






前言:本文教你五种使用stable diffusion 3的方法,让你轻松学会AI生成图像。
2024年6月12日,Stability.AI 如期开源其 Stable Diffusion 3 Medium 模型,这个中型(Medium)模型包含 20 亿个参数(另外还有SD3 Large/Turbo包含80亿参数)。因为Medium模型尺寸较小,使得它能够在消费级 PC 和笔记本电脑以及企业级 GPU 上轻松运行。新开源的模型相比之前版本有了更加大步幅度的提升,能够生成更高分辨率、更细腻真实的图像,也能够更准确地将文本描述转换为图像。
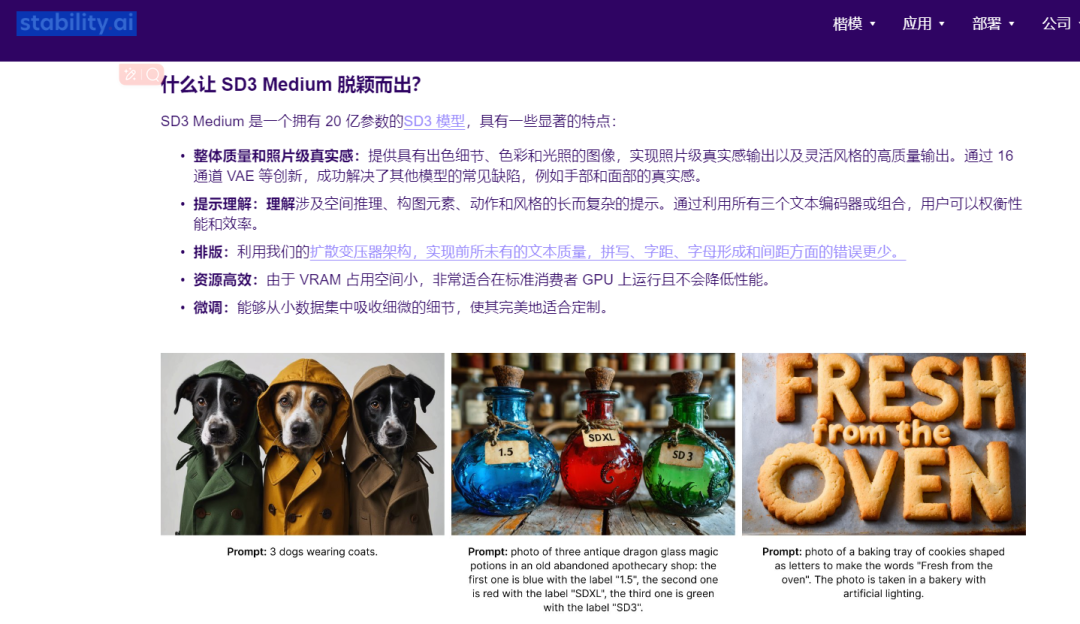
SD3 Medium 主要特点:
-
解决手部和面部瑕疵问题,通过简单提示语即可轻松生成高质量图像。
-
能够理解涉及空间关系、构图元素、动作和风格的复杂提示。
-
在生成文本方面更是表现出色,无人工痕迹和拼写错误。
-
低 VRAM 占用率,适用于普通电脑以及消费级GPU。
-
能够从小数据集获取到更多的细微细节,定制生成更加精细的画面。
废话少说,马上行动,下面小编教你五种使用stable diffusion 3的方法,让你轻松学会AI生图像。
1-使用官方Playground
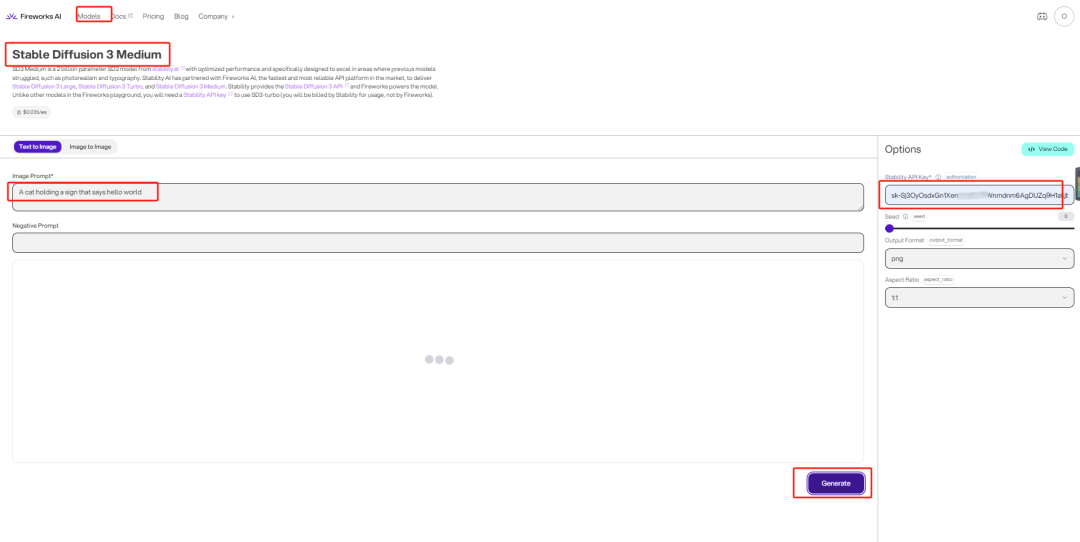
特点:Playground的主要特点是可以通过浏览器登录直接使用,不需要高性能GPU也可以使用SD3,支持文生图和图生图两种模式。底层逻辑实际是通过http访问官方服务器来生成图像,源码如下。
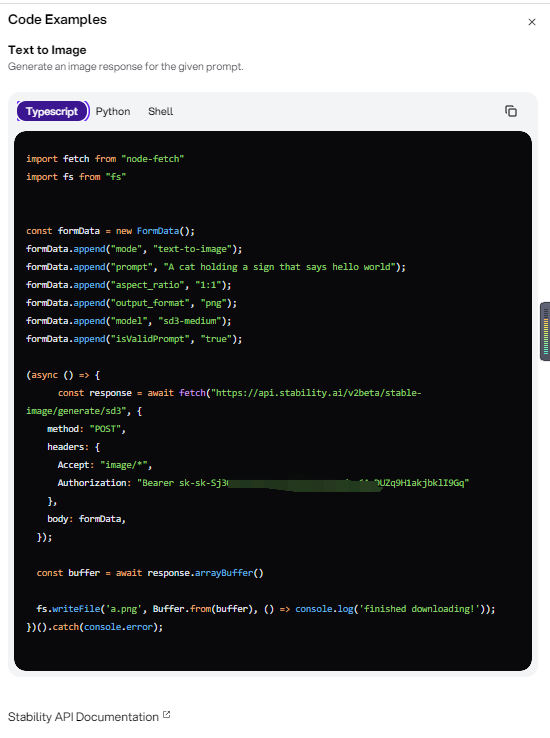
访问地址:https://fireworks.ai/models
使用方法:
-
选择模型-Stable Diffusion 3 Medium
-
选择模式-Text To Image 或者 Image To Image
-
填写提示词-填写生图的正向/反向Prompt词
-
填写API key,申请方式-https://platform.stability.ai/account/keys
