







这在不同类之间提供了连续的数据样本,直观地扩展了给定训练集的分布,从而使网络在测试阶段更加健壮。
mixup之后的bbox就是2张图的bbox都有
import os import ast from collections import namedtuple import numpy as np # linear algebra import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv) from tqdm import tqdm from PIL import Image import joblib from joblib import Parallel, delayed import cv2 import albumentations from albumentations.pytorch.transforms import ToTensorV2 from albumentations.core.transforms_interface import DualTransform from albumentations.core.bbox_utils import denormalize_bbox, normalize_bbox from sklearn.model_selection import StratifiedKFold import torch from torch.utils.data import DataLoader, Dataset import torch.utils.data as data_utils from matplotlib import pyplot as plt import matplotlib.patches as patches from matplotlib.image import imsave def get_bbox(bboxes, col, color='white'): for i in range(len(bboxes)): # Create a Rectangle patch rect = patches.Rectangle( (bboxes[i][0], bboxes[i][1]), bboxes[i][2] - bboxes[i][0], bboxes[i][3] - bboxes[i][1], linewidth=2, edgecolor=color, facecolor='none') # Add the patch to the Axes col.add_patch(rect) class WheatDataset(Dataset): def __init__(self, df): self.df = df self.image_ids = self.df['image_id'].unique() def __len__(self): return len(self.image_ids) def __getitem__(self, index): image_id = self.image_ids[index] image = cv2.imread(os.path.join(BASE_DIR, 'train', f'{image_id}.jpg'), cv2.IMREAD_COLOR) image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB).astype(np.float32) image /= 255.0 # Normalize # Get bbox coordinates for each wheat head(s) bboxes_df = self.df[self.df['image_id'] == image_id] boxes, areas = [], [] n_objects = len(bboxes_df) # Number of wheat heads in the given image for i in range(n_objects): x_min = bboxes_df.iloc[i]['x_min'] x_max = bboxes_df.iloc[i]['x_max'] y_min = bboxes_df.iloc[i]['y_min'] y_max = bboxes_df.iloc[i]['y_max'] boxes.append([x_min, y_min, x_max, y_max]) areas.append(bboxes_df.iloc[i]['area']) return { 'image_id': image_id, 'image': image, 'boxes': boxes, 'area': areas, } def collate_fn(batch): images, bboxes, areas, image_ids = ([] for _ in range(4)) for data in batch: images.append(data['image']) bboxes.append(data['boxes']) areas.append(data['area']) image_ids.append(data['image_id']) return np.array(images), np.array(bboxes), np.array(areas), np.array(image_ids) def mixup(images, bboxes, areas, alpha=1.0): """ Randomly mixes the given list if images with each other :param images: The images to be mixed up :param bboxes: The bounding boxes (labels) :param areas: The list of area of all the bboxes :param alpha: Required to generate image wieghts (lambda) using beta distribution. In this case we'll use alpha=1, which is same as uniform distribution """ # Generate random indices to shuffle the images indices = torch.randperm(len(images)) shuffled_images = images[indices] shuffled_bboxes = bboxes[indices] shuffled_areas = areas[indices] # Generate