







实际操作中我们经常需要寻找数据的某行或者某列,这里介绍我在使用Pandas时用到的两种方法:iloc和loc。
loc:通过行、列的名称或标签来索引。即用名称来确定行 列
iloc:通过行、列的索引位置来寻找数据。 即用行号 列号来确定行列位置。
先看获取特定值的情况:
- DataFrame 取指定列为某些值的行
sample_list=[2233,1122,1133,1223]
sample_prod_df = all_prod_df[all_prod_df['product_id'].isin(sample_list)]
sample_prod_df
- ps:这里返回的数据类型是 Series ,不是单纯的一个数值。直接拿去用会报错,可以加上str() 或者int() 强制转换下
- eg:
age_list.append(int(basic_info_df.loc[basic_info_df['姓名'] == "张三", "年龄"])) - loc 选取某列为某值的行
some_values = [1,2,3,4,5,6]
df.loc[df[‘column_name’].isin(some_values)]
-
选取等于某些值的行记录 用 ==
df.loc[df[‘column_name’] == some_value]
ps:这里返回的数据类型是 Series ,不是单纯的一个数值。直接拿去用会报错,可以加上str() 或者int() 强制转换下
eg:
age_list.append(int(basic_info_df.loc[basic_info_df['姓名'] == "张三", "年龄"]))
-选取某列是否是某一类型的数值 用 isin
df.loc[df[‘column_name’].isin(some_values)]
-
多种条件的选取 用 &
df.loc[(df[‘column’] == some_value) & df[‘other_column’].isin(some_values)] -
选取不等于某些值的行记录 用 !=
df.loc[df[‘column_name’] != some_value] -
isin返回一系列的数值,如果要选择不符合这个条件的数值使用~
df.loc[~df[‘column_name’].isin(some_values)
目录
首先,我们先创建一个Dataframe,生成数据,用于下面的演示
-
import pandas as pd -
import numpy as np -
# 生成DataFrame -
data = pd.DataFrame(np.arange(30).reshape((6,5)), -
columns=['A','B','C','D','E']) -
# 写入本地 -
data.to_excel("D:\\实验数据\\data.xls", sheet_name="data") -
print(data)

1.loc方法
loc方法是通过行、列的名称或者标签来寻找我们需要的值。
(1)读取第二行的值
-
# 索引第二行的值,行标签是“1” -
data1 = data.loc[1]
结果:

备注:
#下面两种语法效果相同
data.loc[1] == data.loc[1,:]
(2)读取第二列的值
-
# 读取第二列全部值 -
data2 = data.loc[ : ,"B"]
结果:

(3)同时读取某行某列
-
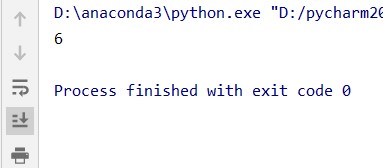
# 读取第1行,第B列对应的值 -
data3 = data.loc[ 1, "B"]
结果:
(4)读取DataFrame的某个区域
-
# 读取第1行到第3行,第B列到第D列这个区域内的值 -
data4 = data.loc[ 1:3, "B":"D"]
结果:

(5)根据条件读取
-
# 读取第B列中大于6的值 -
data5 = data.loc[ data.B > 6] #等价于 data5 = data[data.B > 6]
结果:

(6)也可以进行切片操作
-
# 进行切片操作,选择B,C,D,E四列区域内,B列大于6的值 -
data1 = data.loc[ data.B >6, ["B","C","D","E"]]
结果:

2.iloc方法
iloc方法是通过索引行、列的索引位置[index, columns]来寻找值
(1)读取第二行的值
-
# 读取第二行的值,与loc方法一样 -
data1 = data.iloc[1] -
# data1 = data.iloc[1, :],效果与上面相同
结果:

(2)读取第二列的值
-
# 读取第二列的值 -
data1 = data.iloc[:, 1]
结果:

(3)同时读取某行某列
-
# 读取第二行,第二列的值 -
data1 = data.iloc[1, 1]
结果:

(4)进行切片操作
-
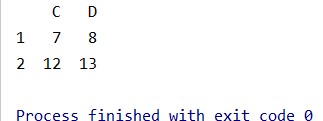
# 按index和columns进行切片操作 -
# 读取第2、3行,第3、4列 -
data1 = data.iloc[1:3, 2:4]
结果:
注意:
这里的区间是左闭右开,data.iloc[1:3, 2:4]中的第4行、第5列取不到















 853
853











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









