




source:https://juejin.cn/post/7515396214881779764
几天前,Google 悄然发布了一款小型 AI 模型,名为 Gemma 3 270M。
它体型极小,甚至能在配置极低的设备上运行。当然,也不是真的能在“土豆”(指完全无法使用的设备)上运行,但它仅需约 0.5GB 内存。这……基本上相当于没占多少内存。
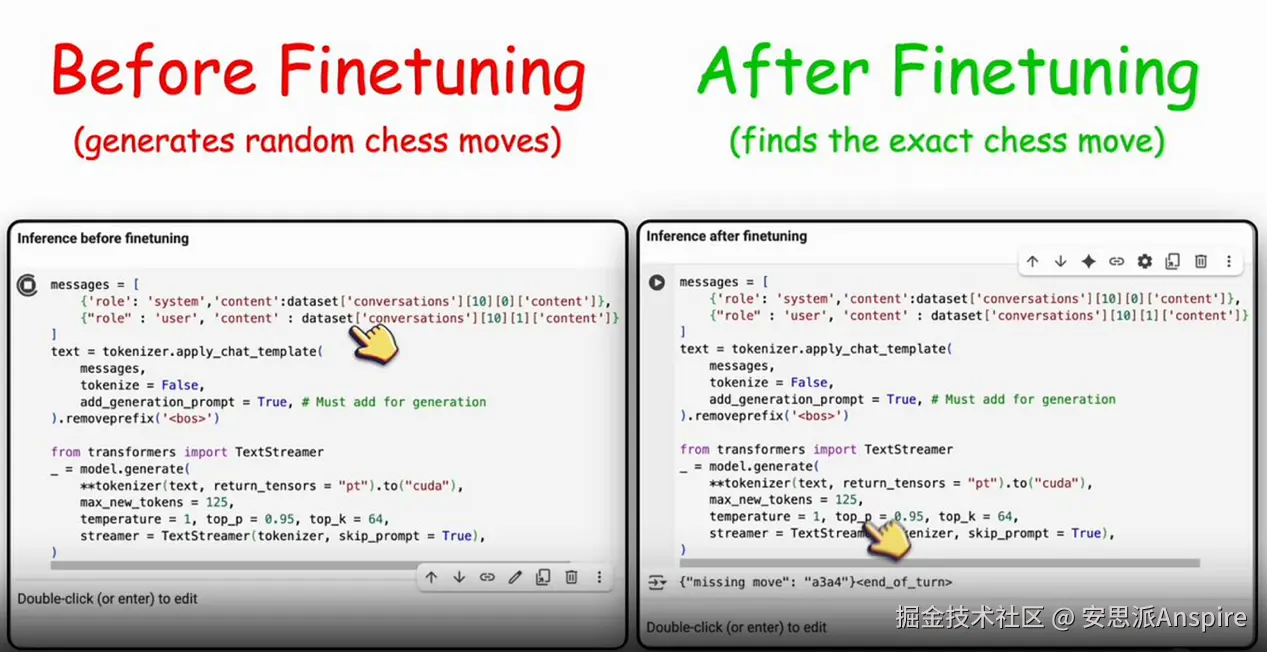
显然,我忍不住想找个有趣的方向对它进行微调,于是选择了国际象棋这个主题。
我的目标是:给它一个接近结束的国际象棋棋局,问它“缺失的走法是什么?”,看看它能否准确给出答案。
全程离线进行。不需要云端 GPU,也不会产生让我心疼的信用卡账单。
我使用的工具
以下是我为这次实验准备的小工具集:
-
Unsloth AI——能让小型模型的微调速度快到惊人。
-
Hugging Face Transformers——因为它是本地运行 LLM 的标准工具。
-
ChessInstruct 数据集——包含带有一个缺失走法的棋局,用于训练。
步骤 1:加载模型
这一步很简单。通过 Unsloth 加载 Gemma 3 即可:
ini
体验AI代码助手
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 102
102

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









