







目录
2、自动收敛测试(Automatic Convergence Test)
八、多项式回归(Polynomial Regression)
一、定义
多元线性回归指的就是一个样本有多个特征的线性回归问题。
设定:
Parameters of Model:
Vector
Vector
b is a single number
简化:
Multiple Linear Regression
notes:
n为特征的数量
点积(dot product)
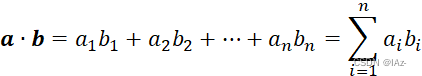
二、向量化
实施学习算法时,合理使用向量化即可以缩短代码,又可以提高运行效率。
Linear algebra:count from 1
code:count from 0
1、Without Vectorization:
f = 0
for j in range(0 , n):
f = f + w[j] * x[j]
f = f + b2、Vectorization:
import numpy as np
f = np.dot(w,x) + bnotes:
NumPy的dot函数使用并行硬件的能力使其比非向量化的for循环或者顺序计算的效率更高
三、用于多元线性回归的梯度下降法

四、特征缩放
当有不同的特征且其之间的取值范围有很大差异时,该特征可能会造成梯度下降运行缓慢,应该重新缩放不同的特征,使其都具有可比较的取值范围。
- 数量级的差异将导致量级较大的属性占据主导地位
- 数量级的差异将导致迭代收敛速度减慢
- 依赖于样本距离的算法对于数据的数量级非常敏感
优点:
提升模型的精度:在机器学习算法的目标函数中使用的许多元素(例如支持向量机的 RBF 内核或线性模型的 l1 和 l2 正则化),都是假设所有的特征都是零均值并且具有同一阶级上的方差。如果某个特征的方差比其他特征大几个数量级,那么它就会在学习算法中占据主导位置,导致学习器并不能像我们期望的那样,从其他特征中学习
提升收敛速度:对于线性模型来说,数据归一化后,寻找最优解的过程明显会变得平缓,更容易正确地收敛到最优解
1、按区间最大值缩放
按照特征取值的区间最大值,将特征元素除以其取值的最大值,缩小比例至最大为1。
eg:
取最大值缩放:
缩放后:
2、均值归一化(Mean Normalization)
从原始特征开始,重新缩放,使特征值都以0为中心,既有负值也有正值,通常介于-1和+1之间。
3、Z-score Normalization
通过减去均值然后除以标准差,将数据按比例缩放,使之落入一个小的特定区间,处理后的数据均值为0,标准差为1。
notes:
为平均值
为标准差(Standard Deviation)
4、Min-Max Normalization
将原始数据线性变换到用户指定的最大-最小值之间,处理后的数据会被压缩到 [0,1] 区间上。
五、梯度下降收敛判断
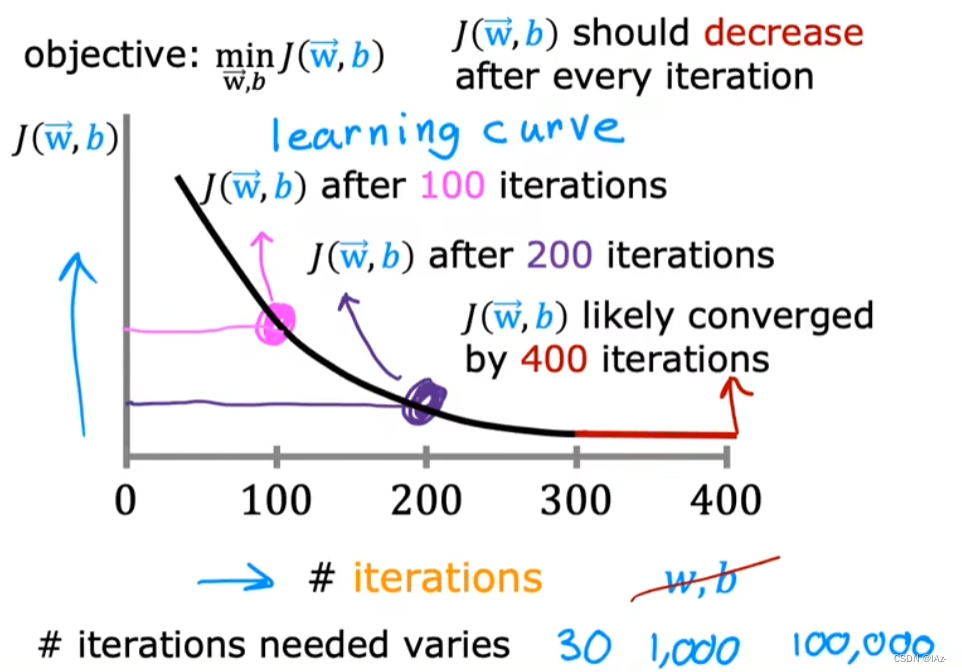
1、学习曲线图:
notes:
x轴是梯度下降算法的迭代次数,y轴是成本函数J的值
梯度下降算法的目的是:找到一组w和b,让成本函数J最小
学习曲线图可以帮助我们查看成本函数J如何变化。如果梯度下降算法工作正常,那么成本函数J在每次迭代后都会减少。如果成本函数J在一次迭代后增加,那意味着学习率α可能选的太大,或代码有bug
学习曲线图还可以帮助我们判断,梯度下降算法是否收敛。当学习曲线平坦时,梯度下降算法收敛
2、自动收敛测试(Automatic Convergence Test)

