,变量变了,不需要重新编译?可能和程序的编译概念(当然,程序也有运行时的变量和编译时写死的变量)不同?可能是某种专门的优化吧。另外,reset到底在循环内下一次bind前,是否需要执行(是!),是否能节省时间(否!)。
实测:如果你想插入不同数据,不reset是根本不行的,貌似并不存在重复bind就能覆盖前面的效果(内部实现虽然同样是修改内存,我没看太仔细,外部看,没有效果。)。最后,如果不reset,只bind()一次,for loop只有step(),貌似也并没有快(实测还慢了一秒,从7秒到8秒,从15秒到16秒),所以真的可能是prepare执行的少就能达到加速效果!!!
至于for循环内部也执行prepare,那就呢执行包裹好执行sqlite3_exec是一样的了
对比:不同方案的并发写入速度:
sqlite3_exec()10线程乘以500条,46秒
stmt模式 auto increment 表, sqlite3_step()10线程乘以500条,42秒
stmt模式 auto increment 表,不sqlite_reset(重复一样的数据), sqlite3_step()10线程乘以500条,43秒
stmt模式 非auto increment 表,不sqlite_reset(其实不reset逻辑是错误的,至少是不太现实的,也不能靠autoincrement实现主键变化,全一样的数据,只验证性能用), sqlite3_step()10线程乘以500条,41秒(快是快了,就是没意义)
stmt模式 非auto increment 表,sqlite_reset(计算id插入), sqlite3_step()10线程乘以500条,42秒(比较现实的方案,确实快了一点)
10*800:非auto increment,非stmt:68秒,stmt:64秒
10*800:auto increment,非stmt:69秒,stmt:67秒,不reset():67
15*1000:stmt:auto:
reset:127,不reset:127
15*5000:stmt:auto:
reset:651,不reset:651
小结:非auto increment更快,stmt更快,不reset基本也不会快(0.排除干扰,只有一次bind,for循环只有step(),并不是“虽然不reset,但还循环bind”的模式1.很难实际应用,2.可能reset和bind本身确实没什么开销,也算验证了那个prepare才是编译过程的“理论”),具体看情况选用方案。所以最现实的最快的是非autoincrement,使用stmt,一个prepare,循环内使用bind和reset。并发的话,没办法,必须用autoincrement,不然没法算id,或者每次插入前开个事务锁死,并且select count 一下。
锁的时机——代码调试用
pagerLockDb()好像是
测试经验
如果只看count来判断是否丢写入,要注意加primary key,好像同样的id输入两次也有!!!
多线程(分开的链接,独立open的)有的线程全成功,有的线程全弹21,线程间的不公平不确定什么导致的(也有全成功,比如慢一些的时候,所以不是外部代码的问题,是sqlite内部)
WAL:
宛如一个小型操作系统内存机构,页的映射,页的读写与更新,等等,不细说了。总之,利用尾部追加来加速和合并写操作,但是读操作因为要查询页表,可能会慢点。实际情况的快慢还要综合分析。
rollback与wal区别:前者,改写主db文件,留rollback回滚;后者,改写缓存wal文件,再整体提交(checkpoint或者backfill)写入磁盘(db文件)。
这里有个问题必须确认,并发才能安全,wal的缓存的底层支持问题,NFS和NTFS的区别。
PRAGMA journal_mode=WAL;
并发的致命缺点:访问数据库的所有程序必须在同一主机上,且支持共享内存技术。
对应的,delete模式:我后边实测,确实会慢,从原理上也好解释,wal是顺序写到wal文件里,到一个检查点一起插入;delete是每次插入都先把要改的old-page保存,再修改db文件,是两次fsync,还包含查找位置的开销(要写入的位置离散)。
wal刷写问题:
我又想了一下,同步节点的问题,思路是一样的,如果把wal关掉,改为共享db有问题,那么不关wal,光是复制,也是有问题(我们的业务下,默认的sqlite配置下)
wal的话,没做特别设置,那么复制的db,就不一定是正确的,我写的demo是这样的,wal的东西还没刷进db(默认1000页才刷),只复制一个db,东西是没有的,wal快就快在不每次都写db,而是写在wal,所以默认肯定不是每次都提交的。
两个方面解决,一是把wal也复制走,二是加一些手动的冲刷点。
