







1. 部署Hadoop 2.8.3, Spark 2.1.0
2. 编译和部署BigDL
编译command: ./make-dist.sh -P spark_2.x
3. 运行脚本LeNet5-on-MNIST-example.sh:
#!/bin/bash
$SPARK_HOME/bin/spark-submit \
--master yarn \
--deploy-mode client \
--driver-memory 2g \
--num-executors 6 \
--executor-cores 1 \
--executor-memory 10g \
--driver-class-path ./bigdl-master/lib/bigdl-0.5.0-SNAPSHOT-jar-with-dependencies.jar \
--class com.intel.analytics.bigdl.models.lenet.Train \
./bigdl-master/lib/bigdl-0.5.0-SNAPSHOT-jar-with-dependencies.jar \
-f hdfs://hadoop1master:8020/BigDL/Dataset/MNIST \
-b 60000 \
-e 10 \
--checkpoint /opt/modules/bigdl-master-angelps/checkpoint-models
4. 出现错误:
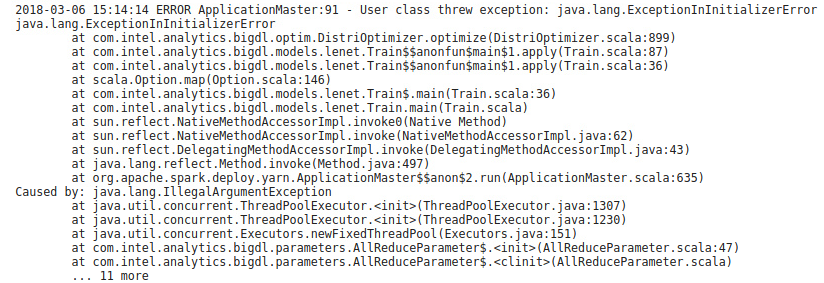
5. 发现原因
5.1
DistriOptimizer.scala: 899 的代码是
val parameters = AllReduceParameter.newParameter(partitionNum, size)
java.lang.ExceptionInInitializerError表示在静态初始化块中出现了异常,这里的静态object就是AllReduceParameter
5.2
静态初始化块异常的代码是AllReduceParameter.scala:47
java.lang.IllegalArgumentException 表示变量出现了异常
再深入代码会发现抛出异常的代码位于 ThreadPoolExecutor.java

说明异常的原因是maximumPoolSize <= 0, 也就是ComputePoolSize <=0
5.3
ComputePoolSize的计算方法为:
private val computePoolSize: Int = System.getProperty("bigdl.Parameter.computePoolSize", (Runtime.getRuntime().availableProcessors() / 2).toString).toInt
可以看出当user没有指定参数 bigdl.Parameter.computePoolSize
以及机器的core = 1 (core = Runtime.getRuntime().availableProcessors() )
ComputePoolSize = 0
从而导致异常
6. 修改方法
private val computePoolSize: Int = Math.max(System.getProperty("bigdl.Parameter.computePoolSize", (Runtime.getRuntime().availableProcessors() / 2).toString).toInt, 1)
其他:
之前运行时出现过guava 版本冲突导致的错误
发现default情况下:
Hadoop2.8.3 的 guava 是 11.0.2
Spark2.1.0 的 guava 是 14.0.1
BigDL 的 guava 是 11.0.2
于是后来编译BigDL时把pom.xml 和 spark/dl/pom.xml 中的guava版本改为了14.0.1















 776
776











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