image weight (minimum 0.4 and maximum 0.6) lam = np.clip(np.random.beta(alpha, alpha), 0.4, 0.6) print(f'lambda: {lam}') # Weighted Mixup mixedup_images = lam*images + (1 - lam)*shuffled_images mixedup_bboxes, mixedup_areas = [], [] for bbox, s_bbox, area, s_area in zip(bboxes, shuffled_bboxes, areas, shuffled_areas): mixedup_bboxes.append(bbox + s_bbox) mixedup_areas.append(area + s_area) return mixedup_images, mixedup_bboxes, mixedup_areas, indices.numpy() def read_image(image_id): """Read the image from image id""" image = cv2.imread(os.path.join(BASE_DIR, 'train', f'{image_id}.jpg'), cv2.IMREAD_COLOR) image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB).astype(np.float32) image /= 255.0 # Normalize return image if __name__ == '__main__': # Constants BASE_DIR = 'global-wheat-detection' # WORK_DIR = '/kaggle/working' BATCH_SIZE = 16 # Set seed for numpy for reproducibility np.random.seed(1996) train_df = pd.read_csv(os.path.join(BASE_DIR, 'train.csv')) # Let's expand the bounding box coordinates and calculate the area of all the bboxes train_df[['x_min','y_min', 'width', 'height']] = pd.DataFrame([ast.literal_eval(x) for x in train_df.bbox.tolist()], index= train_df.index) train_df = train_df[['image_id', 'bbox', 'source', 'x_min', 'y_min', 'width', 'height']] train_df['area'] = train_df['width'] * train_df['height'] train_df['x_max'] = train_df['x_min'] + train_df['width'] train_df['y_max'] = train_df['y_min'] + train_df['height'] train_df = train_df.drop(['bbox'], axis=1) train_df = train_df[['image_id', 'x_min', 'y_min', 'x_max', 'y_max', 'width', 'height', 'area', 'source']] # There are some buggy annonations in training images having huge bounding boxes. Let's remove those bboxes train_df = train_df[train_df['area'] < 100000] image_ids = train_df['image_id'].unique() # train_df.head() train_dataset = WheatDataset(train_df) train_loader = data_utils.DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=4, collate_fn=collate_fn) images, bboxes, areas, image_ids = next(iter(train_loader)) aug_images, aug_bboxes, aug_areas, aug_indices = mixup(images, bboxes, areas) fig, ax = plt.subplots(nrows=5, ncols=3, figsize=(15, 30)) for index in range(5): image_id = image_ids[index] image = read_image(image_id) get_bbox(bboxes[index], ax[index][0], color='red') ax[index][0].grid(False) ax[index][0].set_xticks([]) ax[index][0].set_yticks([]) ax[index][0].title.set_text('Original Image #1') ax[index][0].imshow(image) image_id = image_ids[aug_indices[index]] image = read_image(image_id) get_bbox(bboxes[aug_indices[index]], ax[index][1], color='red') ax[index][1].grid(False) ax[index][1].set_xticks([]) ax[index][1].set_yticks([]) ax[index][1].title.set_text('Original Image #2') ax[index][1].imshow(image) get_bbox(aug_bboxes[index], ax[index][2], color='red') ax[index][2].grid(False) ax[index][2].set_xticks([]) ax[index][2].set_yticks([]) ax[index][2].title.set_text(f'Augmented Image: lambda * image1 + (1 - lambda) * image2') ax[index][2].imshow(aug_images[index]) plt.show() plt.savefig('mixup.jpg')