DEMO复现BUG方法:新建一个db,指定为wal模式,随便新建表或者插入(别超过1000行,这是默认的checkpoint),然后复制db文件(不包含wal和shm文件)到新路径,sqlite打开,没有任何东西,复制wal和shm过来,就发现又有了。如果 先执行刷盘命令再只复制db文件到新路径,sqlite打开,东西也都在!改为C++程序写,stmt模式,带open和close,带prepare和finalize,全套,只要不超过1000,同样只复制db文件,一样的问题。
关于主动冲刷:命令是pragma wal_checkpoint(FULL),细节下边连接写的很好。
https://www.cnblogs.com/cchust/p/4754619.html

不过最后确定了,我自己的demo代码是多线程的,在主线程丢了一个close db,close db是能保证落盘的,所以如果工程中,所有数据库操作都有close()作为节点,那么下一步只复制db文件也没错(如果完整close,应该没有wal文件了)
SQLITE_BUSY超时重试
sqlite3_busy_timeout,这个指定的是总时间,重试间隔是内部自动的。
sqlite3_busy_handler 这个自己指定handle处理接口,自己的handle也可以什么都不做?返回错误码就继续重试?实测起来略麻烦。
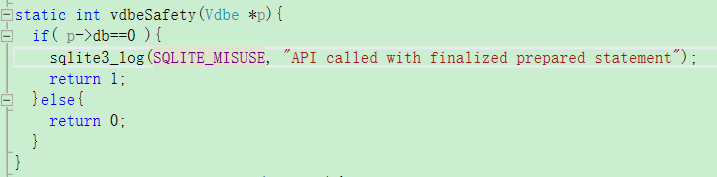
我遇到的关键问题
不加timeout就busy(errcode=5),
加timeout,超时设定很短,弹busy。
加timeout,超时很长,不弹busy,弹出misuse(21)。
timeout居中,可能两样都有,可能全通过,多进程高并发21会更多。
21理论上是sql语句错了(stmt不好看拼好的语句,都封装了),但是这个21实际上是并发触发的,代码本身应该没问题!!!
一个线程,一错就全都错,一个都不成功,和stmt本身有关系吗?因为我的循环内,stmt都被reset了,所以原来的stmt不存在,而他的回调和重试需要用到stmt???因为stmt指针对应的结构位置格式都一样,好像也不至于崩掉?只是信息和原来不同了?但是也不应该重试就用新的语句吧?所以就失败了?刚好大家的21都对应的语句错误?虽然msg说的还是db lock。
实测堆栈:
prepare堆栈
用了一个share的锁
> sqlite_demo.exe!pagerLockDb(Pager * pPager, int eLock) 行 51983 C
sqlite_demo.exe!pager_wait_on_lock(Pager * pPager, int locktype) 行 54747 C
sqlite_demo.exe!sqlite3PagerSharedLock(Pager * pPager) 行 55989 C
sqlite_demo.exe!lockBtree(BtShared * pBt) 行 66464 C
sqlite_demo.exe!sqlite3BtreeBeginTrans(Btree * p, int wrflag, int * pSchemaVersion) 行 66839 C
sqlite_demo.exe!sqlite3InitOne(sqlite3 * db, int iDb, char * * pzErrMsg, unsigned int mFlags) 行 124897 C
sqlite_demo.exe!sqlite3Init(sqlite3 * db, char * * pzErrMsg) 行 125082 C
sqlite_demo.exe!sqlite3ReadSchema(Parse * pParse) 行 125108 C
sqlite_demo.exe!sqlite3LocateTable(Parse * pParse, unsigned int flags, const char * zName, const char * zDbase) 行 108010 C
sqlite_demo.exe!sqlite3LocateTableItem(Parse * pParse, unsigned int flags, SrcList_item * p) 行 108071 C
sqlite_demo.exe!sqlite3SrcListLookup(Parse * pParse, SrcList * pSrc) 行 113006 C
sqlite_demo.exe!sqlite3Insert(Parse * pParse, SrcList * pTabList, Select * pSelect, IdList * pColumn, int onError, Upsert * pUpsert) 行 117972 C
