







 本文介绍了哈希表的概念,旨在通过哈希函数将关键字映射到表中以达到快速搜索的目的。讨论了直接寻址表的局限性和哈希表的优势。详细阐述了哈希函数的设计原则,如除法和乘法散列法,并分析了冲突解决的链接法和开放寻址法,包括线性探查和双重探查。最后提到了装载因子对搜索效率的影响。
本文介绍了哈希表的概念,旨在通过哈希函数将关键字映射到表中以达到快速搜索的目的。讨论了直接寻址表的局限性和哈希表的优势。详细阐述了哈希函数的设计原则,如除法和乘法散列法,并分析了冲突解决的链接法和开放寻址法,包括线性探查和双重探查。最后提到了装载因子对搜索效率的影响。
哈希表又称散列表,其定义是根据一个哈希函数将集合S中的关键字映射到一个表中,这个表就称为哈希表,而这种方法就称为Hashing。从作用上来讲,构建哈希表的目的是把搜索的时间复杂度降低到O(1),考虑到一个长度为n的序列,如果依次去比较进行搜索的话,时间复杂度是θ(n),或者对其先进行排序然后再搜索会更快一些,但这两种方法都不是最快的方法。
一、直接寻址表
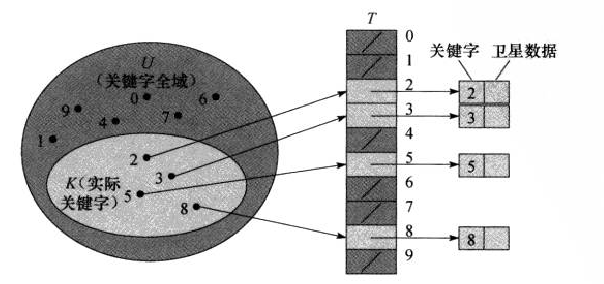
直接寻址表就是一个数组。每个数存在相应的下标内,当关键字的全域U比较小时,直接寻址是一种简单而有效的技术。比如,如果全域为U={0,1,…,m-1}。则可以使用长度为m的数组:
二、哈希表
直接寻址技术的缺点很明显:如果全域U很大,则存储大小为|U|的数组是不切实际的,而且如果实际存储的关键字集合K相对于全域U来说很小的时候,会造成巨大的浪费。此时采用散列表。
在直接寻址方式下,具有关键字k的元素存放在索引为k的位置中,在哈希表中,该元素存放在h(k)中。h()就是一个散列函数。它将关键字的全域U映射到散列表T[0..M-1]的槽位上:
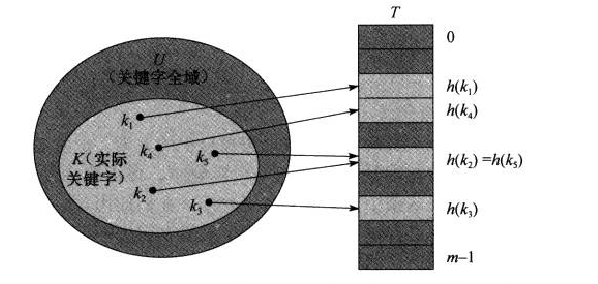
这里会存在所谓“冲突”的问题:两个关键字可能被映射到同一个槽位中。由于全域|U|>M,所以冲突是无法避免的。一个好的哈希函数产生的键值应该尽可能的均匀,这样可以减少产生冲突的次数;但是无论是何种哈希函数也不可能完全解决冲突问题,所以还应该寻找解决冲突的方法。
哈希函数
除法散列法:散列函数为h(k)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1953
1953

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









