






文章目录
- 介绍:
- A Simple Predicting Machine
- Classifying is Not Very Different from Predicting
- Sometimes One Classifier Is Not Enough
- Following Signals Through A Neural Network
- Matrix Multiplication is Useful..Honest!
- A Three Layer Example with Matrix Multiplication
- Learning Weights From More Than One Node
- Backpropagating Errors From More Output Nodes
- Backpropagating Errors To More Layers
- Backpropagating Errors with Matrix Multiplication
- How Do We Actually Update Weights?
- Weight Update Worked Example
- Preparing Data
- Part 2 - DIY with Python
- Part 3 - Even More Fun
极力推荐想学习神经网络的朋友一本书—— Make Your Own Neural Network。这本书显示图文并茂的讲述了神经网络的工作原理,然后又一步一步的用Python搭建了一个简单的双层神经网络,最后还给了一个神经网络应用的例子。我也是神经网络的初学者,怀着对作者的敬意,我简单的翻译了这本书的部分内容。
本博客作为翻译系列的开篇之作,只是介绍了一下该书的行文结构。也就是说,这里我会按照原著中的目录编排,进行简单的翻译和解释。
声明:
- 这篇博客不尽详细,敬请包涵
- 如果您已经对神经网络有所了解,该文章会帮你迈向更全面的境界
- 后面的三篇博客会对该书中构建和训练神经网络的代码做详细的介绍
- 更新,增加了一些原创的东西。
补充:概述英文版PDF下载链接:https://pan.baidu.com/s/1-Qdb8gPVnQGSohDhgeoA4g 密码:kwmc
介绍:
What will we do?
创建一个用来进行手写汉字识别的神经网络。
How will we do?
本书分为三部分
- 简单神经网络的数学原理。
- 借助Python搭建简单的手写汉字识别应用
- 进一步第2步搭建的网络的功能
A Simple Predicting Machine
人类是如何进行预测的?无非是根据以往的事实得出的经验。经验是如何来的,一方面是他人传授的经验,另一方面是我们的社会实践。而他人的经验是怎么得来的?追根溯源都是祖先进行实践,也就是一点一点的试错,得来的。那么,让我们设想一个简单的预测机的工作方式(左边是机器的模式,右边是对比人类实践的模式):
- 提出假设——进行尝试
- 验证假设——得出结果(对/错)
- 修正假设——得到经验(可能是错误的经验)
- 不断循环1、2、3步,生成最终结果——得到靠谱的经验
第三步是最关键的一步。在这一步中,如何修正假设,需要引入一个概念——error(误差)。
预测错了,机器就要进行改进,如此往复才能使得error不断减小。error接近0时就得到了正确的预测。
How much we nudge the error?直观的认识是:误差越大,修改参数的幅度越大;反之,越小。这也是当前解决人工智能问题的主流方法。
Classifying is Not Very Different from Predicting
由预测机到分类器,两者并不相同。
- 有一条线或超平面(关系映射,输入-输出)可以建立输入和输出的关系,视为预测机
- 有一条线或超平面(关系映射,还是输入与输出,但此时的输出是标签,也算是预测值的一种)可以通过输出的标签区分不同的输入,视为分类器