sqlite_demo.exe!yy_reduce(yyParser * yypParser, unsigned int yyruleno, int yyLookahead, Token yyLookaheadToken, Parse * pParse) 行 153570 C
sqlite_demo.exe!sqlite3Parser(void * yyp, int yymajor, Token yyminor) 行 154496 C
sqlite_demo.exe!sqlite3RunParser(Parse * pParse, const char * zSql, char * * pzErrMsg) 行 155636 C
sqlite_demo.exe!sqlite3Prepare(sqlite3 * db, const char * zSql, int nBytes, unsigned int prepFlags, Vdbe * pReprepare, sqlite3_stmt * * ppStmt, const char * * pzTail) 行 125299 C
pagerLockDb
NT系统用sqlite封装的osLockFileEx(),否则用osLockFile()
step堆栈
观察到locktype,先SHARED_LOCK 1,后RESERVED_LOCK 2
newLocktype = RESERVED_LOCK;
sqlite3VdbeExec过程比较多,最后还会变成EXCLUSIVE_LOCK 4
> sqlite_demo.exe!winLockFile(void * * phFile, unsigned long flags, unsigned long offsetLow, unsigned long offsetHigh, unsigned long numBytesLow, unsigned long numBytesHigh) 行 43322 C
sqlite_demo.exe!winLock(sqlite3_file * id, int locktype) 行 44108 C
sqlite_demo.exe!sqlite3OsLock(sqlite3_file * id, int lockType) 行 22438 C
sqlite_demo.exe!pagerLockDb(Pager * pPager, int eLock) 行 51981 C
sqlite_demo.exe!sqlite3PagerBegin(Pager * pPager, int exFlag, int subjInMemory) 行 56656 C
sqlite_demo.exe!sqlite3BtreeBeginTrans(Btree * p, int wrflag, int * pSchemaVersion) 行 66845 C
sqlite_demo.exe!sqlite3VdbeExec(Vdbe * p) 行 87391 C
sqlite_demo.exe!sqlite3Step(Vdbe * p) 行 82300 C
sqlite_demo.exe!sqlite3_step(sqlite3_stmt * pStmt) 行 82366 C
sqlite_demo.exe!insert_busy_handle_child_thread(parameters p) 行 284 C++
> sqlite_demo.exe!sqlite3OsLock(sqlite3_file * id, int lockType) 行 22439 C
sqlite_demo.exe!pagerLockDb(Pager * pPager, int eLock) 行 51981 C
sqlite_demo.exe!pager_wait_on_lock(Pager * pPager, int locktype) 行 54747 C
sqlite_demo.exe!sqlite3PagerExclusiveLock(Pager * pPager) 行 57133 C
sqlite_demo.exe!vdbeCommit(sqlite3 * db, Vdbe * p) 行 79065 C
sqlite_demo.exe!sqlite3VdbeHalt(Vdbe * p) 行 79497 C
sqlite_demo.exe!sqlite3VdbeExec(Vdbe * p) 行 85027 C
sqlite_demo.exe!sqlite3Step(Vdbe * p) 行 82300 C
sqlite_demo.exe!sqlite3_step(sqlite3_stmt * pStmt) 行 82366 C