-
点击生成"generate", 等待图像生成
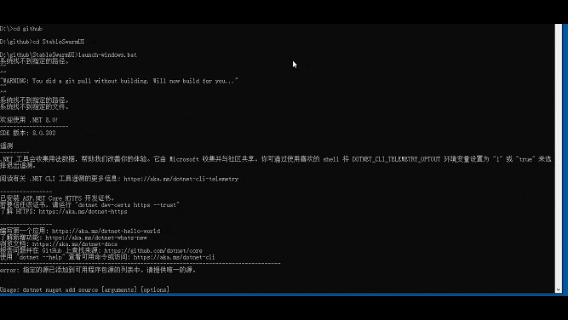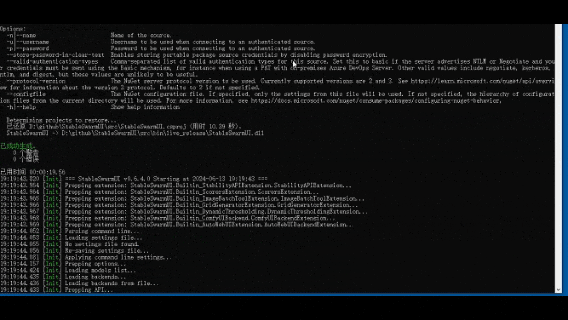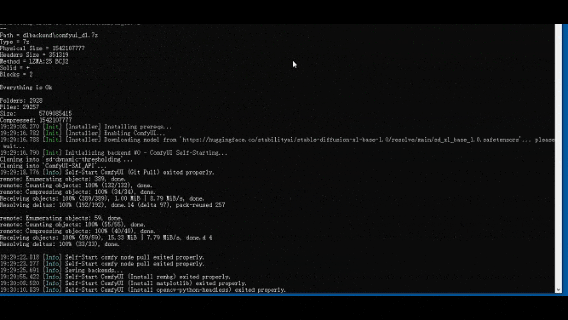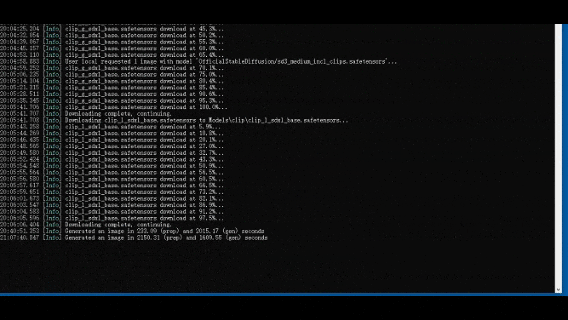
2-使用StableSwarmUI
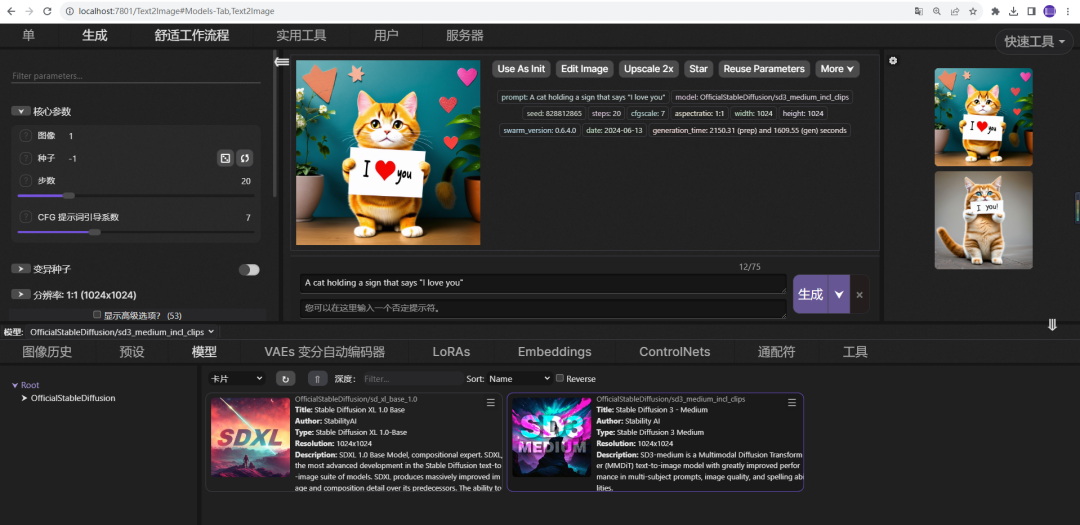
特点:官方开源的Stable Diffusion Web UI界面。本地部署后就可以通过浏览器操作,非常简单方便,性能和可扩展性都非常好,不过需要本地GPU计算资源。
代码地址:https://github.com/Stability-AI/StableSwarmUI
环境安装:
-
安装 git 工具 https://git-scm.com/download/win
-
安装DotNET 8 SDK 工具 https://dotnet.microsoft.com/en-us/download/dotnet/8.0
-
安装工具在windows终端执行如下命令:
git clone https://github.com/Stability-AI/StableSwarmUI``cd StableSwarmUI``launch-windows.bat
使用方法:
-
下载模型-地址https://huggingface.co/stabilityai/stable-diffusion-3-medium/tree/main
-
放置路径-StableSwarmUI\Models\Stable-Diffusion\OfficialStableDiffusion
-
运行服务:launch-windows.bat
-
浏览器输入:http://localhost:7801/
-
在WebUI中:选择对应模型,输入prompt,点击生成即可生成图像
3-使用ComfyUI

