






 文章介绍了如何通过计算YOLO系列模型的FPS,关注GPU性能、batchsize设置以及注意力模块对速度的影响。作者强调了在评估模型速度时,网络耗时、显卡预热和正确调整batchsize的重要性。
文章介绍了如何通过计算YOLO系列模型的FPS,关注GPU性能、batchsize设置以及注意力模块对速度的影响。作者强调了在评估模型速度时,网络耗时、显卡预热和正确调整batchsize的重要性。
1.所需要了解的一些知识
YOLO系列在计算FPS的时候包含了3部分时间:
1.数据处理(将图片转换成640*640)
2.网络消耗时间(图片输入到网络到最终的结果输出)
3.非极大抑制(也就是把预测结果处理一下,就是网络中有很多框,选择一个最接近结果的)
使用文本代码前,你最好需要会搭建一个网络,然后使用网络进行预测。
如果上面都没问题就进行下面这段内容
2.代码原理
一般情况下你的显卡GPU越好,网络FPS也基本上是越高(这里计算的时间只包含网络消耗时间),但是也有一些情况。
ps:有特殊情况比如说你现在的显卡是3090,别人的显卡是3070啥的,但是你们FPS测出来发现差不了太多,除了保证程序软件版本什么一致以外。还有一个重要的原因就是batchsize!!一般大家预测网络都是取batchsize=1这就会造成显卡可能会偷懒,不能发挥出全部性能,所以唯一解决的办法就是在不爆显存的情况下增加batchsize才能榨干显卡的性能。
下面来介绍一下流程:
1.初始化网络
2.初始化输入
3.模型预热
4.测量FPS
3.代码
3.1初始化网络
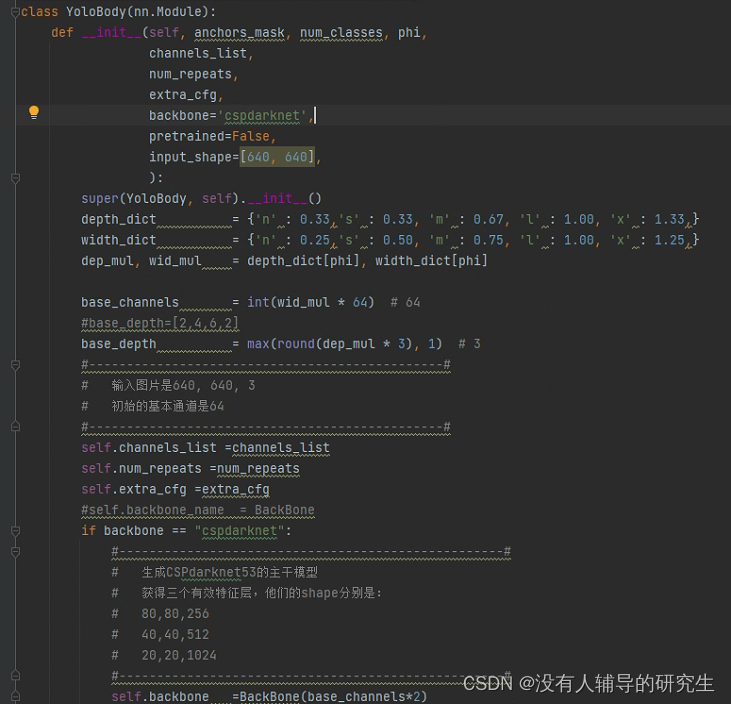
上图的代码是B导的Yolov5,大家搜一下就会很容易找到源码。
图片中是Yolo所有代码的一个类,我们要初始化这个类。
下面是我写的一个简单的网络代码如下(如果大家看不懂上面的代码)
import torch
import torch.nn as nn
import time
class net(nn.Module):
def __init__(self):
super().__init__()
self.block=nn.Sequential(
nn.Conv2d(in_channels=3,out_channels=32,kernel_size=3,stride=2),
nn.BatchNorm2d(32),
nn.ReLU()
)
self.block2=nn.Sequential(
nn.Conv2d(in_channels=32,out_channels=64,kernel_size=3,stride=2),
nn.BatchNorm2d(64),
nn.ReLU()
)
self.block3=nn.Sequential(
nn.Conv2d(in_channels=64,out_channels=128,kernel_size=3,stride=2),
nn.BatchNorm2d(128),
nn.ReLU()
)
self.block4=nn.Sequential(
nn.Conv2d(in_channels=128,out_channels=256,kernel_size=3,stride=2),
nn.BatchNorm2d(256),
nn.ReLU()
)
self.Flatten=nn.Sequential(nn.Flatten())
self.Linear=nn.Sequential(nn.Linear(389376,512),
nn.Linear(512,10),
nn.Softmax(dim=1)
)
def forward(self,x):
out=self.block(x)
out2=self.block2(out)
out3=self.block3(out2)
out4=self.block4(out3)
out5=self.Flatten(out4)
out6=self.Linear(out5)
return out6
if __name__ == '__main__':
x=torch.randn(1,3,640,640)
hyj=net()
out=hyj(x)
print(out.shape)上面的代码就是一个对输入大小(3,640,640)的图片进行处理,可以看作是一个10分类任务