其实,这里的预测机就是我们机器学习中常说的回归。分类和回归,这样是不是熟悉了很多O(∩_∩)O 广义而言,分类也是回归的一种,即回归只能取标签值的情况(二分类就是0、1,多分类就是0、1、2……)。Logistic回归就是用回归来解决分类问题的典型。
误差 = 期望值 - 当前输出值
此处的期望值不同于预测机的期望值:分类器的期望是要能够区分该样本点的同类与异类的;预测机要得出预测值比该点的实际y值偏大或偏小。
举个例子,分类器的二分类问题,真实y值的值域是{0,1},分类器分类输出的值域也是{0,1}。但是预测机预测的时候,这是y值的值域就是[0, 1],预测的值域也是[0, 1]。
影响参数值调整的快慢
分类器的调参方式和预测机相似
调参时,机器会比较天真地只针对最后输入的样本,忽视之前的样本。解决之道是引入学习率,让之前的样本对后面的调参产生影响(影响大小随学习率变化)
引入学习率,和适时调参(包括最常见的梯度下降算法等)可以有效规避现实样本数据中的噪声和异常值。
看不懂的小白看这里:
- 参数值是什么?我们认为分类器是一个人工的神经元节点,而这个神经网络的本质是很多的内置函数及其参数组成的。
- 内置函数就是Logistic回归和激活函数,这里后面还会讲的,不急哈
- 调参?首先,所谓模型就是y=f(x)中的f(),给定输入x,就可以得到结果y。对于本文中的主题神经网络来说,网络结构和参数可以确定唯一的f()。其中网络结构和输入x、输出y是一开始就定好的,这一步的调参就是要通过真实值 y y y和预测值 y ^ \hat y y^得到的error来调整f()的参数。
- 机器会比较天真?也就是说,机器如何储存之前学习的经验呢?如果每次都不记得之前的“教训”,每次分类错误,点点头就过去了,那岂不永远都学不会东西。解决方案就是:不对神经网络中的f()的参数进行重置,每次调参都是在原来的参数上进行改变,这样机器就记住了之前的教训了。
- 规避现实样本中的噪声和异常值。首先,分类器根据原来的模型参数和输入x输出分类结果 y ^ \hat y y^。然后,得到error=y - y ^ \hat y y^,根据error的大小,调整模型参数以改善模型的分类能力。但是,一方面现实的样本也是有多样性的,另一方面还会有错误样本的情况,所以一步到位的根据error进行调参是不可取的。应该用lr进行一点一点的调参,逼近正确结果才对。
Sometimes One Classifier Is Not Enough
大多数情况下,一个神经元的功能还是太简单,不能满足实际需要。
一个简单的线性分类器不能分别非线性分布的数据,比如异或数据不能用一条直线分开
这时候,解决方法也很直白,就是用多个简单的分类器组合(人多力量大嘛)。比如上面的异或问题,用两条直线就能解决了。
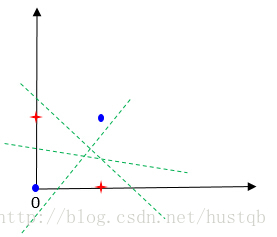

然后介绍仿真的神经网络模型,主要组成部分:输入、线性回归函数 y = w x + b y = wx + b y=wx+b及其传输权重(与阈值合称神经网络参数,也就是后面的参数矩阵)、激活函数(起源是Sigmoid函数,现在多用ReLU函数)及其激励阈值、输出。至此,所谓深度学习也就初露头角了,本质就是很多层的神经元相连接(越深学习效果越好,但是学习时间越长)。
尽管生物大脑相较于计算机,它的存储空间小、运行速度满,但它似乎可以完成一些像认路、觅食、学习语言、逃脱危险之类的复杂任务。
生物大脑也可以很好的处理异常输入,这点很不可思议,而且对于计算机来说很难做到。
人工神经网络就是仿照生物大脑来的。下图是一个神经元。
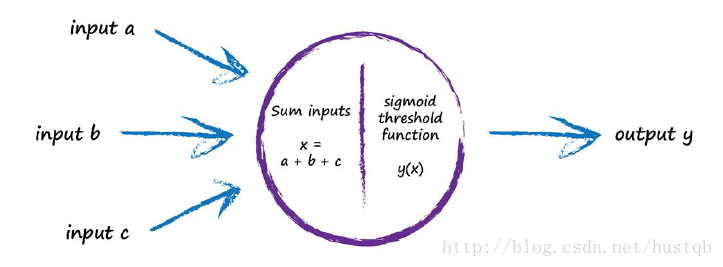
Following Signals Through A Neural Network
神经网络的工作流程(信号如何传递和产生作用的)。其工作主要有三部分,正向传递信号,反向传递误差,调整参数。当然,这个有三部分组成的工作要不停的迭代(既包括对所有样本的迭代,要包括循环学习(由参数epochs决定))
下图是信号在神经网络中的正向传递:
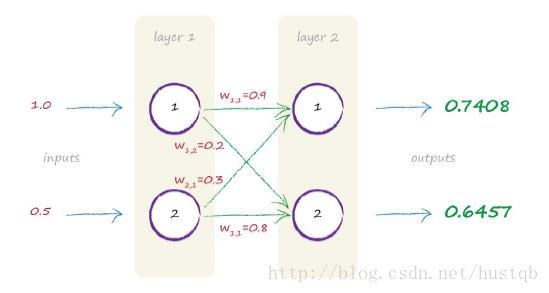
Matrix Multiplication is Useful…Honest!