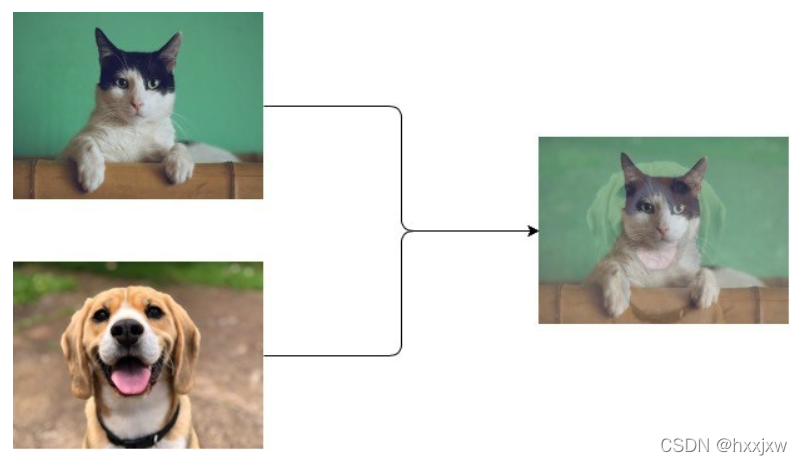


Pytorch实现
无mixup
python train.py \ --lr=0.1 \ --seed=20170922 \ --decay=1e-4train.py
from __future__ import print_function import argparse import csv import os import numpy as np import torch from torch.autograd import Variable import torch.backends.cudnn as cudnn import torch.nn as nn import torch.optim as optim import torchvision.transforms as transforms import torchvision.datasets as datasets import wandb import models from utils import progress_bar def train(epoch): print('\nEpoch: %d' % epoch) net.train() train_loss = 0 reg_loss = 0 correct = 0 total = 0 for batch_idx, (inputs, targets) in enumerate(trainloader): if use_cuda: inputs, targets = inputs.cuda(), targets.cuda() # inputs, targets_a, targets_b, lam = mixup_data(inputs, targets, # args.alpha, use_cuda) # inputs, targets_a, targets_b = map(Variable, (inputs, # targets_a, targets_b)) outputs = net(inputs) # loss = mixup_criterion(criterion, outputs, targets_a, targets_b, lam) loss = criterion(outputs, targets) train_loss += loss.item() _, predicted = torch.max(outputs.data, 1) total += targets.size(0) # correct += (lam * predicted.eq(targets_a.data).cpu().sum().float() # + (1 - lam) * predicted.eq(targets_b.data).cpu().sum().float()) correct += predicted.eq(targets).sum() optimizer.zero_grad() loss.backward() optimizer.step() progress_bar(batch_idx, len(trainloader), 'Loss: %.3f | Reg: %.5f | Acc: %.3f%% (%d/%d)' % (train_loss/(batch_idx+1), reg_loss/(batch_idx+1), 100.*correct/total, correct, total)) wandb.log({'train/accuracy': 100. * correct / total}) wandb.log({'train/loss': train_loss / (batch_idx + 1)}) wandb.log({'train/lr': optimizer.state_dict()['param_groups'][0]['lr']}) wandb.log({'train/epoch': epoch}) return (train_loss/batch_idx, reg_loss/batch_idx, 100.*correct/total) def test(epoch): global best_acc net.eval() test_loss = 0 correct = 0 total = 0 for batch_idx, (inputs, targets) in enumerate(testloader): if use_cuda: inputs, targets = inputs.cuda(), targets.cuda() # inputs, targets = Variable(inputs, volatile=True), Variable(targets) outputs = net(inputs) loss = criterion(outputs, targets) test_loss += loss.item() _, predicted = torch.max(outputs.data, 1) total += targets.size(0) correct += predicted.eq(targets.data).cpu().sum() progress_bar(batch_idx, len(testloader), 'Loss: %.3f | Acc: %.3f%% (%d/%d)' % (test_loss/(batch_idx+1), 100.*correct/total, correct, total)) acc = 100.*correct/total wandb.log({'test/accuracy': acc}) if epoch == start_epoch + args.epoch - 1 or acc > best_acc: checkpoint(acc, epoch) if acc > best_acc: best_acc = acc return (test_loss/batch_idx, 100.