







引言部分不赘述,这篇主要关注怎么实现的。
前人存在的问题
一般,通常是通过GAN将秘密信息编码为(非分布保持)噪声向量、样式向量、抽象结构向量等纠缠特征,用于隐写图像生成。
解纠缠特征:独立变化的特征。分布保持系统:对于cover space![]() ,以及stego space
,以及stego space ![]() ,他们之间的分布差异为0(相对熵,KL散度):
,他们之间的分布差异为0(相对熵,KL散度):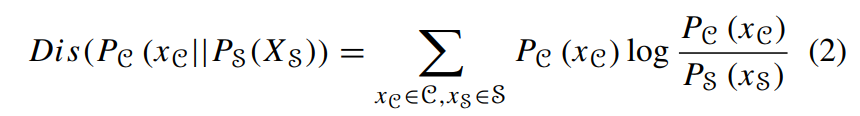
表示两个空间的分布相同,此隐写系统称之为distribution-preserving system。
由此,前人存在的问题:1)特征分离难,影响秘密提取的准确性;2)特征域安全性低,分析分布就会发现秘密信息的存在。
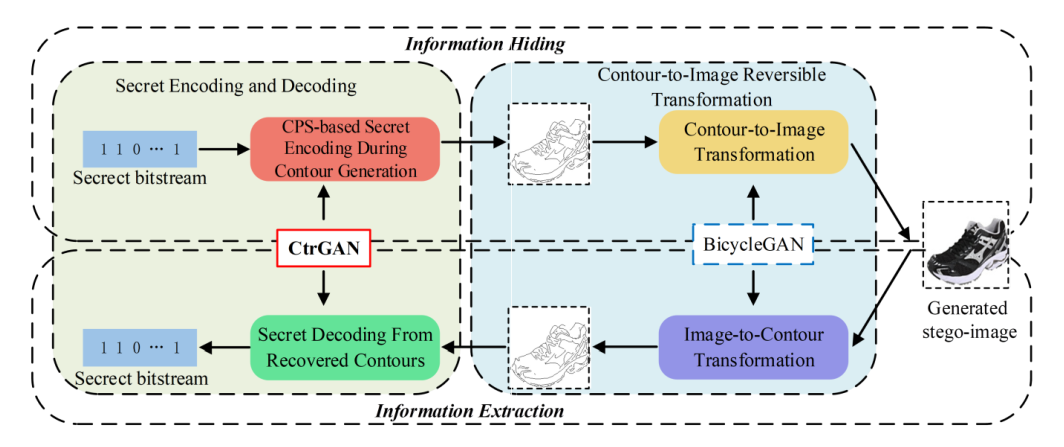
本文的框架以保持分布的方式将秘密信息编码为解纠缠特征,即对象轮廓。在信息隐藏阶段,基于训练好的轮廓生成模型CtrGAN,基于轮廓点选择(CPS)的编码策略,将秘密信息编码为轮廓。然后,利用bicycleGAN将轮廓变换为对应的隐写图像。对应的框架如上图。
CtrGAN
CtrGAN结构
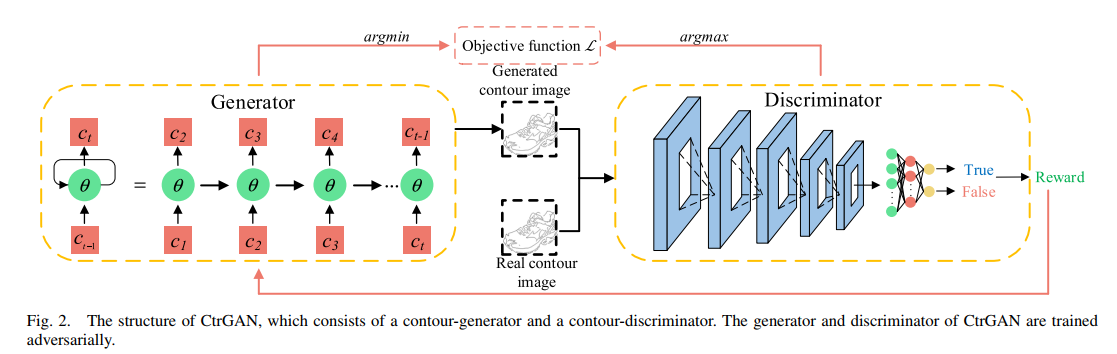
图看不懂,只看文字就行。
所提出的CtrGAN由生成器和鉴别器组成。轮廓是一个序列信息,因此,受到SeqGAN的启发,使用长短期记忆(LSTM)作为生成器,表示为Gθ。以CNN分类器作为鉴别器(二元),表示为Dφ。
CtrGAN训练
对于训练,我们需要训练数据,轮廓:整体嵌套边缘检测算法(HED)从真实图像中提取轮廓,作为真实轮廓数据集D。
物体的轮廓可以看作是点的序列:![]()
![]() 这里用二维坐标表示,Pc为所有候选点的集合。又因为强化学习目的是在一段时间内产生最优的动作序列,因此,采用强化学习来训练生成器Gθ。
这里用二维坐标表示,Pc为所有候选点的集合。又因为强化学习目的是在一段时间内产生最优的动作序列,因此,采用强化学习来训练生成器Gθ。
 强化学习是一种游戏的感觉,有奖励机制。
