







0.背景
0.1当完成task调度:
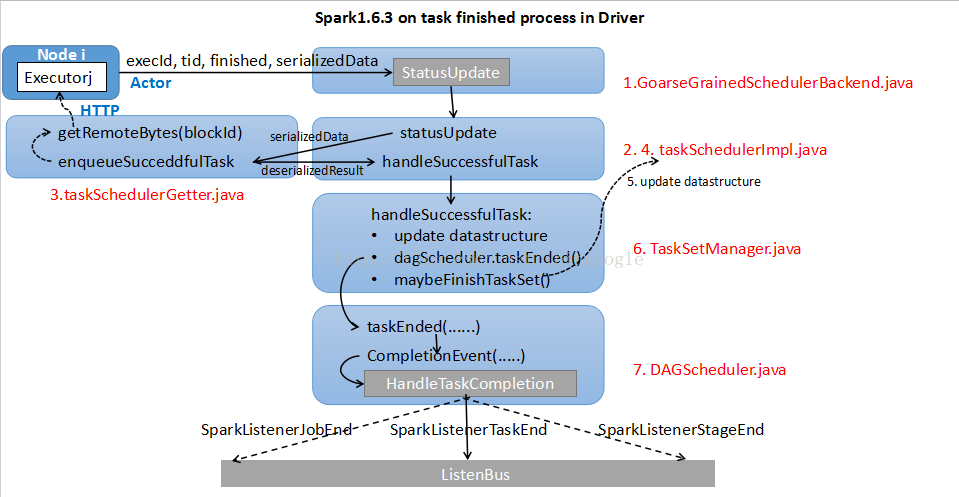
Executor就会收到serialized的 task,先deserialize 出正常的task,然后运行task得到结果,并通过状态更新的RPC告知SchedulerBackend
0.2这里主要分析GoarseGrainedSchedulerBackend.scala的情况
1.GoarseGrainedSchedulerBackend.scala 接收task完成信息
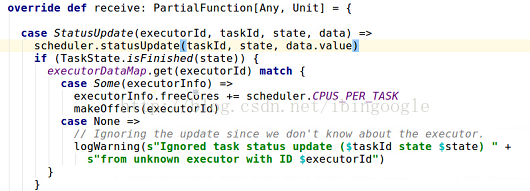
1.1 receive()函数:
接收到StatusUpdate(executorId, taskId, state, data)事件后,会把这个事件继续转到taskSchedulerImpl,调用scheduler.statusUpdate(taskId, state, data.value).
1.2 参数:
(1) state表示task的状态,这里主要讨论FINISHED的情况,如果task完成,就会运行makeOffers(executorId)继续调度剩余的task。
(2) data表示executor端传递过来的serializedData。
2.TaskSchedulerImpl.scala 初步接收task完成信息
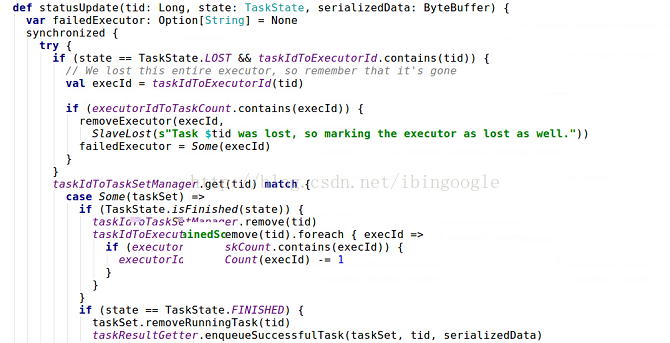
具体分析statusUpdate(tid, state, serializedData):
2.1 taskIdToTaskSerManager.get(tid) match {......}
根据taskId推出它所属于的taskSetManager
2.2 taskSet.removeRunningTask(tid)
taskResultGetter.enqueueSuccessfulTask(taskSet, tid, serializedData)
更新相关数据结构,然后使用taskResultGetter对serializedData进行反序列化
3.taskResultGetter.scala 反序列化task结果
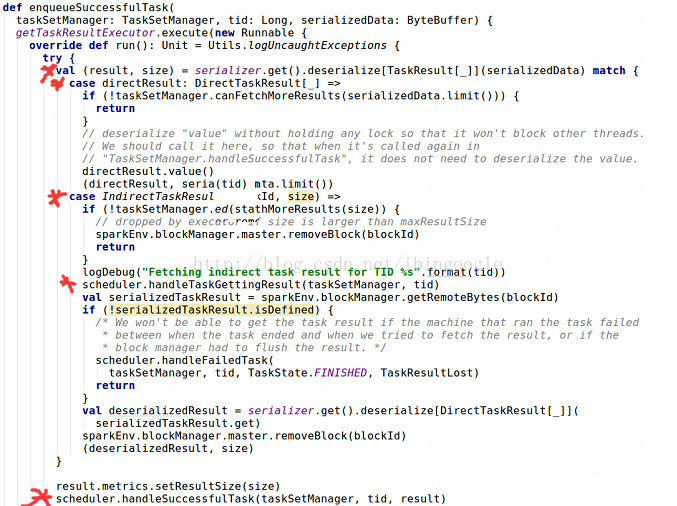
具体分析enqueueSuccessfulTask(taskSetManager, tid, serializedData)
3.1 val (result, size) = serializer.get().deserialized[TaskResult[_]](serializedData) match{......}
调用serializer将serializedData进行反序列化,这里分两种情况,说明如下:
当 task在Executor端完成后会返回其执行结果 result,并且这个结果要荣国Actor发送到driver端。但Actor发送的数据包不宜过大,因此:
(1) 当result不大时,serializedData保存的直接序列化的结果,也就是 case directResult: DirectTaskResult[_] =>,最后直接获得(directResult, serializedData.limit())
(2) 如果 result 比较大, serializedData保存的是结果存储位置blockId和结果大小size,也就是 case IndirectTaskResult(blockId, size),然后driver端会调用sparkEnv.blockManager.getRemoteBytes(blockId)通过HTTP的方式去获取serializedTaskResult,再进行第二次反序列化获得deserializedResult, 最后获得(deserializedResult, size).
3.2 scheduler.handleSuccessfulTask(taskSetManager, tid, result)
经过taskResultGetter.scala的反序列化后在回到TaskSchedulerImpl.scala
4.TaskSchedulerImpl.scala 再次接收task完成信息