我们如何知道上面这段代码的运行时间,只需要在下面添加这个就好,代码如下
def forward(self,x):
time1=time.time()
out=self.block(x)
out2=self.block2(out)
out3=self.block3(out2)
out4=self.block4(out3)
out5=self.Flatten(out4)
out6=self.Linear(out5)
time2=time.time()
return out6,time2-time1
if __name__ == '__main__':
x=torch.randn(1,3,640,640)
hyj=net()
out=hyj(x)
print(out[0].shape)
print(out[1])上面代码中,我们添加了time1与time2,通过time2-time1就可以得出一个前向传播所要花费的时间,基本上所有模型的运行时间都可以用这个办法去得出来,但是还有特殊情况我后面会说。
3.2 计算时间
上面我们计算出来的时间不是准确的,因为我们放在了cpu上跑的代码,我们现在需要给放到显卡cuda上,然后计算准确的时间还需要先给模型送到显卡上预热一下,这个就好比跑步前热身一下,可以让GPU发挥出更好的性能。下面的代码我们就要放到GPU上,代码如下。
import torch
import torch.nn as nn
import time
class net(nn.Module):
def __init__(self):
super().__init__()
self.block=nn.Sequential(
nn.Conv2d(in_channels=3,out_channels=32,kernel_size=3,stride=2),
nn.BatchNorm2d(32),
nn.ReLU()
)
self.block2=nn.Sequential(
nn.Conv2d(in_channels=32,out_channels=64,kernel_size=3,stride=2),
nn.BatchNorm2d(64),
nn.ReLU()
)
self.block3=nn.Sequential(
nn.Conv2d(in_channels=64,out_channels=128,kernel_size=3,stride=2),
nn.BatchNorm2d(128),
nn.ReLU()
)
self.block4=nn.Sequential(
nn.Conv2d(in_channels=128,out_channels=256,kernel_size=3,stride=2),
nn.BatchNorm2d(256),
nn.ReLU()
)
self.Flatten=nn.Sequential(nn.Flatten())
self.Linear=nn.Sequential(nn.Linear(389376,512),
nn.Linear(512,10),
nn.Softmax(dim=1)
)
def forward(self,x):
time1=time.time()
out=self.block(x)
out2=self.block2(out)
out3=self.block3(out2)
out4=self.block4(out3)
out5=self.Flatten(out4)
out6=self.Linear(out5)
time2=time.time()
return out6,time2-time1
if __name__ == '__main__':
device=torch.device('cuda'if torch.cuda.is_available() else 'cpu')
x=torch.randn(1,3,640,640).to(device)
hyj=net().to(device)
out=hyj(x)
print(out[0].shape)
print(out[1])现在我们修改后的代码就是在gpu上跑出来的时间,大家运行以后会发现非常慢,主要是由于我们没有给GPU进行预热,还有多次测量结果取平均值。我上面代码跑的时间如下:

