






logistic regression现在基本上用不到了,很naive了
用于分类模型的loss函数
Cross Entropy 交叉熵
熵,也叫作不确定性
熵越大,约稳定,不确定性越小
cross entropy是跟softmax搭配的,用于classification的loss函数
(在信息论中学过)
one-hot encoding就是01编码
对于one-hot encoding,H(p,q) = Dkl(p|q)
KL divergence就是相对熵
p和q越相近,相对熵越接近于0
p和q的分布越来越接近,这恰好就是我们classification模型所要优化的目标
二分类问题
二分类问题的目标函数就是 -[ylog(p)+(1-y)log(1-p)]
一个五分类问题的示例
预测一只dog
P值就是Pr,就是我们真实的分布
Q值就是Pθ,就是我们模型的分布
目前Q值模型的预测是对的,但是置信度不高
我们看一下它的cross entropy
而我们真正想要的情况是
我们优化的过程就是从0.9下降到0.02的过程
主流的神经网络结构




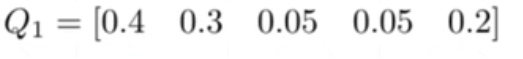



多分类问题实战
10分类
@是矩阵相乘
w1, b1 = torch.randn(200, 784, requires_grad=True),\ torch.zeros(200, requires_grad=True) w2, b2 = torch.randn(200, 200, requires_grad=True),\ torch.zeros(200, requires_grad=True) w3, b3 = torch.randn(10, 200, requires_grad=True),\ torch.zeros(10, requires_grad=True) def forward(x): x = x@w1.t() + b1 x = F.relu(x) x = x@w2.t() + b2 x = F.relu(x) x = x@w3.t() + b3 x = F.relu(x) return x
在pytorch中,第一个维度是out的,第二个维度是in的
如w1,b1,输入时784,降维成200
第二层是200,200,没有一个降维的过程,它并不是没有作用,只不过是没有降维
第三层是200,10,因为我们做的是10分类,所有最后的输出节点一定是10个
之后就是forward过程
优化器优化的是三组全连接层的变量w1,b1,w2,b2,w3,b3
完整程序是这样
import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optim from torchvision import datasets, transforms batch_size=200 learning_rate=0.01 epochs=10 train_loader = torch.utils.data.DataLoader( datasets.MNIST('dataset/', train=True, download=True, transform=transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,)) ])), batch_size=batch_size, shuffle=True) test_loader = torch.utils.data.DataLoader( datasets.MNIST('dataset/', train=False, transform=transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,)) ])), batch_size=batch_size, shuffle=True) w1, b1 = torch.randn(200, 784, requires_grad=True),\ torch.zeros(200, requires_grad=True) w2, b2 = torch.randn(200, 200, requires_grad=True),\ torch.zeros(200, requires_grad=True) w3, b3 = torch.randn(10, 200, requires_grad=True),\ torch.zeros(10, requires_grad=True) # torch.nn.init.kaiming_normal_(w1) # torch.nn.init.kaiming_normal_(w2) # torch.nn.init.kaiming_normal_(w3) def forward(x): x = x@w1.t() + b1 x = F.relu(x) x = x@w2.t() + b2 x = F.relu(x) x = x@w3.t() + b3 x = F.relu(x) return x optimizer = optim.SGD([w1, b1, w2, b2, w3, b3], lr=learning_rate) criteon = nn.CrossEntropyLoss() for epoch in range(epochs): for batch_idx, (data, target) in enumerate(train_loader): data = data.view(-1, 28*28) logits = forward(data) loss = criteon(logits, target) optimizer.zero_grad() loss.backward() # print(w1.grad.norm(), w2.grad.norm()) optimizer.step() if batch_idx % 100 == 0: print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format( epoch, batch_idx * len(data), len(train_loader.dataset), 100. * batch_idx / len(train_loader), loss.item())) test_loss = 0 correct = 0 for data, target in test_loader: data = data.view(-1, 28 * 28) logits = forward(data) test_loss += criteon(logits, target).item() pred = logits.data.max(1)[1] correct += pred.eq(target.data).sum() test_loss /= len(test_loader.dataset) print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format( test_loss, correct, len(test_loader.dataset), 100. * correct / len(test_loader.dataset)))是用交叉熵作损失函数的
可以看到结果一直不动了
如果我们加上初始化
import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optim from torchvision import datasets, transforms batch_size=200 learning_rate=0.01 epochs=10 train_loader = torch.utils.data.DataLoader( datasets.MNIST('dataset/', train=True, download=True, transform=transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,)) ])), batch_size=batch_size, shuffle=True) test_loader = torch.utils.data.DataLoader( datasets.MNIST('dataset/', train=False, transform=transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,)) ])), batch_size=batch_size, shuffle=True) w1, b1 = torch.randn(200, 784, requires_grad=True),\ torch.zeros(200, requires_grad=True) w2, b2 = torch.randn(200, 200, requires_grad=True),\ torch.zeros(200, requires_grad=True) w3, b3 = torch.randn(10, 200, requires_grad=True),\ torch.zeros(10, requires_grad=True) torch.nn.init.kaiming_normal_(w1) torch.nn.init.kaiming_normal_(w2) torch.nn.init.kaiming_normal_(w3) def forward(x): x = x@w1.t() + b1 x = F.relu(x) x = x@w2.t() + b2 x = F.relu(x) x = x@w3.t() + b3 x = F.relu(x) return x optimizer = optim.SGD([w1, b1, w2, b2, w3, b3], lr=learning_rate) criteon = nn.CrossEntropyLoss() for epoch in range(epochs): for batch_idx, (data, target) in enumerate(train_loader): data = data.view(-1, 28*28) logits = forward(data) loss = criteon(logits, target) optimizer.zero_grad() loss.backward() # print(w1.grad.norm(), w2.grad.norm()) optimizer.step() if batch_idx % 100 == 0: print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format( epoch, batch_idx * len(data), len(train_loader.dataset), 100. * batch_idx / len(train_loader), loss.item())) test_loss = 0 correct = 0 for data, target in test_loader: data = data.view(-1, 28 * 28) logits = forward(data) test_loss += criteon(logits, target).item() pred = logits.data.max(1)[1] correct += pred.eq(target.data).sum() test_loss /= len(test_loader.dataset) print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format( test_loss, correct, len(test_loader.dataset), 100. * correct / len(test_loader.dataset)))效果就变得很好了
这里用的是何恺明的初始化代码
所以初始化很重要!!初始化很重要!!初始化很重要!!



















 5846
5846











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