taskSetManager.handleSuccessfulTask(tid, taskResult)将把task完成信息送到所属的TaskSetManager中进行处理
5.TaskSetManager.scala 接收task完成信息
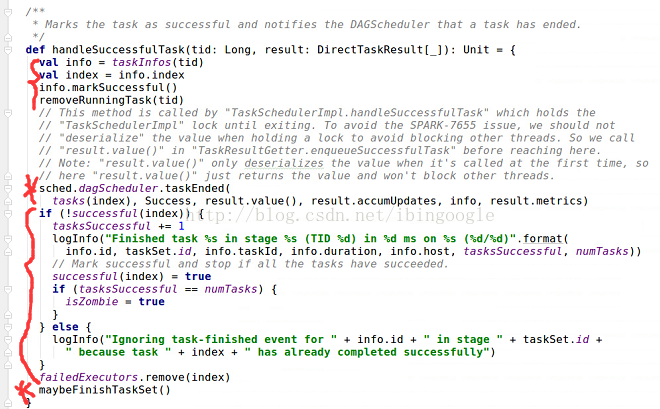
具体分析handleSuccessfulTask(tid, result)
5.1 val info = taskIndos(tid) ...... removeRunningTask(tid):
更新task相关数据结构
5.2 sched.dagScheduler.taskEnded(......)
将task完成的信息告知dagScheduler
5.3 if(!successful(index)) {......}
更新有关taskSet完成的数据结构
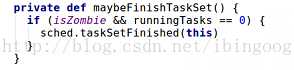
5.4 maybeFinishTaskSet()
判断taskSet是否以及完成,如果完成则调用sched.taskSetFinished(this),来告知上层的taskSchedulerImpl.scala
6.TaskSchedulerImpl.scala 接收taskSet完成信息(optional)
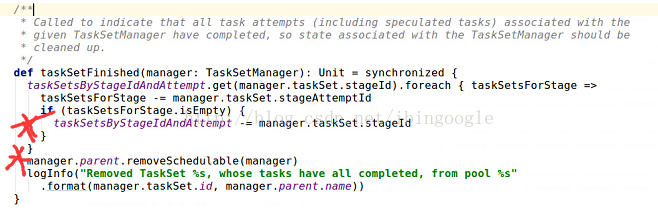
首先更新管理taskSets的数据结构taskSetsByStageIdAndAttempt, 然后调用manager.parent.removeSchedulable(manger)将这个taskSet从调度池中删除
7.DAGScheduler.scala 接收task完成信息
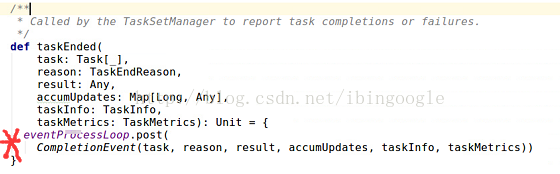
7.1 eventProcessloop:
会post出一个CompletionEvent的事件,这个事件会被DAGScheduler.scala中的doOnReveive接受并处理,然后调用dagScheduler.handleTaskCompletion(completion)

。。。。。。
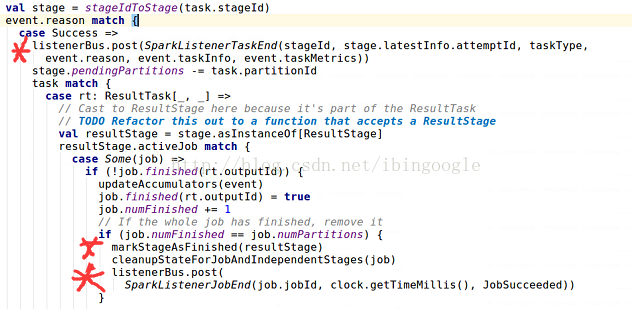
7.2 分析dagScheduler.handleTaskCompletion(completion)
(1) case Success =>
ListenerBus.post(SparkListenerTaskEnd(......))
向ListenerBus上广播taskEnd的事件,按需被接收,关于ListenerBus有待后续分析
(2) stage.pendingPartitons -= task.partitionId
task的完成表示stage最后阶段RDD的一个partition已经获得,因此更新数据结构
(3) task match {
case rt: ResultTask[_, _] =>
.......
markStageAsFinished(resultStage)
cleanupStageForJobAndIndependentStage(job)
ListenerBus.post(SparkListenerJobEnd)
如果task是ResultTask,会判断所属Job是否完成,如果完成,首先调用markStageAsFinished来post相关stage完成事件,具体实现为内部的ListenerBus.post(SparkListenerStageCompleted(......));然后调用cleanupStageForJobAndIndependentStage并根据是否有其他job需要这个stage来更新相关数据结构,主要有jobIdToStageIds和stageIdToStage;最后post出job完成的事件
(4) case smt: ShuffleMapTask =>
和上面类似,只是没有post出job完成的事件
8.画图总结

















 2296
2296

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