sqlite_demo.exe!insert_busy_handle_child_thread(parameters p) 行 284 C++
reset
主要看一下能不能跟踪到对stmt的改变,是不是一位内reset,busy handler收到了影响。
sqlite3VdbeReset,太乱了。。。。。跟不了。。。
所有misuse打断点
跟踪问题:改成单线程,逐步跟踪流程与机制
既然是misuse,sqlite3MisuseError
#define SQLITE_MISUSE_BKPT sqlite3MisuseError(__LINE__)
说明文档对这些的描述,就是方便你打断点。。。
根据log,我肯定不是这里
多线程插入
timeout设置很小(10)时,实际是vdbeUnbind报错,而且是循环的第一次,还没有reset过,只prepare,然后就是bind
再跑两次,符合预期,因为超时很小,都是返回busy。

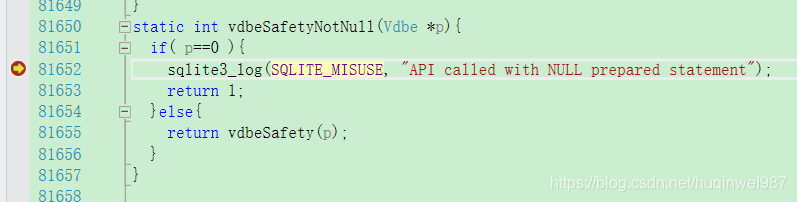
static int sqliteDefaultBusyCallback()有算法,粗看,前期好像是按一个队列逐渐增加等待,后期超时直接返回0(其实就是不管了)
(另一种回调sqlite3_busy_handler(),其实就是替换的这个接口,返回0成功,返回1重试,看来还是用timeout好一些)
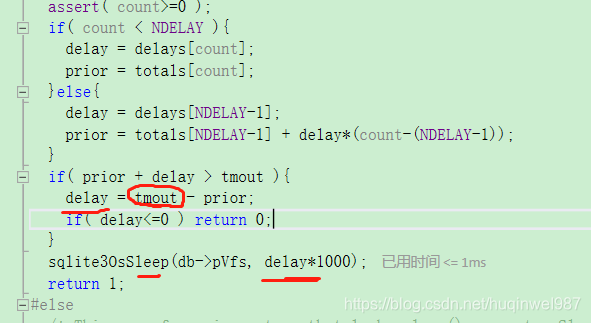
关于sqliteDefaultBusyCallback的堆栈

sqlite_demo.exe!sqliteDefaultBusyCallback(void * ptr, int count, sqlite3_file * pFile) 行 157790 C
> sqlite_demo.exe!sqlite3InvokeBusyHandler(BusyHandler * p, sqlite3_file * pFile) 行 157822 C
sqlite_demo.exe!btreeInvokeBusyHandler(void * pArg) 行 65701 C
sqlite_demo.exe!pager_wait_on_lock(Pager * pPager, int locktype) 行 54748 C
sqlite_demo.exe!sqlite3PagerSharedLock(Pager * pPager) 行 55989 C
sqlite_demo.exe!lockBtree(BtShared * pBt) 行 66464 C
sqlite_demo.exe!sqlite3BtreeBeginTrans(Btree * p, int wrflag, int * pSchemaVersion) 行 66839 C
sqlite_demo.exe!sqlite3VdbeExec(Vdbe * p) 行 87391 C
sqlite_demo.exe!sqlite3Step(Vdbe * p) 行 82300 C
sqlite_demo.exe!sqlite3_step(sqlite3_stmt * pStmt) 行 82366 C
sqlite_demo.exe!insert_busy_handle_child_thread(parameters p) 行 288 C++
timeout设置1000,同样出现busy,最终插入数量应该也是不全。会丢不少
timeout设置5000,busy少了很多(我感觉自动重试间隔和你设置的超时时间是有比例的),还是丢,24*500=12000,实际11913,接近了
timeout设置60*1000,超级多的misuse database is locked,实际写入更小了!,费解!
设置小了,超时就不写入了,设置大了,更写不进去,诡异。甚至说,同样的设定,用VS调试就能插入(应该是更慢了?忘了当时实测条件),用VS运行就不行!
最后双开进程,每个都开14个线程,有一个进程是大规模的报错21,misuse,db lock,但是后期是重试了,最终24000个数据(好像不对,我双开14线程,应该28000,应该还是丢了4个线程的数据)
可能超时设置的不够,进程运行超了1分钟,不保险,设10分钟试试
实测还是会有丢,猜测回调不具有存活能力,让线程多活一会,sleep一下。sleep什么用都没有,在close连接之前sleep也没用,经过断点观察,猜测是多线程,有的prepare失败了,所以整个线程都没插入,而我没给prepare设置handle,只是在循环前边设置了handle。(初代demo死活想不到prepare还会失败的,还好多打了断点)
在更早的位置使用timeout函数,现在单机多线程多进程插入都成功了!
