







一、实验过程及结果
1.调试并理解回归示例的源代码实现regression.py。掌握其中的datasets.make_regression函数和np.random.normal函数。并生成500个1维的回归数据,以及100个噪声点,作为数据集。
def data(n_samples, n_outliers): # 样本数,噪声点
# X:输入样本 y:输出值 coef:基础线性模型的系数。 仅当coef为True时才返回
X, y, coef = datasets.make_regression(n_samples=n_samples, # 样本数
n_features=1, # 特征数
n_informative=1, # 信息特征的数量,即用于构建用于生成输出的线性模型的特征的数量
noise=10, # 应用于输出的高斯噪声的标准偏差
coef=True, # 如果为True,则返回基础线性模型的系数
random_state=0) # 确定用于生成数据集的随机数生成
# 添加噪声点
np.random.seed(0) # 随机数种子,参数表示随机数起始的位置,使得每次生成的噪声点位置一样,使得X,y的生成规律一样
X[:n_outliers] = 3 + 0.5 * np.random.normal(size=(n_outliers, 1))
y[:n_outliers] = -3 + 10 * np.random.normal(size=n_outliers)
# np.random.normal(loc=0.0, scale=1.0, size=None)
# loc:分布的均值(中心) scale:分布的标准差(宽度) size:生成(n_outlier, 1)的数组
# 公式中的3+0.5是让数据点的横坐标以3为中心呈现正态分布,取0.5是因为横坐标的差值小
return X, y
X, y = data(500, 100)datasets.make_regression函数产生随机回归问题。输入集可以处于良好状态,也可以具有低秩胖尾部奇异轮廓。通过将具有n_informative非零回归变量的(可能有偏差的)随机线性回归模型应用于先前生成的输入和具有可调整比例的一些高斯中心噪声来生成输出。 np.random.normal函数从正态(高斯)分布中抽取随机样本,此处抽取随机样本作为噪声点。各个参数的具体意义已在代码的注释部分中写明。
data(n_samples,n_outliers)函数中包含以上两个函数,实现了生成n_samples 个1维的回归数据以及n_outliers个噪声点作为数据集的作用,返回值为包括回归数据与噪声点在内的数据集。
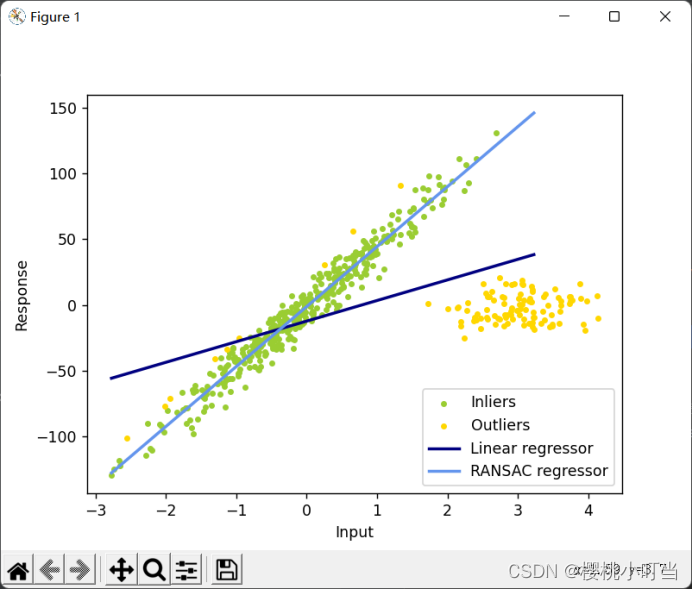
由regression.py的运行结果可以看出,一元线性回归的估计系数严重偏离真实值,易受噪声点影响。而RANSAC因为会计算所有样本点的残差,将残差小于预设残差阈值的点归为内点集inlier,其余是外点集outlier,所以不易受噪声点影响,估计系数更接近真实值。

