







 本文介绍了ResNet模型的核心——bottleneck残差模块,该模块通过1*1、3*3、1*1的卷积结构减少参数,实现更深的网络结构。利用shortcut或skip connection,ResNet能够有效解决深层网络的梯度消失问题。
本文介绍了ResNet模型的核心——bottleneck残差模块,该模块通过1*1、3*3、1*1的卷积结构减少参数,实现更深的网络结构。利用shortcut或skip connection,ResNet能够有效解决深层网络的梯度消失问题。
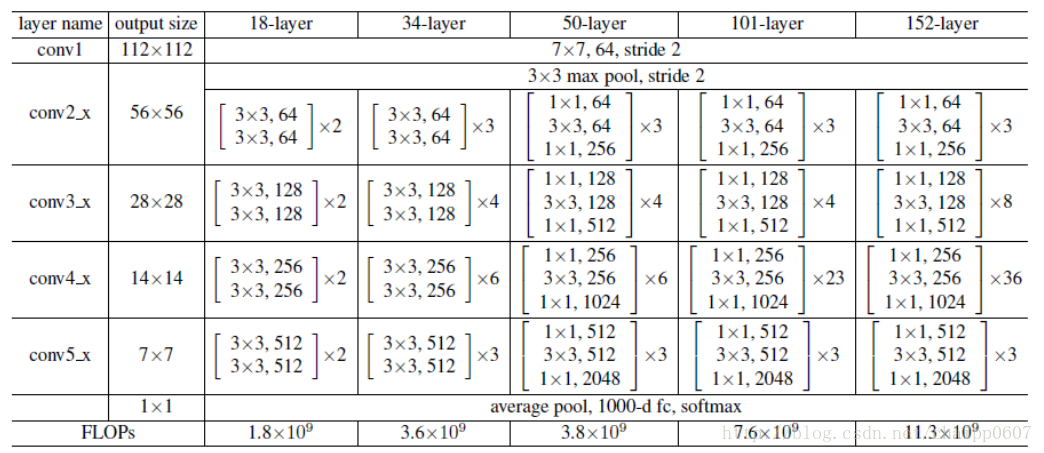
各种层数的残差网络:
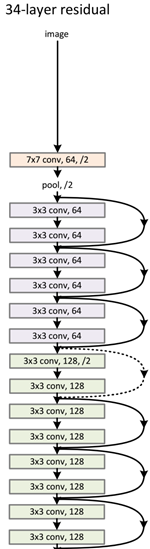
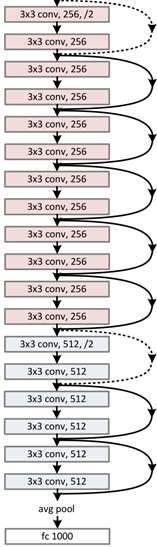
34-layer的残差网络结构:
ResNet 的核心结构——bottleneck残差模块:
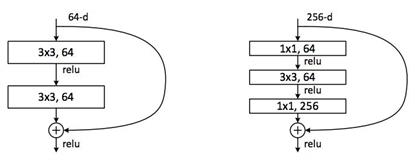
在通道数相同情况下,bottleneck残差模块要比朴素残差模块节省大量的参数,一个单元内的参数少了,就可以做出更深的结构。从上面两个图可以看到,bottleneck残差模块将两个3*3换成了1*1、3*3、1*1的形式,这就达到了减少参数的目的。和Inception中的1*1卷积核作用相同。
这种结构也称为 shortcut 或 skip connection。
# -*- coding:UTF-8 -*-
import collections
import tensorflow as tf
from tf.contrib.layers.python.layers import utils
slim = tf.contrib.slim
class Block(collections.namedtuple('Block', ['scope', 'unit_fn', 'args'])):
'''
使用collections.namedtuple设计ResNet基本block模块组的named tuple,
定义一个典型的Block需要输入三个参数:
scope: Block的名称
unit_fn:ResNet V2中的残差学习单元
args: 它决定该block有几层,格式是[(depth, depth_bottleneck, stride)]
示例:Block('block1', bottleneck, [(256,64,1),(256,64,1),(256,64,2)])
'''
def subsample(inputs, factor, scope=None):
if factor == 1:
return inputs
else:
return slim.max_pool2d(inputs, [1, 1], stride=factor, scope=scope)
def conv2d_same(inputs, num_outputs, kernel_size, stride, scope=None):
"""
if stride>1, then we do explicit zero-padding, followed by conv2d with 'VALID' padding
"""
if stride == 1:
return slim.conv2d(inputs, num_outputs, kernel_size, stride=1, padding='SAME', scope=scope)
else:
pad_total = kernel_size - 1
pad_beg = pad_total // 2
pad_end = pad_total - pad_beg
inputs = tf.pad(inputs, [[0, 0], [pad_beg, pad_end], [pad_beg, pad_end], [0, 0]])
return slim.conv2d(inputs, num_outputs, kernel_size, stride=stride, padding='VALID', scope=scope)
#---------------------定义堆叠Blocks的函数-------------------
@slim.add_arg_scope
def stack_blocks_dense(net, blocks, outputs_collections=None): 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 491
491

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