神奇的矩阵,矩阵相乘完美诠释全连接(后面的很多其他网络结构也可以用矩阵中不同的计算方式完美诠释)。
比如上图中的信号正向传递的表示方式:
Y
=
W
X
Y = WX
Y=WX
其中,
Y
=
[
y
1
y
2
]
Y = \begin{bmatrix}y1\\ y2\end{bmatrix}
Y=[y1y2],
W
=
[
w
11
w
12
w
21
w
22
]
W = \begin{bmatrix}w11 & w12\\ w21 & w22\end{bmatrix}
W=[w11w21w12w22],
$X =\begin{bmatrix}x1\ x2\end{bmatrix} $。
将实际值带入之后,
$\begin{bmatrix}0.7408\ 0.6457\end{bmatrix} = \begin{bmatrix}0.4 &0.2\ 0.3 &0.8\end{bmatrix} \cdot \begin{bmatrix}1.0\ 0.5\end{bmatrix} $
神经网络中,信号前向传递的计算可以表示成矩阵相乘
如上所述会让我们的工作更简洁
更重要的是,便于计算机的理解和计算。
A Three Layer Example with Matrix Multiplication
举了一个简单的三层网络中信号前向传递的例子。
Learning Weights From More Than One Node
现在考虑的问题是,如何调整参数,使输入经过网络之后的输出接近真实值。
一个输入对应一个输出的时候很容易通过误差调整参数,那么多输入的时候呢? 可以按上一次迭代的权值按比例分配error
backpropagation反向传播算法:
第一部分,根据神经网络中的参数正向传播,输入产生输出
第二部分,根据输入与理论值之间的误差,反向传播调整参数
Backpropagating Errors From More Output Nodes
反向传播算法只关注与输出相联系的输入
Backpropagating Errors To More Layers
误差在层间反向传播
神经网络通过调参进行学习
输出层的误差就是预测值与理论值的差值
然而,与内部节点相关的误差并不明显。 一种方法是将输出的误差按输入链接的权重进行分配,然后再对上一层的神经网络进行重新计算(下一层的输入就是上一层的输出)
Backpropagating Errors with Matrix Multiplication
用简单的矩阵相乘的方式来描述误差的反向传递
反向传播误差可以被标示为矩阵相乘
这可以简化网络表示和计算机工作量
现在,不管是信号的正向还是误差的逆向传递,都有了矩阵相乘的表示。
How Do We Actually Update Weights?