强化学习是一种游戏的感觉,有奖励机制。通过最大化所有奖励和来实现强化学习。
假设在时间t时,已经生成的轮廓为:![]() ,这作为当前的状态St,而选择下一个轮廓点的动作,作为At。在每一个状态下,采取行动后,通过估计欺骗鉴别器Dφ的期望概率作为奖励:
,这作为当前的状态St,而选择下一个轮廓点的动作,作为At。在每一个状态下,采取行动后,通过估计欺骗鉴别器Dφ的期望概率作为奖励:![]() 。此计算公式利用Monte-Carlo algorithm with roll-out policy
。此计算公式利用Monte-Carlo algorithm with roll-out policy![]() :
:![]()
其中,![]() 为带roll-out policy
为带roll-out policy![]() 的Monte-Carlo寻找函数。
的Monte-Carlo寻找函数。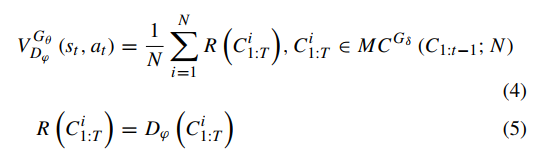
如果初始状态给定S0,则最大化目标函数,训练生成器: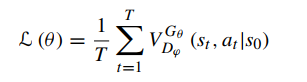
而对于判别器,生成器的参数确定后,通过最大化下面的loss函数来重新训练判别器: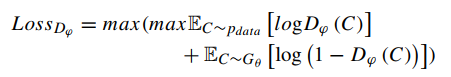
算法如下:
所提出的方法
图1所示的框架。
信息隐藏
1)CPS-Based Encoding During Contour Generation 基于CPS编码轮廓生成,(contour point selection,CPS,轮廓点选择)
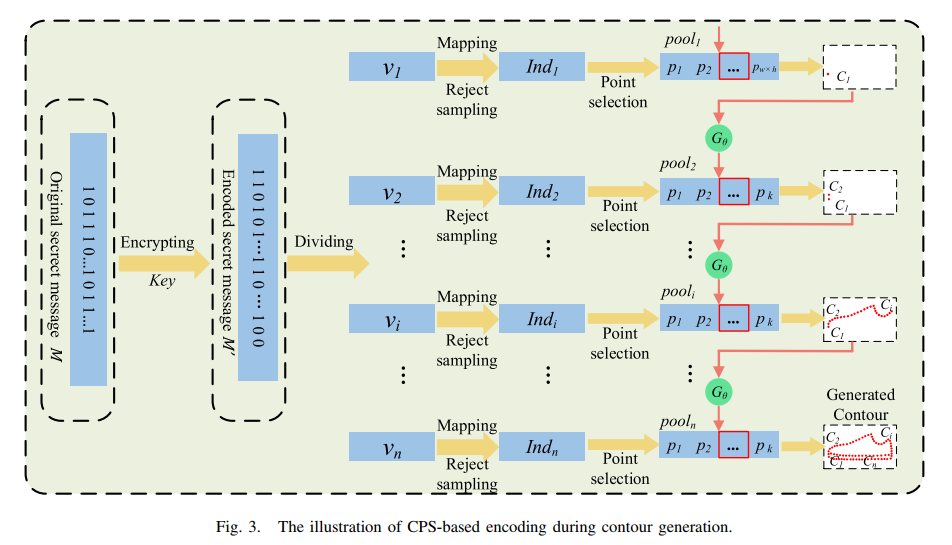
首先,对于秘密信息01比特流加密成随机比特流,通过加密安全伪随机数生成器(Cryptographically secure pseudo-random number generator,CSPRNG):![]() 伪随机序列
伪随机序列
将M‘切片,一片L位,并转换为十进制:![]() 。
。
对于第一个点:
第一个v1就应该编码为轮廓起点的选择,即c1。此外,收集大小为wxh的图像平面内的所有点作为候选点池,pool1.