demo后续
首先改成网络版本,改路径,远程打开数据库,测试多机共同写入。
关于db名的拼写,一直打不开,对比一下现有工程,或者跟踪一下报错信息。
然后,对比一下工程用的sqlite3_open_v2()和默认用的sqlite3_open()的区别。
最后,把原工程加上timeout测试实际效果。
对原分布式工程进行修改
前边该试验的都试验了,该对我本来的工程进行修改了,实际上重写机制是没多大问题,问题出在速度上。在使用DELETE模式替换WAL模式后,有些写入步骤几乎没有差别,但是有个别阶段,时间明显被延长了。当然,这也需要我再细化一下具体工程逻辑去定位慢在哪,但是说明delete把wal确实慢。
这就难了,wal不保险,delete慢,只能两个角度看,代码能不能优化?wal能否改的更保险(比如不同阶段的同步控制,通过主动checkpoint来避免分布式有不同步问题)
wal的可调整项:wal_autocheckpoint=1000和journal_size_limit=1000,好像是不怎么灵活,是一次性的设定?而不是手动提交,这样应该大了还是不能控制节点,小了一样会很慢。
理清思路以后,看了一下现阶段的分布式方案:前三步写入db的操作只能有一个进程操作,后边多进程并发是复制db到本地,要想达到不复制db到本地(占用大量空间)的目的,共享一个主机db,确实按现阶段流程是可以控制的,一些关键节点主动用wal checkpoint就行了,这样就能继续用wal模式保证速度,同时节省空间。
但是长久看,为了加速,所有过程都可能要做分布式,一旦要并发写入,那么跨主机肯定不能wal了,而且NFS下,是否wal,sqlite都不太稳妥,所以临时方案也先不做了,以后迁移mysql(还要确定大数据量下,几十个机器共同访问一个mysql是否比现在复制db到本地的方案更快)。
重点:我们是用分布式加速一个程序的一整套流水过程,不是专门做服务器,所以很多方面和业务细节需要考虑,如果一个方案,看起来很稳,但是实测不加速,可能减速,这个方案就不能用。
todo:不管用不用sqlite做分布式,这两个问题我还是可以再测试一下,1.手动冲刷wal日志的操作,2.多主机并发wal的后果。
----------------------------
-----------------------------------------------------------------------------------------
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
其他
根据我之前的经验,我们的多进程会发生busy的问题,并且busy的后果是操作失败。以前以为是trans粒度大导致互斥,如果代码中transaction并不是显性immediate的,那么改trans粒度并不加快或者减慢速度,而且也仍然治不好busy的问题。

我要处理的工程里边有些读过程出现了锁,这个很奇怪,但是实际代码就如上图,是默认的begin,也就是deferred模式,内部也没有写操作,按理说虽然显式地begin一个事务,但是事务没有升级锁状态,不应该产生一个独占区间。目前没看到有资料显示可以提前设置默认的begin模式,以至于begin不是deferred模式。有吗?
使用autoincrement,不指定primary key,timeout是否会导致插入过多?
早期代码写错,确实遇到过,那时候有的线程不工作(prepare失败),有的线程可能重复插入了,当时通过指定primary key避免了,现在模拟实际情况,是不指定id的自由插入,primary key+auto increment,实测,暂时还没发现多插入的现象。
create table if not exists t1 (id integer primary key autoincrement, x integer , y integer, weight real)如何不指定主键?我暂时是这样做的,也不知道bind null算是绑了0还是-1(实际手写这两个值都不行),总之能保证正确插入,
INSERT INTO t1 (id,x, y, weight) VALUES(?,?,?,?);sqlite3_bind_null(stmt, nCol++);哦,原来就是null
INSERT INTO t1 (id,x, y, weight) VALUES(null,1,1,1);
自动优化
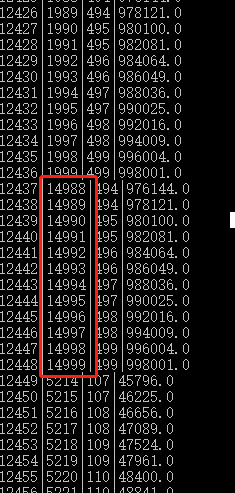
实测,for循环bind-step-reset,不结束不finalize,2进程*8线程*1000个循环==16000次插入,他还是大概会每个线程连续插入500次(不绝对,也有的过程十来次)
当然,这个过程怎么解释,也保留只是线程按时间片来回切换的可能性,而与sqlite的优化无关。
第一列是自增主键,第二列是每个线程自己觉得自己应该是什么id(不自增的时候用来让并发进程线程覆盖所有id用的,现在用来观察并发过程)
sqlite3_exec()与stmt模式下sqlite3_step()、sqlite3_finalize()等接口的关系,其实exec是这几个函数的打包封装接口。
select 多个返回
需要多次执行sqlite3_step(),每次SQLITE_ROW,直到SQLITE_DONE
附录:其实网上所有帖子基本都是官方说明的翻译,还有源码注释
比较详细的wal过程:但是图缺失
https://www.2cto.com/database/201604/497268.html
官方的原子提交的说明:文章右侧有配图,也比较全,但是内容比较长,英文的。
https://www.sqlite.org/atomiccommit.html
官方多线程说明:
https://www.sqlite.org/threadsafe.html
官方FAQ:
https://www.sqlite.org/faq.html#q19
第五个问题,是我关心的:多应用,多例程,访问同一个db文件。
描述的情形和多线程也差不多,可以同时打开同时查询,只有一个能改写。
reader/writer锁控制db的访问。(win Me以前的功能差一些)NFS可能支持不太好(针对的不只是win me)?!!!!