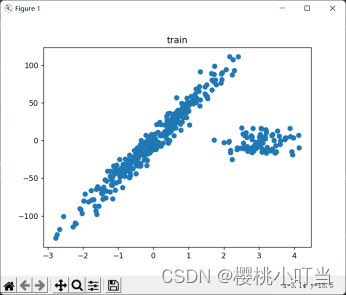
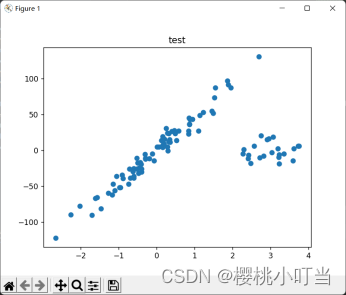
2.使用train_test_split函数将数据集划分为训练集和测试集(8:2),使用一元线性回归和一元二次多项式回归对数据进行拟合。
def _split(X, y, size):
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=size) # test_size决定划分测试、训练集比例
plt.title('train')
plt.scatter(X_train, y_train)
plt.show()
plt.title('test')
plt.scatter(X_test, y_test)
plt.show()
return X_train, X_test, y_train, y_test
def linear1(X, y, line_X): # 一元线性回归
model = linear_model.LinearRegression() # 创建一个LinearRegression模型
model.fit(X, y) # 训练集上训练一个线性回归模型
# 一元线性训练集预测
line_y = model.predict(line_X) # 以LinearRegression的模型lr预测y
return model, line_y
def linear2(X, y, line_X): # 一元二次多项式回归
poly2 = PolynomialFeatures(degree=2) # 初始化二次多项式生成器,设置多项式阶数为2
X_poly2 = poly2.fit_transform(X) # 用fit_transform将X_train变成2阶
model = linear_model.LinearRegression() # 创建一个LinearRegression模型
model.fit(X_poly2, y) # 训练集上训练一个线性回归模型
X_poly1 = poly2.fit_transform(line_X) # 用fit_transform将line_X变成2阶
line2_y = model.predict(X_poly1) # 一元二次多项式训练集预测
return model, X_poly2, line2_y
def ransac(X, y, line_X): # Robustly fit linear model with RANSAC algorithm
model = linear_model.RANSACRegressor(base_estimator=linear_model.LinearRegression(),
# base_estimator 仅限于回归估计,默认LinearRegression
min_samples=10, # 最小样本
residual_threshold=25.0, # 残差,即真实值与预测值的差
stop_n_inliers=320, # 内集阈值
max_trials=100, # 迭代次数
random_state=0)
model.fit(X, y)
inlier = model.inlier_mask_
outlier = np.logical_not(inlier) # 自动识别划分内点集和外点集
line_y = model.predict(line_X)
return model, inlier, outlier, line_y
X_train, X_test, y_train, y_test = _split(X, y, 0.2)
line_X = np.arange(X_train.min(), X_train.max(), 0.1)[:, np.newaxis] # 增加维度,作用是平均取点,使得直线更直
lr, line_trainy = linear1(X_train, y_train, line_X)
ransac, inlier_mask, outlier_mask, line_y_train_ransac = ransac(X_train, y_train, line_X)
lr2, X_train_poly2, line2_trainy = linear2(X_train, y_train, line_X)_split(X, y, size)函数实现了将数据集划分为训练集和测试集,并将划分后的训练集和测试集可视化。其中调用了train_test_split函数来划分数据集,参数为数据集与划分比例。参数test_size即划分比例,与_split()函数的参数size对应,此处由于要求训练集和测试集的比例为8:2,因此调用_split()函数时size设置为0.2。
linear1()函数实现了一元线性回归。创建LinearRegression模型后在训练集上进行训练,随后以此模型对y进行预测。最后返回值为训练后的模型以及预测的y。
linear2()函数实现了一元二次多项式回归。先使用PolynomialFeatures函数来初始化二次多项式生成器,参数degree即多项式阶数,此处设置为2,此外还要用fit_transform函数将输入的X和line_X变成2阶。随后,创建LinearRegression模型并在2阶训练集上进行训练,再以此模型和2阶的line_X对y进行预测。返回值为训练后的模型、转为2阶的数据集以及预测的y。
ransac()函数实现了稳健性回归。先通过linear_model.RANSACRegressor创建回归模型,随后识别划分出内点集和外点集,并以此模型对y进行预测。返回值为训练后的模型、内集点、外集点以及预测的y。
主函数中调用了np.arange()函数来增加数据的维度,对线条进行切分从而达到最后线条更加光滑的效果。np.arange()函数步长默认为1,此处设置为0.1。
由结果图大致可以看出,对数据集的划分达到了题目中要求的8:2。
3.使用sklearn.metrics模块中的r2_score函数计算R方确定系数。
def r2(y,line1, line2, line_ransac):
# 利用sklearn.metrics模块中的r2_score函数计算R方确定系数
print("LinearRegression之一元线性train的R方系数:")
print(r2_score(y, line1))
print("LinearRegression之一元二次多项式train的R方系数:")
print(r2_score(y, line2))
print("RANSACRegressor之一元线性train的R方系数:")
print(r2_score(y, line_ransac))
line1 = lr.predict(X_train)
line2 = lr2.predict(X_train_poly2)
line_ransac = ransac.predict(X_train)
r2(y_train, line1, line2, line_ransac)R方即确定系数,表示一元多项式回归方程拟合度的高低,即一元多项式回归方程估测可靠程度的高低。R方的范围是负无穷到1,R方越小,表示拟合程度越差;R方越接近于1,表示回归的效果越好。
主函数中使用predict函数拟合出预测值后,调用r2()函数计算R方并打印结果。r2()函数中调用了r2_score函数,其参数分别为预测值和真实值,此处将一元线性回归、一元二次多项式回归、Ransac回归所得出的预测值和真实值依次输入,从而得出三个R方。
由结果图可知,一元二次多项式回归对训练集的拟合效果最好,其次是一元线性回归,而Ransac回归对训练集的效果相对来说较差。

