







激活函数详细学习参考以下资料:
深度学习: 激活函数 (Activation Functions)
优秀总结参考:
目录
一、激活函数
1、定义
激活函数(Activation Function)是神经网络中的一种数学函数,用于将输入转换为输出,并增加神经元之间的非线性特性。激活函数通常被应用于神经网络中的隐藏层和输出层,以实现非线性映射和复杂的分类和回归任务。常见的激活函数包括Sigmoid函数、ReLU函数、Tanh函数等。选择合适的激活函数可以对神经网络的性能和准确度产生重要影响。
2、常见的三种激活函数
1)、Sigmoid函数



Sigmoid函数时使用范围最广的一类非线性激活函数,具有指数函数的形状,它在物理意义上最为接近生物神经元。其自身的缺陷,最明显的就是饱和性。从函数图可以看到,其两侧导数逐渐趋近于0,杀死梯度。
不过近几年在深度学习的应用中比较少见到它的身影,因为使用Sigmoid函数容易出现梯度弥散或者梯度饱和。当神经网络的层数很多时,如果每一层的激活函数都采用Sigmoid函数的话,就会产生梯度弥散和梯度爆炸的问题,其中梯度爆炸发生的概率非常小,而梯度消失发生的概率比较大。
2)、ReLU函数

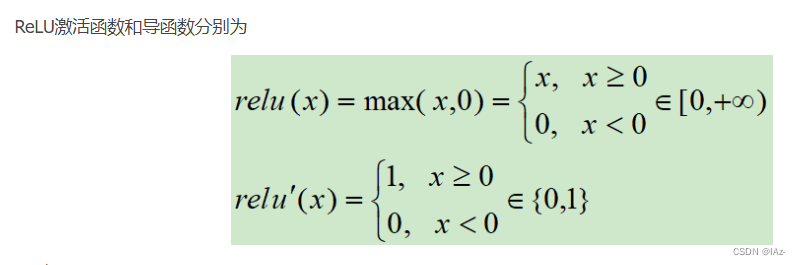

线性整流函数(Rectified Linear Unit, ReLU),又称修正线性单元,是一种人工神经网络中常用的激活函数(activation function),通常指代以斜坡函数及其变种为代表的非线性函数。
最近几年比较受欢迎的一个激活函数,无饱和区,收敛快,计算简单,有时候会比较脆弱,如果变量的更新太快,还没有找到最佳值,就进入小于零的分段就会使得梯度变为零,无法更新直接死掉了。
对于隐藏层中激活函数的选择,在神经网络中使用最多的还是ReLU 激活函数,sigmiod 函数使用的很少
一是因为 ReLU函数比sigmoid 函数计算要快些, ReLU函数只需要计算0和z,而sigmoid函数要计算倒数,取逆等,比较复杂
二是因为 ReLU激活函数只改变图形的一部分,它计算的更快
3)、Tanh函数



tanh是双曲函数中的一个,tanh() 为双曲正切,关于原点中心对称。在数学中,双曲正切 tanh 是由双曲正弦和双曲余弦这两者基本双曲函数推导而来。
正切函数时非常常见的激活函数,与Sigmoid函数相比,它的输出均值是0,使得其收敛速度要比Sigmoid快,减少迭代次数。相对于Sigmoid的好处是它的输出的均值为0,克服了第二点缺点。但是当饱和的时候还是会杀死梯度。
二、如何选择激活函数
1、为什么需要激活函数
简单来说:1,加入非线性因素 2,充分组合特征
在神经网络中,如果不对上一层结点的输出做非线性转换的话(其实相当于激活函数为 f(x)=x),再深的网络也是线性模型,只能把输入线性组合再输出,不能学习到复杂的映射关系,而这种情况就是最原始的感知机(perceptron),那么网络的逼近能力就相当有限,因此需要使用激活函数这个非线性函数做转换,这样深层神经网络表达能力就更加强大了(不再是输入的线性组合,而是几乎可以逼近任意函数)。
因此,神经网络中激励函数的作用通俗上讲就是将多个线性输入转换为非线性的关系。如果不使用激励函数的话,神经网络的每层都只是做线性变换,即使是多层输入叠加后也还是线性变换。通过激励函数引入非线性因素后,使神经网络的表达能力更强了。
2、激活函数的选择
输出层:
如果需要处理的问题是0或1的分类问题,即二元分类问题,则可以在输出层使用sigmoid函数。
如果要处理回归问题,如预测股票的涨跌问题,可以在输出层使用线性激活函数,因为线性激活函数输出可以是正的也可以是负的。如果是预测房子价格的问题,那永远都不会是负数,所以我们会在输出层使用ReLU 激活函数。
隐藏层:
ReLU激活函数时许多从业者训练神经网络的最常见选择,几乎不用sigmoid函数。
因为梯度下降优化了w,b的代价函数J而不是优化了激活函数,但是激活函数是计算的一部分,导致代价函数J有更多的部分是平坦的,梯度很小,会减慢学习速度。选择适合的激活函数可以让神经网络学习效率增加。
notes:
如果输出是0、1值(二分类问题),则输出层选择 sigmoid 函数,然后其它的所有单元都选择 ReLU 函数。这是很多激活函数的默认选择,如果在隐藏层上不确定使用哪个激活函数,那么通常会使用 ReLU 激活函数。有时,也会使用 tanh 激活函数。
在选择用于输出层的激活函数时通常取决于要预测的标签y的性质。















 603
603











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