*correct/total) def checkpoint(acc, epoch): # Save checkpoint. print('Saving..') state = { 'net': net, 'acc': acc, 'epoch': epoch, 'rng_state': torch.get_rng_state() } if not os.path.isdir('checkpoint'): os.mkdir('checkpoint') torch.save(state, './checkpoint/ckpt.t7' + args.name + '_' + str(args.seed)) def adjust_learning_rate(optimizer, epoch): """decrease the learning rate at 100 and 150 epoch""" lr = args.lr if epoch >= 100: lr /= 10 if epoch >= 150: lr /= 10 for param_group in optimizer.param_groups: param_group['lr'] = lr parser = argparse.ArgumentParser(description='PyTorch CIFAR10 Training') parser.add_argument('--lr', default=0.1, type=float, help='learning rate') parser.add_argument('--resume', '-r', action='store_true', help='resume from checkpoint') parser.add_argument('--model', default="ResNet18", type=str, help='model type (default: ResNet18)') parser.add_argument('--name', default='0', type=str, help='name of run') parser.add_argument('--seed', default=0, type=int, help='random seed') parser.add_argument('--batch-size', default=128, type=int, help='batch size') parser.add_argument('--epoch', default=200, type=int, help='total epochs to run') parser.add_argument('--no-augment', dest='augment', action='store_false', help='use standard augmentation (default: True)') parser.add_argument('--decay', default=1e-4, type=float, help='weight decay') parser.add_argument('--alpha', default=1., type=float, help='mixup interpolation coefficient (default: 1)') args = parser.parse_args() wandb.init( project = "test", config = args, name = 'resnet', # id = args.wandb_id, #resume = True, ) use_cuda = torch.cuda.is_available() best_acc = 0 # best test accuracy start_epoch = 0 # start from epoch 0 or last checkpoint epoch if args.seed != 0: torch.manual_seed(args.seed) # Data print('==> Preparing data..') if args.augment: transform_train = transforms.Compose([ transforms.RandomCrop(32, padding=4), transforms.RandomHorizontalFlip(), transforms.ToTensor(), transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)), ]) else: transform_train = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)), ]) transform_test = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)), ]) trainset = datasets.CIFAR10(root='~/.torchvision/datasets/CIFAR10', train=True, download=False, transform=transform_train) trainloader = torch.utils.data.DataLoader(trainset, batch_size=args.batch_size, shuffle=True, num_workers=8) testset = datasets.CIFAR10(root='~/.torchvision/datasets/CIFAR10', train=False, download=False, transform=transform_test) testloader = torch.utils.data.DataLoader(testset, batch_size=100, shuffle=False, num_workers=8) # Model if args.resume: # Load checkpoint. print('==> Resuming from checkpoint..') assert os.path.isdir('checkpoint'), 'Error: no checkpoint directory found!' checkpoint = torch.load('./checkpoint/ckpt.t7' + args.name + '_' + str(args.seed)) net = checkpoint['net'] best_acc = checkpoint['acc'] start_epoch = checkpoint['epoch'] + 1 rng_state = checkpoint['rng_state'] torch.set_rng_state(rng_state) else: print('==> Building model..') net = models.__dict__[args.model]() if not os.path.isdir('results'): os.mkdir('results') logname = ('results/log_' + net.