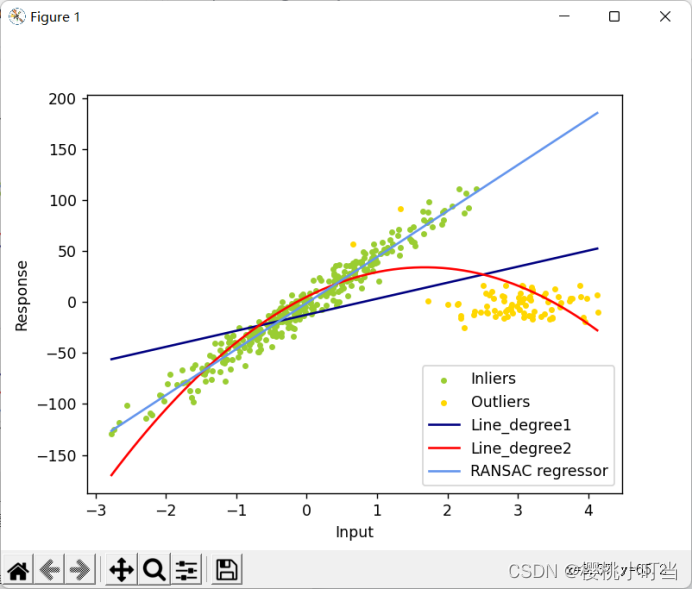
4.将测试样本和回归曲线进行可视化。
def show(X, y, line_X, line_y, line2_y, inlier, outlier, line_y_ransac):
plt.scatter(X[inlier], y[inlier], color='yellowgreen', marker='.', label='Inliers')
plt.scatter(X[outlier], y[outlier], color='gold', marker='.', label='Outliers')
plt.plot(line_X, line_y, color='navy', label='Line_degree1')
plt.plot(line_X, line2_y, color='red', label='Line_degree2')
plt.plot(line_X, line_y_ransac, color='cornflowerblue', label='RANSAC regressor')
plt.legend(loc='lower right')
plt.xlabel("Input")
plt.ylabel("Response")
plt.show()
show(X_train, y_train, line_X, line_trainy, line2_trainy, inlier_mask, outlier_mask, line_y_train_ransac)show()函数实现了测试样本和回归曲线的可视化,其输入参数为一元线性回归、一元二次多项式回归、Ransac回归对数据集拟合后返回的数据。
由结果图可知一元二次多项式回归的拟合效果最好,其回归曲线与样本点、噪声点重合度高。Ransac回归将噪声点都计入了外集点,其回归曲线与样本集高度重合,但与噪声点相隔甚远。
5.在测试集上分别测试一元线性回归和一元二次多项式回归,并使用sklearn.metrics的mean_squared_error函数计算预测值和实际值之间的平均平方误差MSE。
def mse(y,line1, line2, line_ransac):
# 利用sklearn.metrics模块中的mean_squared_error函数计算均方误差 真实值与预测值之间的差的平方求平均
print("LinearRegression之一元线性train的MSE:")
print(mean_squared_error(y, line1))
print("LinearRegression之一元二次多项式train的MSE:")
print(mean_squared_error(y, line2))
print("RANSACRegressor之一元线性train的MSE:")
print(mean_squared_error(y, line_ransac))
mse(y_train, line1, line2, line_ransac)MSE即均方误差,表示参数估计值与参数真值之差平方的期望值,其值越小,说明预测模型描述实验数据具有更好的精确度。
mse()函数计算平均平方误差MSE并打印结果。mse()函数中调用了mean_squared_error函数,其参数分别为预测值和真实值,此处将一元线性回归、一元二次多项式回归、Ransac回归所得出的预测值和真实值依次输入,从而得出三个MSE。
由结果图可知,一元二次多项式回归对训练集的拟合效果最好,其次是一元线性回归,而Ransac回归对训练集的效果相对来说较差。

二、实验心得
通过本次实验,我了解了如何使用python实现一元线性回归、一元二次多项式回归、Ransac回归算法。此外,我对随机回归问题的生成、数据集的划分、确定系数R方和均方误差MSE的计算原理和函数实现方法有了一定的认识与掌握。
实验过程中,我逐渐明白了使用random.normal()添加噪声点时,噪声点是被包含在先前创建的500个样本点中的,而这些噪声点的坐标位置由公式中的常数来确定。回归模型对数据的拟合需要先创建回归模型,随后再在数据集上进行训练,最后才能预测y。对于Ransac回归,需要分离出内点集inlier和外点集outlier。对于一元二次多项式回归,需要用fit_transform函数将数据集变为2阶。随机回归问题可由datasets.make_regression函数生成,训练集和测试集的划分可以通过train_test_split函数来实现,test_size决定了划分的比例。确定系数R方可由r2_score函数来计算,其值越接近1则说明模型对数据集的拟合效果越好;均方误差MSE可由mean_squared_error函数来计算,其值越小则说明模型对数据集的拟合效果越好。关于拟合后的线条不够光滑的问题,可以通过调整np.arange()函数的参数来使得每一小段线条划分的更细,从而得到更加光滑的曲线。















 2582
2582











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