fcntl() 文件锁在NFS可能是坏的!
多进程访问sqlite,db文件不应该在NFS系统上。
微软文档说明:没有Share.exe的话,FAT的locking都可能失灵。
工程人员的经验之谈:网络文件的file locking特别不可靠,bug多。(但是这里作者用了if,)
剩下就是一些作者的絮叨,比如大并发推荐你用mysql之类的(他们的先天优势:网络通信,只有单机单进程访问数据库,安全可控),但是其实你的实际需求远比你想象的小之类的(还是忽悠你用sqlite)。。
sqlite原则上是支持多进程并发,就是NFS文件系统坑了!!
但是我又想了一下,现在的windows主流是NTFS,是否能等同NFS的缺陷?不确定,NTFS+fcntl()这方面资料貌似也不多,还需要查证,但是这是最关键的一点,如果NTFS和NFS一样,那么跨进程跨系统就废了。
至少目前我表面遇到的现象倒是还正常,我遇到SQLite_BUSY说明他的锁暂时还是起作用的,可靠不可靠就不清楚了。全看NTFS。
补充:有些歧义:NFS是特指linux的NFS协议吗?还是所有?windows好像是SMB,作者专门提到windowsFAT有问题,其他的,好像也不行(network files还是不行,作者还说了个if,真坑):
People who have a lot of experience with Windows tell me that file locking of network files is very buggy and is not dependable. If what they say is true, sharing an SQLite database between two or more Windows machines might cause unexpected problems.
WAL性能测试,有一些详细对比,可能参考的上。
https://www.cnblogs.com/cchust/p/4754580.html
一些编译问题,我感觉问题不大,反正就是头文件和源文件放好,就能编译成功
http://www.360doc.com/content/14/0416/19/8425146_369537570.shtml
底层机制:NFS+RPC/SMB+fcntl()
有人说网络邻居是smbhttps://zhidao.baidu.com/question/36003005.html
不过我也遇到一个情况,网络邻居是共享了,但是sqlite却没能跨主机访问目标db(ip地址+目录,同样地址在资源浏览器可以打开,不过很奇怪的是,我们的大的分布式工程,同样的地址格式,就能跨主机访问)
我现在也不确定当作者提到NFS,到底是专指linux/unix的协议NFS,还是指网络文件系统的概念(包括SMB)。
附录:sqlite和mysql的对比
sqlite优势:磁盘效率、小型化,也可多终端打开,多进程(多机就不行了)
sqlite劣势:无用户管理,无法跨主机并发访问(可以,但是不可靠,不可预知结果)
mysql优势:有用户管理,单进程管理数据库,不跨主机(其他的进程通过网络接口访问,相当于mysql有一个专门的守护程序,而sqlite缺这么一个机制),安全,表级互斥(前者库级互斥)。比较全面、综合,适合并发,其他一些细节就不说了,什么安装容易、三方库、可视化。
mysql:某些场景某些操作,可能没有sqlite那么快(当然,这个还是要实测才能确定),和标准SQL的语法兼容性(次要),mysql服务器要占用硬盘空间安装(相比sqlite遇到的问题和实际数据量,这几百兆接受)。
转mysql的必要理由:sqlite在NFS下不可靠,很好理解,锁是系统内的机制,跨系统的话,就要看文件系统的支持了,如果不行,明显是没法互斥的。
何止数据库
我自己的这个工程,他本身的“分布式”做的很简陋,如果sqlite的NFS文件锁不可靠,那么这个工程的分布式基础——文件锁——就不可靠。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