__class__.__name__ + '_' + args.name + '_' + str(args.seed) + '.csv') if use_cuda: net.cuda() net = torch.nn.DataParallel(net) print(torch.cuda.device_count()) cudnn.benchmark = True print('Using CUDA..') criterion = nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=args.lr, momentum=0.9, weight_decay=args.decay) # def mixup_data(x, y, alpha=1.0, use_cuda=True): # '''Returns mixed inputs, pairs of targets, and lambda''' # if alpha > 0: # lam = np.random.beta(alpha, alpha) # else: # lam = 1 # batch_size = x.size()[0] # if use_cuda: # index = torch.randperm(batch_size).cuda() # else: # index = torch.randperm(batch_size) # mixed_x = lam * x + (1 - lam) * x[index, :] # y_a, y_b = y, y[index] # return mixed_x, y_a, y_b, lam # def mixup_criterion(criterion, pred, y_a, y_b, lam): # return lam * criterion(pred, y_a) + (1 - lam) * criterion(pred, y_b) if not os.path.exists(logname): with open(logname, 'w') as logfile: logwriter = csv.writer(logfile, delimiter=',') logwriter.writerow(['epoch', 'train loss', 'reg loss', 'train acc', 'test loss', 'test acc']) for epoch in range(start_epoch, args.epoch): train_loss, reg_loss, train_acc = train(epoch) test_loss, test_acc = test(epoch) adjust_learning_rate(optimizer, epoch) with open(logname, 'a') as logfile: logwriter = csv.writer(logfile, delimiter=',') logwriter.writerow([epoch, train_loss, reg_loss, train_acc, test_loss, test_acc])有mixup
python train_mixup.py \ --lr=0.1 \ --seed=20170922 \ --decay=1e-4train_mixup.py
from __future__ import print_function import torchvision import argparse import csv import os import wandb import numpy as np import torch from torch.autograd import Variable import torch.backends.cudnn as cudnn import torch.nn as nn import torch.optim as optim import torchvision.transforms as transforms import torchvision.datasets as datasets import models from utils import progress_bar def mixup_data(x, y, alpha=1.0, use_cuda=True): '''Returns mixed inputs, pairs of targets, and lambda''' if alpha > 0: lam = np.random.beta(alpha, alpha) else: lam = 1 batch_size = x.size()[0] if use_cuda: index = torch.randperm(batch_size).cuda() else: index = torch.randperm(batch_size) mixed_x = lam * x + (1 - lam) * x[index, :] y_a, y_b = y, y[index] return mixed_x, y_a, y_b, lam def mixup_criterion(criterion, pred, y_a, y_b, lam): return lam * criterion(pred, y_a) + (1 - lam) * criterion(pred, y_b) def train(epoch): print('\nEpoch: %d' % epoch) net.train() train_loss = 0 reg_loss = 0 correct = 0 total = 0 for batch_idx, (inputs, targets) in enumerate(trainloader): if use_cuda: inputs, targets = inputs.cuda(), targets.cuda() inputs, targets_a, targets_b, lam = mixup_data(inputs, targets, args.alpha, use_cuda) inputs, targets_a, targets_b = map(Variable, (inputs, targets_a, targets_b)) outputs = net(inputs) loss = mixup_criterion(criterion, outputs, targets_a, targets_b, lam) train_loss += loss.item() _, predicted = torch.max(outputs.data, 1) total += targets.size(0) correct += (lam * predicted.eq(targets_a.data).cpu().sum().float() + (1 - lam) * predicted.eq(targets_b.data).cpu().sum().float()) optimizer.zero_grad() loss.backward() optimizer.step() progress_bar(batch_idx, len(trainloader), 'Loss: %.3f | Reg: %.5f | Acc: %.3f%% (%d/%d)' % (train_loss/(batch_idx+1), reg_loss/(batch_idx+1), 100.