可以看到2秒多非常慢了,接下来我们改进代码,如下所示:
if __name__ == '__main__':
device=torch.device('cuda'if torch.cuda.is_available() else 'cpu')
x=torch.randn(1,3,640,640).to(device)
hyj=net().to(device)
out=hyj(x)
print(out[0].shape)
print(out[1])
all_time=0
for i in range(500):
out = hyj(x)
spend_time=out[1]
all_time=all_time+spend_time
print('所花费的时间是',float(all_time/500))上面这段代码,我们前面那段前向传播,就当给GPU预热一下,后面模型在gpu上跑500次,取平均值,就可以得到以下的结果

我们可以发现现在模型,速度快了很多运行的时候,当然这个速度肯定会比你最终结果那个FPS快很多的,大家就可以把这个当作一个看你添加的模块是否对模型速度影响过大的一个方法,这样就可以不用等训练结束以后得知结果了。
加入我们添加一个CA模块,代码如下
import torch
import torch.nn as nn
import time
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class CoordAtt(nn.Module):
def __init__(self, inp, oup, groups=32):
super(CoordAtt, self).__init__()
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, inp // groups)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.conv2 = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
self.conv3 = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
self.relu = h_swish()
def forward(self, x):
identity = x
n,c,h,w = x.size()
x_h = self.pool_h(x)
x_w = self.pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
y = self.conv1(y)
y = self.bn1(y)
y = self.relu(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
x_h = self.conv2(x_h).sigmoid()
x_w = self.conv3(x_w).sigmoid()
x_h = x_h.expand(-1, -1, h, w)
x_w = x_w.expand(-1, -1, h, w)
y = identity * x_w * x_h
return y
class net(nn.Module):
def __init__(self):
super().__init__()
self.block=nn.Sequential(
nn.Conv2d(in_channels=3,out_channels=32,kernel_size=3,stride=2),
nn.BatchNorm2d(32),
nn.ReLU()
)
self.block2=nn.Sequential(
nn.Conv2d(in_channels=32,out_channels=64,kernel_size=3,stride=2),
nn.BatchNorm2d(64),
nn.ReLU()
)
self.block3=nn.Sequential(
nn.Conv2d(in_channels=64,out_channels=128,kernel_size=3,stride=2),
nn.BatchNorm2d(128),
nn.ReLU()
)
self.block4=nn.Sequential(
nn.Conv2d(in_channels=128,out_channels=256,kernel_size=3,stride=2),
nn.BatchNorm2d(256),
nn.ReLU()
)
self.Flatten=nn.Sequential(nn.Flatten())
self.Linear=nn.Sequential(nn.Linear(389376,512),
nn.Linear(512,10),
nn.Softmax(dim=1)
)
self.CA=CoordAtt(256,256)
def forward(self,x):
time1=time.time()
out=self.block(x)
out2=self.block2(out)
out3=self.block3(out2)
out4=self.block4(out3)
out4=self.CA(out4)
out5=self.Flatten(out4)
out6=self.Linear(out5)
time2=time.time()
return out6,time2-time1
if __name__ == '__main__':
device=torch.device('cuda'if torch.cuda.is_available() else 'cpu')
x=torch.randn(1,3,640,640).to(device)
hyj=net().to(device)
out=hyj(x)
print(out[0].shape)
print(out[1])
all_time=0
for i in range(500):
out = hyj(x)
spend_time=out[1]
all_time=all_time+spend_time
print('所花费的时间是',float(all_time/500))下面是输出结果
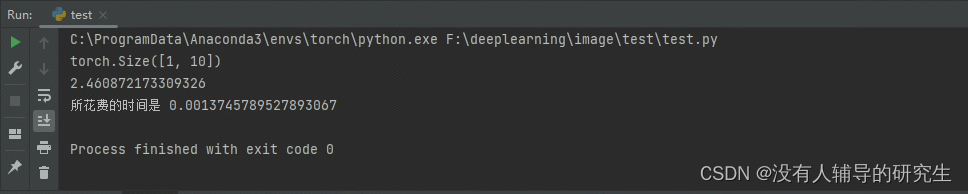
可以发现速度慢了一些,以上就是如何评估一个注意力或者改了什么模块对模型速度影响的方法。
4.注意事项
如果有参数重组模块!!!一定记得要变回去 比如说Repvgg这种模块,还有model.eval()或者no.grad什么的 本文里就没用,就直接看一下模块添加后速度对比,如果要得到准确的数据建议加上。
还有就是 本文也尝试过用训练了1个epoch,然后把数据集图片传输到网络中求时间,其实都差不多,如果大家有什么问题可以留言。















 926
926











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