特点:ComfyUI,一款基于节点工作流稳定扩散算法的全新WebUI。通过将稳定扩散的流程巧妙分解成各个节点,成功实现了工作流的精准定制和可靠复现。在图像生成方面,它不仅比传统的WebUI更迅速,而且显存占用更为经济。
下载地址:https://github.com/comfyanonymous/ComfyUI
环境安装:建议在虚拟环境中安装,这样减少工具版本之间的冲突。
conda create -n diffusers python=3.9` `conda activate diffusers` ` ``pip install -U diffusers` `pip install transformers` `pip install sentencepiece` `conda install protobuf` `pip install torch==2.1.2+cu118 torchvision==0.16.2+cu118 torchaudio==2.1.2 --extra-index-url https://download.pytorch.org/whl/cu118``git clone https://github.com/comfyanonymous/ComfyUI.git``cd ComfyUI``pip install scipy``pip install torchsde``pip install aiohttp``python main.py
使用方法:
-
下载模型-地址https://huggingface.co/stabilityai/stable-diffusion-3-medium/tree/main
-
放置路径:ComfyUI\models\checkpoints
-
运行命令:python main.py
-
浏览器输入:http://127.0.0.1:8188/
-
在Web UI中:选择模型,输入prompt,点击Queue Prompt即可生成图像
4-使用API方式