notes:
ε表示一个很小的数,如0.001
当一次迭代后,成本函数J的减少幅度小于ε,那么曲线很可能位于平坦部分,即梯度下降算法收敛,即找到一组w和b使成本函数J最小,或接近最小
因为找到这样一个正确的ε比较难,所以还是推荐采用画学习曲线图的方法,来判断梯度下降算法是否收敛,以及在多少次迭代后训练模型可以完成训练
六、学习率设定
当关于迭代次数的学习曲线图,出现波浪型或向上递增型,表示梯度下降算法出错。该情况可由,学习率α过大,或代码有bug导致。
选择一个非常非常小的学习率α,来查看学习曲线是否还是有误,即在某次迭代后增加,是否出现波浪型或向上递增型。若学习曲线正常,即保持递减,表示之前的学习率α过大。若学习曲线依旧有误,则表示代码有bug。
将学习率α设为非常非常小的数,仅用于调试,并不表示此时的α为梯度下降算法的最有效的学习率α。因为当学习率太小时,梯度下降算法可能会需要迭代很多次才能收敛。
学习率调整策略总体上可以分为两种:人工调整和策略调整。
人工调整学习率一般是根据我们的经验值进行尝试,通常我们会尝试性的将初始学习率设为:0.1,0.01,0.001,0.0001等来观察网络初始阶段epoch的loss情况。
策略调整学习率包括固定策略的学习率衰减和自适应学习率衰减,由于学习率如果连续衰减,不同的训练数据就会有不同的学习率。当学习率衰减时,在相似的训练数据下参数更新的速度也会放慢,就相当于减小了训练数据对模型训练结果的影响。为了使训练数据集中的所有数据对模型训练有相等的作用,通常是以epoch为单位衰减学习率。
七、特征工程(Feature Engineering)
创建一个新特征是特征工程的一个例子:
利用对问题的知识或直觉来设计新特征,通常是通过转换或组合问题的原始特征来使学习算法更容易做出准确地预测。(Using intuition to design new features, by transforming or combining original features.)
根据对应用场景的见解来定义新的特征,而不是仅仅采用碰巧拥有的特征,可能获得更好的模型。不仅可以对数据,拟合直线,也可以拟合曲线,非线性函数。
数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。
特征工程是使用专业背景知识和技巧处理数据,使得特征能在机器学习算法上发挥更好的作用的过程。
八、多项式回归(Polynomial Regression)
多项式回归算法是一种拟合非线性数据的回归模型。它基于原始数据构建一个新的多元函数模型,该模型可以通过线性回归来估计最优解,通过增加多项式的数量,可以获得更高阶的多项式拟合模型。
线性回归并不适用所有模型,有时我们需要用曲线来拟合我们的数据。
如果我们采用x,x²,x³作为特征,同时正在使用梯度下降算法,那么特征缩放是十分必要的,因为特征之间的可能值范围差距过大。
我们也可以使用x,√x作为特征,在特征的可能值范围很小时,也许可以不用特征缩放。
与线性模型相比,多项式模型引入了高次项,自变量的指数大于1。
多项式中的每个单项式叫做多项式的项,这些单项式中的最高项次数,就是这个多项式的次数。单项式由单个或多个变量(一般为单个x xx)和系数相乘组成,或者不含变量,即不含字母的单个系数(常数)组成,这个不含字母的项叫做常数项。
一般情况下,数据的回归函数是未知的,即使已知也难以用一个简单的函数变换转化为线性模型,所以常用的做法是多项式回归(Polynomial Regression),即使用多项式函数拟合数据。
多项式回归算法的优点是可以灵活地拟合非线性数据,并且可以通过选择适当的多项式阶数来平衡过拟合和欠拟合的问题。同时,多项式回归算法也存在一些缺点,例如对于高阶多项式的模型,容易出现过拟合问题;另外,多项式回归算法也可能会面临数据不平衡、噪声干扰等问题。
开源机器学习库Scikit-learn


















 1602
1602











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