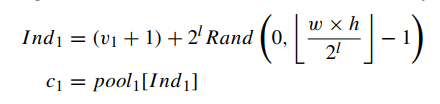 这里看起来就是随机生成的。
这里看起来就是随机生成的。
其中Rand(x, y)表示在[x, y]范围内随机选择一个整数的函数。选取pool1中的第ind1点作为轮廓点c1。
对于第i个点的选择:
先建立候选池pooli,由于,![]() 而且,轮廓点不能重复,所以,在如果一个候选点已经被占用,则它的概率为0,那些概率不是0的点即为pooli。
而且,轮廓点不能重复,所以,在如果一个候选点已经被占用,则它的概率为0,那些概率不是0的点即为pooli。
通过拒绝采样函数RS函数(从均匀概率分布映射到p概率分布):![]()
![]() 测试vi是不是在规定的分布里,或者说范围内。
测试vi是不是在规定的分布里,或者说范围内。
在轮廓生成的过程中,对于Ci的选择,i>2,无信息隐藏的轮廓线就是从概率直接生成。而对于有信息隐藏的轮廓线,则认识是从概率中采样获得。由此,加了隐藏信息和没有加隐藏信息的轮廓分布都是一样的,也就是前面提到的分布保持系统,更加具有安全性。
2)Ctr2Img Transformation(轮廓转为图像):
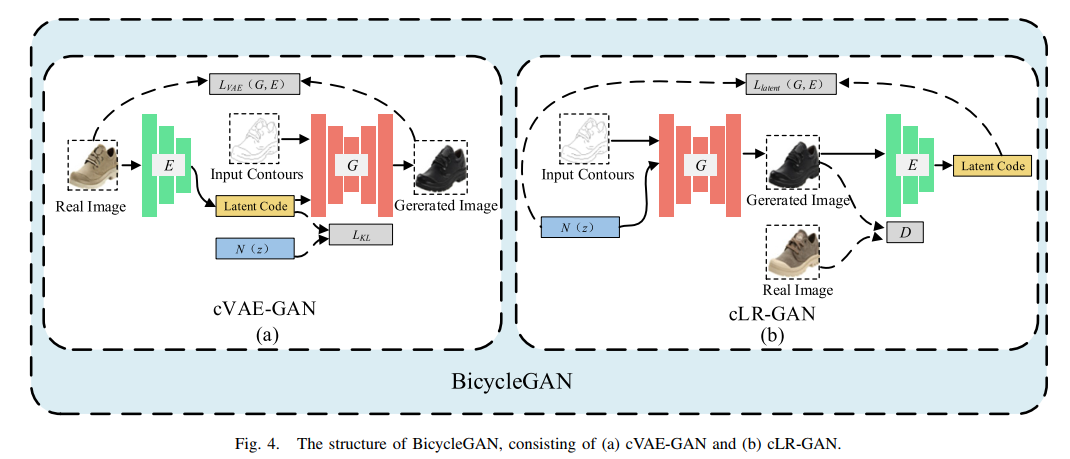
利用bicycleGAN来实现轮廓与图像之间的转换。bicycleGAN由条件变分自编码器GAN(cVAE-GAN)以及条件隐回归GAN(cLR-GAN)组成。
cVAE-GAN首先将真实图像编码为一组高斯分布的隐码,随机选取一组隐码作为噪声,然后将噪声和轮廓图像一起输入到生成器,得到生成图像。它根据输入的噪声不用,可以生成不同风格的图像。
cLR-GAN首先将随机噪声和轮廓图像输入生成器中,得到生成图像。然后对图像进行编码,得到隐码。然后利用得到的隐码对轮廓进行复原。
信息提取
1)Img2Ctr Transformation(由图像转为轮廓):
这一步还是用bicycleGAN实现。用cLR-GAN来恢复图像。
2)从轮廓进行秘密解码:
假设:接收方和发送发共享了密钥key。
对于获得的轮廓序列,![]() 先获得候选池集合(用信息隐藏阶段的方法)POOL=
先获得候选池集合(用信息隐藏阶段的方法)POOL=![]()
求v1: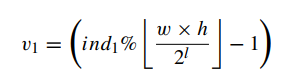
求vi:![]()
实验部分
实验设定
文章使用了三个数据集(50025张鞋子,138000张手袋,10000张动物),全部缩放到256x256大小。通过整体嵌套边缘检测算法HED来提取真实轮廓图。
随机初始化CtrGAN的生成器和鉴别器的参数,利用最大似然估计MLE对生成器进行预训练。然后生成10000张轮廓图,并与真实轮廓图通过最小化交叉熵(公式7)来训练鉴别器。
参数部分:
未完待续















 3280
3280











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









