







分类目录:《深入理解深度学习》总目录
相关文章:
· Word Embedding(一):word2vec
· Word Embedding(二):连续词袋模型(CBOW, The Continuous Bag-of-Words Model)
· Word Embedding(三):Skip-Gram模型
· Word Embedding(四):Skip-Gram模型的数学原理
· Word Embedding(五):基于哈夫曼树(Huffman Tree)的Hierarchical Softmax优化
· Word Embedding(六):负采样(Negative Sampling)优化
我们首先看一个句子示例:
原句:今天下午2点钟搜索引擎组开组会。
分词:今天 下午 2点钟 搜索 引擎 组 开 组会。
现在对一句话的两种预测方式:
- 根据上下文预测目标值:对于每一个单词或词(统称为标识符),使用该标识符周围的标识符来预测当前标识符生成的概率。假设目标值为“2点钟”,我们可以使用“2点钟”的上文“今天、下午”和“2点钟”的下文“搜索、引擎、组”来生成或预测目标值。
- 由目标值预测上下文:对于每一个标识符,使用该标识符本身来预测生成其他词汇的概率。如使用“2点钟”来预测其上下文“今天、下午、搜索、引擎、组”中的每个词。
两种预测方法的共同限制条件是,对于相同的输入,输出每个标识符的概率之和为1。它们分别对应word2vec的两种模型,即连续词袋模型(CBOW, The Continuous Bag-of-Words Model)和Skip-Gram模型。根据上下文生成目标值时,使用CBOW模型;根据目标值生成上下文时,采用Skip-Gram模型。
CBOW模型包含三层:输入层、映射层和输出层。具体架构如下图所示:
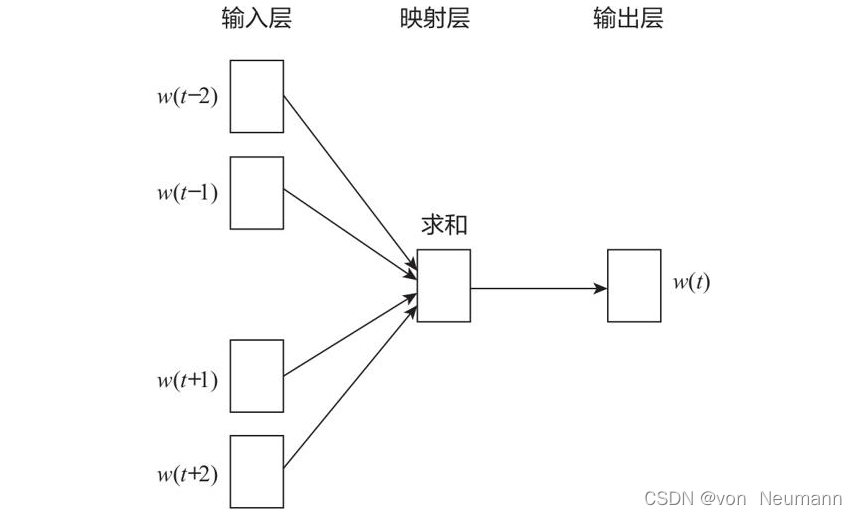
CBOW模型中的
w
(
t
)
w(t)
w(t)为目标词,在已知它的上下文
w
(
t
−
n
)
w(t-n)
w(t−n)、
⋯
\cdots
⋯、
w
(
t
−
2
)
w(t-2)
w(t−2)、
w
(
t
−
1
)
w(t-1)
w(t−1)、
w
(
t
+
1
)
w(t+1)
w(t+1)、
w
(
t
+
2
)
w(t+2)
w(t+2)、
⋯
\cdots
⋯、
w
(
t
+
n
)
w(t+n)
w(t+n)的前提下预测词
w
(
t
)
w(t)
w(t)出现的概率,即
p
(
w
∣
context
(
w
)
)
p(w|\text{context}(w))
p(w∣context(w))。目标函数为:
L
=
∑
w
∈
C
log
p
(
w
∣
context
(
w
)
)
L=\sum_{w\in C}\log p(w|\text{context}(w))
L=w∈C∑logp(w∣context(w))
CBOW模型其实就是根据某个词前后的若干词来预测该词,也可以看成是多分类。最朴素的想法就是直接使用Softmax函数来分别计算每个词对应的归一化的概率。但对于动辄十几万词汇量的场景,使用Softmax计算量太大,此时可以使用一种称为二分类组合形式的Hierarchical Softmax(输出层为一棵二叉树)来优化。



















 2212
2212

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











