







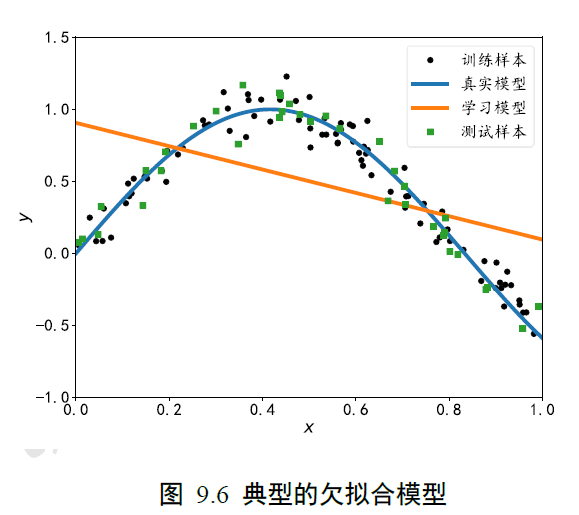
欠拟合
模型在训练集上误差一直维持较高的状态,很难优化减少,同时在测试集上也表现不佳,我们可以考虑是否出现了欠拟合的现象。
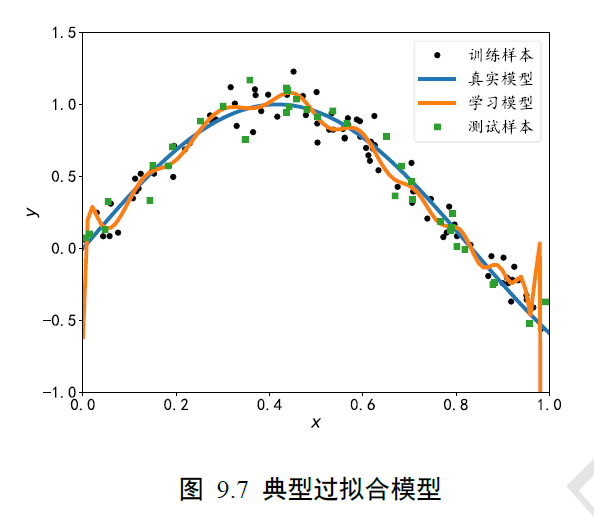
过拟合
模型在训练样本上的误差非常小,甚至比真实模型在训练集上的误差还要小。但是对于测试样本,模型性能急剧下降,泛化能力非常差。
数据集划分

- 训练集:用来训练模型
- 验证集:用来筛选模型
- 测试集:用来测试已经训练好的模型
交叉验证
首选,测试数据集是不参与数据的训练。剩下训练集和验证集,如果只用训练集来训练模型,那么验证集的数据相当于浪费了。为了使得这些数据都能充分利用起来,这里要使用到交叉验证:
假设训练集和验证集一共60k,用[1, 2, 3, 4, 5, 6]来表示
第一次:1-5当作数据集,6当作验证集
第二次:1-4和6当作数据集,5当作验证集
第三次:1-3和5-6当作数据集,4当作验证集
以此类推
这样可以使得所有数据都能参与模型训练,在一定程度上可以提升模型的能力。
用model.fit实现上面的操作:
model.fit(db_train_val, epoch=6, validation_split=0.1, validation_freq=2)
# db_train_val 所有数据,包括数据集和验证集
# epoch 参数指定训练迭代的Epoch 数量
# validation_split 把所有数据怎么划分,这里0.1表示,验证集占所有数据的0.1,数据集占所有数据的0.9。会动态划分,虽然占比固定,但是每次划分的内容不固定
# validation_freq 验证的频率
正则化
通过限制网络参数的稀疏性,可以来约束网络的实际容量。
L1正则
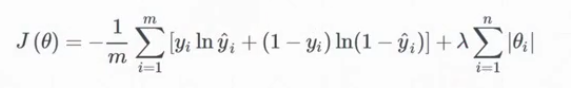
L正则
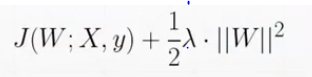
使用
调用如下:
network = Sequential([
layers.Dense(256, activation='relu', kernel_regularizer=tf.keras.regularizers.l1(0.001)),
layers.Dense(128, activation='relu', kernel_regularizer=tf.keras.regularizers.l2(0.001)),
layers.Dense(10)
])
Dropout
Dropout可以作为训练深度神经网络的一种trick供选择。在每个训练批次中,通过忽略一半的特征检测器(让一半的隐层节点值为0),可以明显地减少过拟合现象。这种方式可以减少特征检测器(隐层节点)间的相互作用,检测器相互作用是指某些检测器依赖其他检测器才能发挥作用。( 我们在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征)
#具体实现如下:
network = Sequential([
layers.Dense(256, activation='relu'),
layers.Dropout(0.4),
layers.Dense(128, activation='relu'),
layers.Dropout(0.4),
layers.Dense(64, activation='relu'),
layers.Dense(32, activation='relu'),
layers.Dense(10)
])















 301
301











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