通过梯度下降找局部最小值,然后再通过其他方式(创意)尽量找到全局最优点或者挑出局部最优点
梯度下降是计算函数最小值的好方法,并且适用于各种复杂的函数
同时,对多参数的情况下,效果也很好
梯度下降也在一定程度上规避函数错误所带来的错误
梯度的计算公式
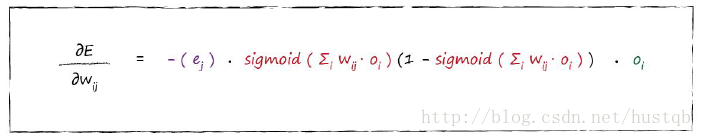
学习率的作用
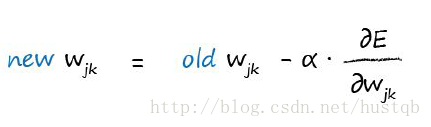
最后得到权值参数的调整大小
神经网络的误差是网络中链接的权重参数的函数
优化一个神经网络就是减小它的误差
直接选择一组合适的参数很难实现。所以,我们需要通过迭代的方式,一步步调整参数直至最优,也就是梯度下降算法
误差的计算一般不会复杂
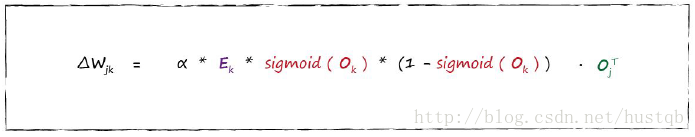
Weight Update Worked Example
例子
Preparing Data
inputs——归一化
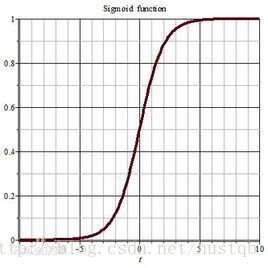
由于我们采用的是梯度下降算法,当输入对应于激励函数的平滑部分时,效果会很差。避免这种情况,比如归一化
这里的意思是说,对于如下图所示的Sigmoid函数,当自变量的取值过大或过小时,梯度会趋近于0,导致学习效果缓慢,甚至使loss函数的优化陷入局部最小值。
outputs——值域问题
不要超过激励函数的值域
random initial weight——权重的随机初始化
初始化权值参数时也有一定的规律。理论上初始权值会趋近于零,但等于零会造成很坏的结果。
如果输入、输出和初始权值不适合网络结构的话,神经网络就不能好好工作
避免饱和行为,因为这会降低网络的学习能力
避免零输入,应为这会完全破坏网络的学习能力
初始权值应该是随机的小数值,非零。
输入应该是小数值,非零。【0.01, 0.99】或【-1, 1】,根据实际情况而定
输出应该在激励函数的值域内。可选【0.01, 0.99】
其实在实际应用中,输入输出在[0, 1]就好了,因为只有当输入全是0的情况下,神经网络的训练才会出问题,但是这种概率很小。
Part 2 - DIY with Python
神经网络的定义:初始化函数、训练函数、获得输出的函数
initialising the network
初始化函数中添加:输入个数、输出个数、隐层个数、学习率
weights - the heart of the network
初始化函数中添加:初始权值(两个随机化矩阵)
optional: more sophisticated weights
更复杂也更合理的初始化权值的方式
querying the network
输入→隐层→输出 需要用矩阵相乘和激活函数一步一步得出 初始化函数中添加:激励函数(为了方便更换激励函数)
the code thus far
训练函数:像query()那样的信号正向传播;误差反向传播(backpropagating) 文章中作者试运行了一下已完成的功能
training the network
关键1:
关键2:

the complete neural network code
点击跳转至github完整代码
PS:
github中的代码有一个错误:
self.activation_function = lambda x: scipy.special.expit(x)
要改为
self.activation_function = lambda x: expit(x)
The MNIST Dataset of Handwritten Numbers
手写数字识别
实践表明:
神经网络的准确率随学习率是一个先升后降的趋势
神经网络的准确率随迭代次数也是一个先升后降的趋势
神经网络的准确率随隐层神经元个数的增多而增多,并最后趋于稳定
Part 3 - Even More Fun
Your Own Handwriting
自己的手写数字数据集
Inside the Mind of a Neural Network
探索层间的输出
Creating New Training Data: Rotations
对训练集做一些改变,比如旋转,会提高最后的准确率。其实就是因为增多了训练数据的种类()而非单纯的数目)。















 1096
1096

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