*correct/total, correct, total)) wandb.log({'train/accuracy': 100. * correct / total}) wandb.log({'train/loss': train_loss / (batch_idx + 1)}) wandb.log({'train/lr': optimizer.state_dict()['param_groups'][0]['lr']}) wandb.log({'train/epoch': epoch}) grid_image = torchvision.utils.make_grid(inputs, normalize=False) Img = wandb.Image(grid_image, caption="epoch:{}".format(epoch)) # attention!!! wandb.log({"train_img": Img}) return (train_loss/batch_idx, reg_loss/batch_idx, 100.*correct/total) def test(epoch): global best_acc net.eval() test_loss = 0 correct = 0 total = 0 for batch_idx, (inputs, targets) in enumerate(testloader): if use_cuda: inputs, targets = inputs.cuda(), targets.cuda() # inputs, targets = Variable(inputs, volatile=True), Variable(targets) outputs = net(inputs) loss = criterion(outputs, targets) test_loss += loss.item() _, predicted = torch.max(outputs.data, 1) total += targets.size(0) correct += predicted.eq(targets.data).cpu().sum() progress_bar(batch_idx, len(testloader), 'Loss: %.3f | Acc: %.3f%% (%d/%d)' % (test_loss/(batch_idx+1), 100.*correct/total, correct, total)) acc = 100.*correct/total wandb.log({'test/accuracy': acc}) if epoch == start_epoch + args.epoch - 1 or acc > best_acc: checkpoint(acc, epoch) if acc > best_acc: best_acc = acc return (test_loss/batch_idx, 100.*correct/total) def checkpoint(acc, epoch): # Save checkpoint. print('Saving..') state = { 'net': net, 'acc': acc, 'epoch': epoch, 'rng_state': torch.get_rng_state() } if not os.path.isdir('checkpoint'): os.mkdir('checkpoint') torch.save(state, './checkpoint/ckpt.t7' + args.name + '_' + str(args.seed)) def adjust_learning_rate(optimizer, epoch): """decrease the learning rate at 100 and 150 epoch""" lr = args.lr if epoch >= 100: lr /= 10 if epoch >= 150: lr /= 10 for param_group in optimizer.param_groups: param_group['lr'] = lr parser = argparse.ArgumentParser(description='PyTorch CIFAR10 Training') parser.add_argument('--lr', default=0.1, type=float, help='learning rate') parser.add_argument('--resume', '-r', action='store_true', help='resume from checkpoint') parser.add_argument('--model', default="ResNet18", type=str, help='model type (default: ResNet18)') parser.add_argument('--name', default='0', type=str, help='name of run') parser.add_argument('--seed', default=0, type=int, help='random seed') parser.add_argument('--batch-size', default=128, type=int, help='batch size') parser.add_argument('--epoch', default=200, type=int, help='total epochs to run') parser.add_argument('--no-augment', dest='augment', action='store_false', help='use standard augmentation (default: True)') parser.add_argument('--decay', default=1e-4, type=float, help='weight decay') parser.add_argument('--alpha', default=1., type=float, help='mixup interpolation coefficient (default: 1)') args = parser.parse_args() wandb.init( project = "test", config = args, name = 'resnet_mixup', # id = args.wandb_id, #resume = True, ) use_cuda = torch.cuda.is_available() best_acc = 0 # best test accuracy start_epoch = 0 # start from epoch 0 or last checkpoint epoch if args.seed != 0: torch.manual_seed(args.seed) # Data print('==> Preparing data..') if args.augment: transform_train = transforms.Compose([ transforms.RandomCrop(32, padding=4), transforms.RandomHorizontalFlip(), transforms.ToTensor(), transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)), ]) else: transform_train = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)), ]) transform_test = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)), ]) trainset = datasets.CIFAR10(root='~/.torchvision/datasets/CIFAR10', train=True, download=False, transform=transform_train) trainloader = torch.utils.data.DataLoader(trainset, batch_size=args.batch_size, shuffle=True, num_workers=8) testset = datasets.CIFAR10(root='~/.torchvision/datasets/CIFAR10', train=False, download=False, transform=transform_test) testloader = torch.utils.data.DataLoader(testset, batch_size=100, shuffle=False, num_workers=8) # Model if args.resume: # Load checkpoint. print('==> Resuming from checkpoint..') assert os.path.isdir('checkpoint'), 'Error: no checkpoint directory found!' checkpoint = torch.load('./checkpoint/ckpt.t7' + args.name + '_' + str(args.seed)) net = checkpoint['net'] best_acc = checkpoint['acc'] start_epoch = checkpoint['epoch'] + 1 rng_state = checkpoint['rng_state'] torch.set_rng_state(rng_state) else: print('==> Building model..') net = models.__dict__[args.model]() if not os.path.isdir('results'): os.mkdir('results') logname = ('results/log_' + net.__class__.__name__ + '_' + args.name + '_' + str(args.seed) + '.csv') if use_cuda: net.cuda() net = torch.nn.DataParallel(net) print(torch.cuda.device_count()) cudnn.benchmark = True print('Using CUDA..') criterion = nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=args.lr, momentum=0.9, weight_decay=args.decay) if not os.path.exists(logname): with open(logname, 'w') as logfile: logwriter = csv.writer(logfile, delimiter=',') logwriter.writerow(['epoch', 'train loss', 'reg loss', 'train acc', 'test loss', 'test acc']) for epoch in range(start_epoch, args.epoch): train_loss, reg_loss, train_acc = train(epoch) test_loss, test_acc = test(epoch) adjust_learning_rate(optimizer, epoch) with open(logname, 'a') as logfile: logwriter = csv.writer(logfile, delimiter=',') logwriter.writerow([epoch, train_loss, reg_loss, train_acc, test_loss, test_acc])其他模块在
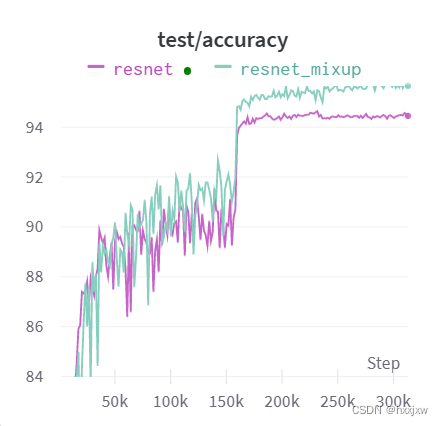
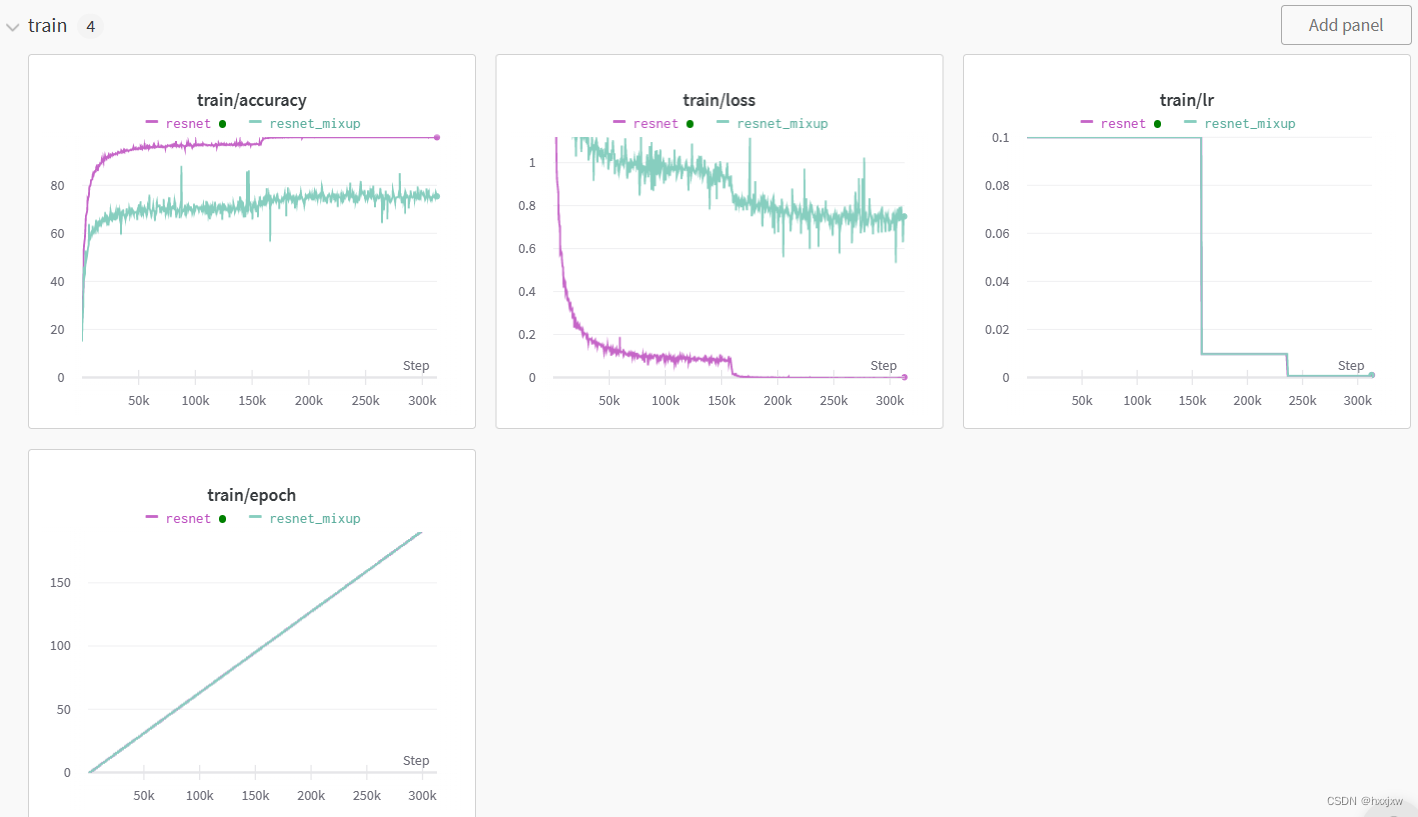















 889
889











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









