







本文转载自:
http://blog.csdn.net/sloanqin/article/details/51545125
【说明】:欢迎加入:faster-rcnn 交流群 238138700,我想很多人在看faster-rcnn的时候,都会被RPN的网络结构和连接方式纠结,作者在文中说的不是很清晰,这里给出解析;
【首先】:大家应该要了解卷积神经网络的连接方式,卷积核的维度,反向传播时是如何灵活的插入一层;这里我推荐一份资料,真是写的非常清晰,就是MatConvet的用户手册,这个框架底层借用的是caffe的算法,所以他们的数据结构,网络层的连接方式都是一样的;建议读者看看,很快的;
下载链接:点击打开链接
【前面5层】:作者RPN网络前面的5层借用的是ZF网络,这个网络的结构图我截个图放在下面,并分析下为什么是这样子的;
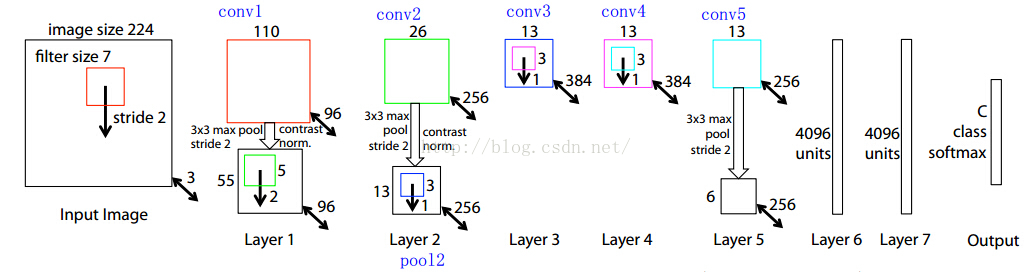
1、首先,输入图片大小是 224*224*3(这个3是三个通道,也就是RGB三种)
2、然后第一层的卷积核维度是 7*7*3*96 (所以大家要认识到卷积核都是4维的,在caffe的矩阵计算中都是这么实现的);
3、所以conv1得到的结果是110*110*96 (这个110来自于 (224-7+pad)/2 +1 ,这个pad是我们常说的填充,也就是在图片的周围补充像素,这样做的目的是为了能够整除,除以2是因为2是图中的stride, 这个计算方法在上面建议的文档中有说明与推导的);
4、然后就是做一次池化,得到pool1, 池化的核的大小是3*3,所以池化后图片的维度是55*55*96 ( (110-3+pad)/2 +1 =55 );
5、然后接着就是再一次卷积,这次的卷积核的维度是5*5*96*256 ,得到conv2:26*26*256;
6、后面就是类似的过程了,我就不详细一步步算了,要注意有些地方除法除不尽,作者是做了填充了,在caffe的prototxt文件中,可以看到每一层的pad的大小;
7、最后作者取的是conv5的输出,也就是13*13*256送给RPN网络的;
【RPN部分】:然后,我们看看RPN部分的结构:

1、前面我们指出,这个conv feature map的维度是13*13*256的;
2、作者在文章中指出,sliding window的大小是3*3的,那么如何得到这个256-d的向量呢? 这个很简单了,我们只需要一个3*3*256*256这样的一个4维的卷积核,就可以将每一个3*3的sliding window 卷积成一个256维的向量;
这里读者要注意啊,作者这里画的示意图 仅仅是 针对一个sliding window的;在实际实现中,我们有很多个sliding window,所以得到的并不是一维的256-d向量,实际上还是一个3维的矩阵数据结构;可能写成for循环做sliding window大家会比较清楚,当用矩阵运算的时候,会稍微绕些;
3、然后就是k=9,所以cls layer就是18个输出节点了,那么在256-d和cls layer之间使用一个1*1*256*18的卷积核,就可以得到cls layer,当然这个1*1*256*18的卷积核就是大家平常理解的全连接;所以全连接只是卷积操作的一种特殊情况(当卷积核的大小与图片大小相同的时候,从卷积层连接到全连接层;当卷积核大小是1*1的时候,从全连接层连接到全连接层);
4、reg layer也是一样了,reg layer的输出是36个,所以对应的卷积核是1*1*256*36,这样就可以得到reg layer的输出了;
5、然后cls layer 和reg layer后面都会接到自己的损失函数上,给出损失函数的值,同时会根据求导的结果,给出反向传播的数据,这个过程读者还是参考上面给的文档,写的挺清楚的;
【作者关于RPN网络的具体定义】:这个作者是放在./models/pascal_voc/ZF/faster_rcnn_alt_opt/stage1_rpn_train.pt 文件中的;
我把这个文件拿出来给注释下:
ps:等源码看完之后,我再注释得更详细些;
作者:香蕉麦乐迪--sloanqin-覃元元















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









