






实时数据复制技术在银行、电信、保险、政务和电商等领域应用非常广泛。

比如银行领域的收单业务涉及收单行、银行卡组织及发卡行的数据同步。收单行的数据需要传输到银行卡组织,再由银行卡组织传输给发卡行。
如果收单业务不能做到这几点,则会出现建设银行的POS机只能刷建设银行的卡,招商银行的POS机只能刷招商银行的卡的情况。或者用户刷卡完毕后,商家需要电话询问收单行用户是否有足够余额,收单行再去询问银行卡组织,银行卡组织再去询问发卡行。这样需要消耗大量设备、人力和时间,造成用户体验下降,挫伤用户的用卡积极性。
比如小汽车违章处理业务需要在全车各地车管所同步违章记录和处理情况等数据,便于驾驶人在全国各地处理。这些业务场景均需要数据及时、可靠和稳定的进行传输和交换。
如果小汽车违章处理业务不能做到这几点,则驾驶人只能去违章地或车辆登记地处理,对于异地违章处理成本极高。电商系统中的用户分析业务需要从大量的分表中提取用户数据,同步到大数据平台进行分析,其业务量非常大,传统的数据抽取对业务系统影响极大。
在以上的业务场景中,数据交换涉及异地、异质和异构等因素影响。异地指数据库往往们于不同的数据中心,涉及可靠性、安全性和稳定性的影响。异质指不同的数据库类型,涉及底层存储和处理技术差异的影响;异构指不同的数据库结构,涉及数据重构的影响,而且很多需求都是在系统上线后产生的,很多原因决定不能对应用系统进行大量重构。
因此,实时数据交换的困难非常大,那么,我们应该如何解决呢?
一.“数据隧道”
我们在实践中,用了新的思路来解决这些问题。百分点“数据隧道”就像石油管道一样,石油源源不断地从油井流向各地,而不用使用轮船、火车和汽车等进行运输。

“数据隧道”技术的目标是通过简单配置即可完成MySQL、Oracle、SQL Server和DB2等数据库的增量数据捕获任务,传输给外部系统完成数据的实时和批量消费,满足极高的一致性、及时性和可靠性的数据接口传输要求。
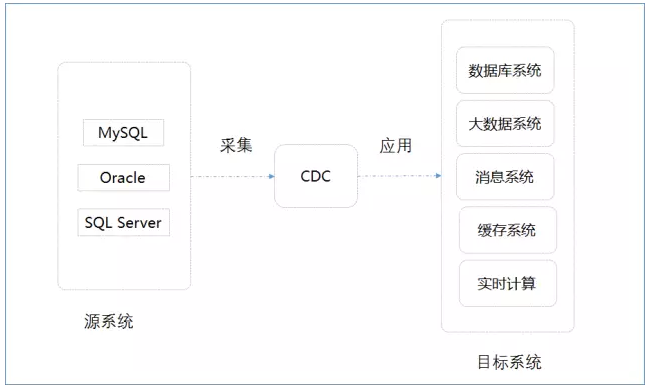
“数据隧道”整体架构图
具体来说,目前百分点“数据隧道”支持MySQL、Oracle和SQL Server的日志提取,实时复制到外部数据库、Kafka和Hive等系统。对于后端数据消费,百分点“数据隧道”可以提供实时应用、实时流处理、闪回查询、快照表处理和拉链表处理的支持,为实时数据复制、实时数据处理、ODS和数据仓库提供便利。后续将通过一个用户案例来介绍“数据隧道”如何满足用户的数据交换需求。

对比传统做法,“数据隧道”具有的系统优势体现在以下几个方面:
- 数据接入无需开发,大大缩减项目工时和风险
- 数据传输的一致性、及时性和可靠性极强
- 通过数据库日志提取变更,侵入性小,开销极低
- 支持MySQL、Oracle和SQL Server主流版本的数据接入
- 支持实时复制到Kafka和Hive系统,方便实时和批量数据消费
- 支持自定义插件实现到任意缓存、消息队列和数据库的复制
- 支持自定义函数实现数据的任意重构
- 自动化实现历史数据迁移
- 自动化实现目标库表结构生成
- 支持库级、表级和行级并行复制
- 支持MySQL DDL审计
- 适用于ODS、DW和实时数据消费等场景
- 支持Hive闪回查询、快照表处理和拉链表处理
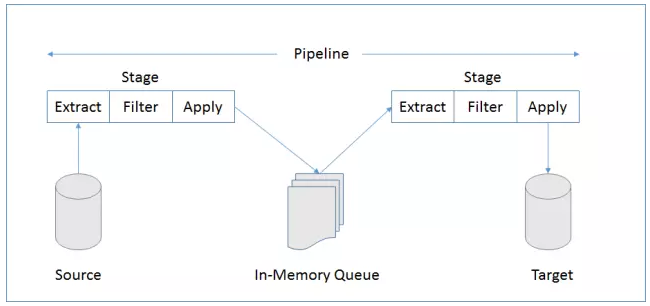
“数据隧道”Pipeline架构图
二.用户案例
某银行拥有1亿用户,用户数据由分布式关系数据库来承载,采用库分表方式进行管理。该银行期望对用户数据进行分析,以推进企业的精细化管理水平,同时对整个数据分析项目有如下要求:
1. 用户数据量比较大,数据采集不能对业务系统性能产生影响。
2. 数据库采用分库分表方式进行存储,数据采集要考虑到数据分片的影响,并且数据分片间需要保证强一致性,防止出现分析数据异常。
3. 数据采集必须兼容大数据平台,尽可能避免手工编码。
4. 用户期望实时处理和批量处理相结合,满足不同的业务场景。
该银行的用户由自主研发的CRM系统来管理。新用户注册则新增用户表记录,用户资料变更则更新用户表相关记录,用户注销则删除用户表相关记录。
用户实时分析
实时分析截止至今日、月初的新增、净增和累计用户数,其中新增用户数为该系统新注册用户,净增用户数为新增用户数与注销用户数差值,累计用户数为系统当前所有用户数。该案例中新增用户数由INSERT行数计算,注销用户数由DELETE行数计算,净增用户数为新增用户数减注销用户数,累计用户数则由上一日累计用户数加净增用户数得出。
- Time : 源数据库发生该事件的时间,即Commit的时间。
- Latency : 源数据库变更到提交入Kafka的时间延迟。
- Seqno : 系统对源数据库事务的顺序编号。
- EventID : 系统对源数据库事务的事件起始位编号。
- Row : 某事务内影响的行的顺序编号,如Seqno为1的事务中有一笔Insert插入1条数据,一笔Update更新到2条数据,最后一笔Delete删除到3条数据,则Row从1到6分别代表这6行的变更序号。
- Action : INSERT、UPDATE、DELETE、CREATE_TABLE、DROP_TABLE等,其中INSERT、UPDATE和DELETE所有数据库均适用,其它类Action则与相关数据库有关,Oracle暂时没有其它类Action。
- Before和After : 对于DELETE事件,Before块填充数据,无After块。对于INSERT事件,无Before块,After块填充数据。对于UPDATE事件,Before块填充更新前的值,After块填充更新后的值。
INSERT块
{
"Time": "2014-10-10 13:50:52.0",
"Latency": 0,
"Seqno": 1,
"EventID": "my:46460573",
"Row": 1,
"Schema": "CRM",
"Table": "USER",
"Action": "INSERT",
"After": {
"ID": "1",
"Name": "Jim",
"Birthday": "1988-10-09 19:48:10.656",
"Company": "Baifendian",
"Money": "8000"
}
}UPDATE块
{
"Time": "2015-10-10 13:50:52.0",
"Latency": 0,
"Seqno": 2,
"EventID": "my:56460573",
"Row": 1,
"Schema": "CRM",
"Table": "USER",
"Action": "UPDATE",
"Before": {
"ID": "1",
"Name": "Jim",
"Birthday": "1988-10-09 19:48:10.656",
"Company": "Baifendian",
"Money": "8000"
},
"After": {
"ID": "1",
"Name": "Jim",
"Birthday": "2015-10-09 19:48:10.656",
"Company": "Baifendian",
"Money": "10000"
}
}实时复制
Kafka Applier配置:
# Kafka applier configuration.
replicator.applier.dbms=com.continuent.tungsten.replicator.applier.KafkaApplier
replicator.applier.dbms.dataSource=global
replicator.applier.dbms.zkConnect=172.24.4.18:2171/kafka
replicator.applier.dbms.kafkaBroker=192.24.4.10:9092,192.24.4.11:9092,192.24.4.12:9092
replicator.applier.dbms.kafkaSerializer=kafka.serializer.StringEncoder
# kafkaTopicPrefix value can be Baifendian.Input. which is categoried by organization unit or system or both.
replicator.applier.dbms.kafkaTopicPrefix=cdc.
# kafkaTopicRotationInterval value can be 1d(Rotate every day),6h(Rotate every 6 hours),10m(Rotate every 10 minutes) or empty(Never rotate)
replicator.applier.dbms.kafkaTopicRotationInterval=1d流式处理
百分点“数据隧道”直接将数据库变更数据复制到Kafka,Storm或Flink基于Kafka内的变更数据实时计算新增用户、净增用户、注销用户和累计用户数。
用户离线分析
分析每日用户新增、净增和累计用户数,其中新增用户数为该系统新注册用户,净增用户数为新增用户数与注销用户数差值,累计用户数为系统当前所有用户数。该案例中新增用户数由INSERT行数计算,注销用户数由DELETE行数计算,净增用户数为新增用户数减注销用户数,累计用户数则由上一日累计用户数加净增用户数得出。
实时复制
百分点“数据隧道”可以根据事件时间按Hive分区表方式实时复制数据。HdfsApplier以多个HDFS文件流的方式将变更数据并行写入HDFS文件系统。Hive使用外部表对底层数据进行查询。
HDFS Applier配置:
# HDFS applier configuration.
replicator.applier.dbms=com.continuent.tungsten.replicator.applier.HdfsApplier
replicator.applier.dbms.dataSource=global
replicator.applier.dbms.hdfsConfURI=
replicator.applier.dbms.hdfsURI=hdfs://hostname:8020
replicator.applier.dbms.hdfsPrefix=/user/hive/warehouse
replicator.applier.dbms.hdfsUser=hdfs
replicator.applier.dbms.hdfsSyncInterval=10
replicator.applier.dbms.hdfsRotationInterval=1d
replicator.applier.dbms.hdfsRotationTimezone=8
replicator.applier.dbms.maxFDs=20
replicator.applier.dbms.hdfsSchemaPrefix=
replicator.applier.dbms.hdfsTablePrefix=chg_
replicator.applier.dbms.fieldDelimiter=\\001
replicator.applier.dbms.lineDelimiter=离线计算
通过以下查询可以获得用户表任意时点的快照。基于此原理,百分点“数据隧道”可以支持闪回查询、数据快照、数据拉链等应用。由于“数据隧道”可精确捕获数据的操作时间和操作类型,因此新增用户、净增用户、注销用户和累计用户数的计算也变得非常简单。
select * from (
select row_number() over(partition by userid order by seqno desc, row desc) as R,*
from USER where time <= '2016-01-01 00:00:00') snapshot
where R= 1 and action <> 'D';三.总结
百分点“数据隧道”能够实时提取MySQL、Oracle和SQL Server的数据变更,并且可以对变更数据进行实时转换,再应用于数据库系统、大数据系统、消息系统、缓存系统和实时计算,满足银行、电信、保险、政务和电商等领域的数据交换需求。
作者介绍:王高飞,百分点高级研发工程师,郑州大学管理学学士,擅长数据仓库建设、实时和批量数据复制技术及大数据技术。曾就职于亚信国际,独立完成挪威电信在丹麦和匈牙利市场的ODS和数据仓库项目架构设计,深得客户认可。
更多精彩,欢迎关注CSDN大数据公众号!
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