**特点:**使用API方式,主要针对二次开发者,用户可以灵活定制自己的UI,通过二次开发可以扩展更多应用模式。API有两种开发方式:1-使用HTTP方式直接访问stability.ai服务器,这种方式不需要开发者需要高性能服务器。2-使用stability.ai提供的diffusers库进行开发。
环境安装:
conda create -n diffusers python=3.9` `conda activate diffusers` ` ``pip install -U diffusers` `pip install transformers` `pip install sentencepiece` `conda install protobuf` `pip install torch==2.1.2+cu118 torchvision==0.16.2+cu118 torchaudio==2.1.2 --extra-index-url https://download.pytorch.org/whl/cu118`` ``#git lfs install` `#git clone https://huggingface.co/stabilityai/stable-diffusion-3-medium-diffusers``
使用方法:
首先,需要开发者在stability.ai开发者平台上申请API key和access_token
参考文档:https://platform.stability.ai/docs/getting-started
生成access_token:https://huggingface.co/settings/tokens
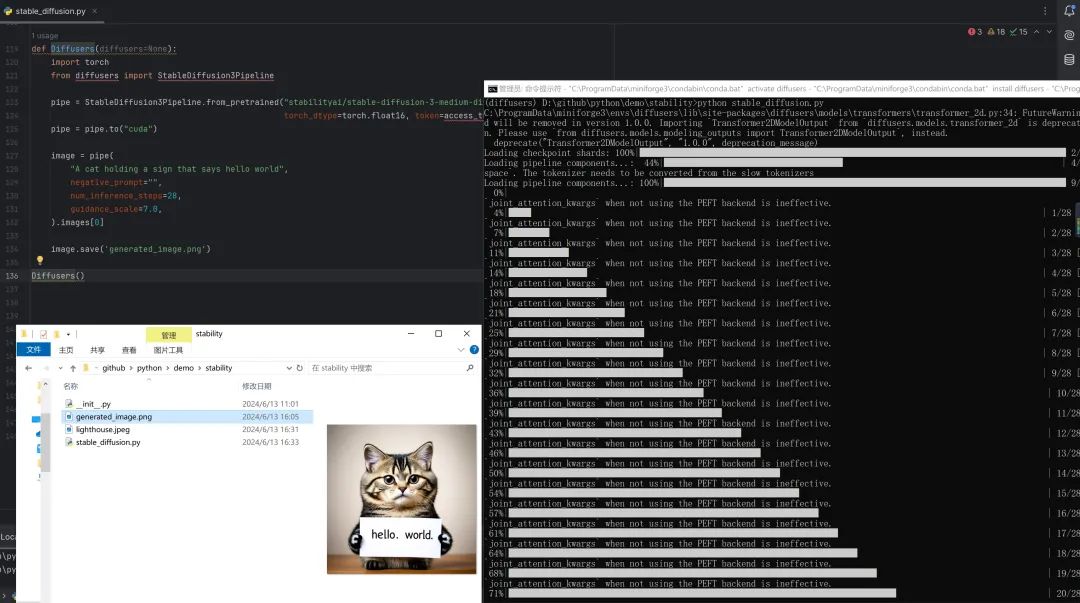
其次,根据参考文档,编写源代码。这里我们使用了python语言来编写参考例子,编写好的源码保存为文件:stable_diffusion.py
``def Diffusers(diffusers=None):` `pipe = StableDiffusion3Pipeline.from_pretrained("stabilityai/stable-diffusion-3-medium-diffusers",` `torch_dtype=torch.float16, token=access_token)` `pipe = pipe.to("cuda")` `image = pipe(` `"A cat holding a sign that says hello world",` `negative_prompt="",` `num_inference_steps=28,` `guidance_scale=7.0,` `).images[0]` `image.save('generated_image.png')` `Diffusers()
最后,在终端中运行python stable_diffusion.py 在同目录下生成:generated_image.png

5-第三方平台
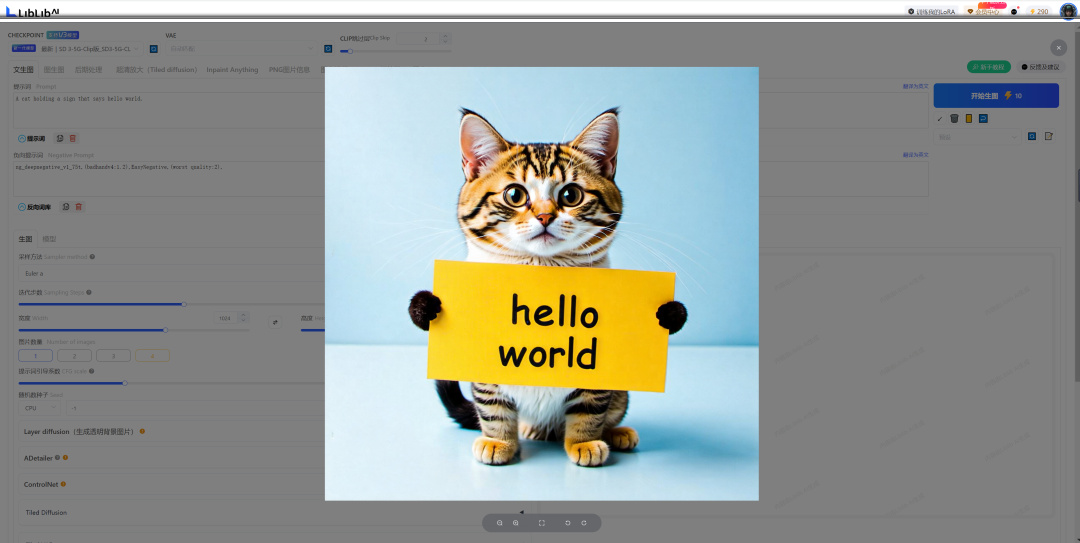
特点:推荐liblib平台,目前已经支持SD3,新用户每日送300虚拟币,每次生图消耗10个币,消耗完之后需要花$购买。如果是入门小白,这种方法是最简单的,不需要科学上网,不需要配置高性能服务器和GPU。
下载地址:https://www.liblib.art/sd
使用方式:登录上面网址,通过QQ或者微信注册就可以直接使用,非常方便简单。
总结:
-
如果你是小白用户,只想体验一下,推荐使用最后一种方式;
-
如果你想搭建自己服务器,享受绘图自由,建议使用comfyUI/StableSwarmUI方式;
-
如果你是二次开发者,建议使用API方式。
敲码不易,欢迎点赞和转发!
写在最后
感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。

AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。


若有侵权,请联系删除!















 3084
3084

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









