









Bert是基于transformer 的Encoder作为特征提取器的一个预训练模型。
首先来看Transformer结构图.

transformer一开始是用来做机器翻译的模型。所以他是一个传统的Seq2Seq结构,包括一个Encoder和Decoder。
而Bert只用到了Encoder的部分,及下图所示。包含N个相同的transformer-Encoder。
每一个transfromer-Encoder包含两个子模块:Multi-Head-Attention和Feed-Forward
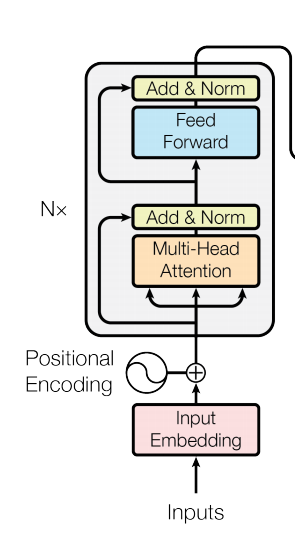
其中,Multi-Head-Attention主要包括scaled Dot-Product Attention

其中,Scaled Dot-Product Attention公式主要为:
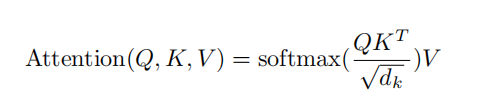
和其他的attention不同在于,加入了缩放。原文的解释是为了防止dk的点积过大,从而将梯度推入极小的区域,所以加入了缩放。
Multi-Head-Attention,主要是将Q,K,V进行了多种线性变换(多个head关注不同的特征),然后经过Sacled Dot-Product Attention
在经过concat,导入Linear层。
下面着重解释一下Bert的Embedding 和Multi-Head-Attention代码。代码采用pytorch的transformers库。

class BertEmbeddings(nn.Module):
"""Construct the embeddings from word, position and token_type embeddings."""
def __init__(self, config):
super().__init__()
# 创建三种embedding,word_embedding,position_embedding,type_embedding
# 输入张量的维度均为[batch_size,seq_len]
# 经过embedding的lookup之后,得到[batch_size,seq_len,hidden_size]
self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, padding_idx=config.pad_token_id)
self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)
self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)
# self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load
# any TensorFlow checkpoint file
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
# position_ids (1, len position emb) is contiguous in memory and exported when serialized
self.register_buffer("position_ids", torch.arange(config.max_position_embeddings).expand((1, -1)))
self.position_embedding_type = getattr(config, "position_embedding_type", "absolute")
def forward(self, input_ids=None, token_type_ids=None, position_ids=None, inputs_embeds=None):
if input_ids is not None:
input_shape = input_ids.size()
else:
input_shape = inputs_embeds.size()[:-1]
seq_length = input_shape[1]
if position_ids is None:
position_ids = self.position_ids[:, :seq_length]
if token_type_ids is None:
token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=self.position_ids.device)
if inputs_embeds is None:
inputs_embeds = self.word_embeddings(input_ids)
position_embeddings = self.position_embeddings(position_ids)
token_type_embeddings = self.token_type_embeddings(token_type_ids)
# 3种embedding相加,经过layer norm和dropout,输出embedding,维度为[batch_size,seq_len,hidden_size]
embeddings = inputs_embeds + position_embeddings + token_type_embeddings
embeddings = self.LayerNorm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings
class BertSelfAttention(nn.Module):
def __init__(self, config):
super().__init__()
if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
raise ValueError(
"The hidden size (%d) is not a multiple of the number of attention "
"heads (%d)" % (config.hidden_size, config.num_attention_heads)
)
self.num_attention_heads = config.num_attention_heads
self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.query = nn.Linear(config.hidden_size, self.all_head_size)
self.key = nn.Linear(config.hidden_size, self.all_head_size)
self.value = nn.Linear(config.hidden_size, self.all_head_size)
self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
self.position_embedding_type = getattr(config, "position_embedding_type", "absolute")
if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
self.max_position_embeddings = config.max_position_embeddings
self.distance_embedding = nn.Embedding(2 * config.max_position_embeddings - 1, self.attention_head_size)
def transpose_for_scores(self, x):
# 输入的x 维度[batch_size,seq_len,hidden_size]
# new_x_shape即为[batch_size,seq_len,head_num,head_size]
# x 转置后 [batch_size,head_num,seq_len,head_size]
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
x = x.view(*new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(
self,
hidden_states,
attention_mask=None,
head_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
output_attentions=False,
):
# query线性变换 hidden_state维度为[batch_size,seq_len,hidden_size]
# mix_query_layer 维度即为[batch_size,seq_len,all_head_size]
mixed_query_layer = self.query(hidden_states)
# If this is instantiated as a cross-attention module, the keys
# and values come from an encoder; the attention mask needs to be
# such that the encoder's padding tokens are not attended to.
# key,value张量维度变换与query 一致
if encoder_hidden_states is not None:
mixed_key_layer = self.key(encoder_hidden_states)
mixed_value_layer = self.value(encoder_hidden_states)
attention_mask = encoder_attention_mask
else:
mixed_key_layer = self.key(hidden_states)
mixed_value_layer = self.value(hidden_states)
# 将Q,K,V经过转置,得到query_layer,key_layer,value_layer张量维度[batch_size,head_num,seq_len,head_size]
query_layer = self.transpose_for_scores(mixed_query_layer)
key_layer = self.transpose_for_scores(mixed_key_layer)
value_layer = self.transpose_for_scores(mixed_value_layer)
# Take the dot product between "query" and "key" to get the raw attention scores.
# 进行点积计算,利用矩阵乘法,得到attention_score [batch_size,head_num,seq_len,seq_len)
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
# 进行点积缩放,张量维度不变
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
if attention_mask is not None:
# Apply the attention mask is (precomputed for all layers in BertModel forward() function)
attention_scores = attention_scores + attention_mask
# Normalize the attention scores to probabilities.
# 计算softmax
attention_probs = nn.Softmax(dim=-1)(attention_scores)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = self.dropout(attention_probs)
# Mask heads if we want to
if head_mask is not None:
attention_probs = attention_probs * head_mask
#计算attention,将softmax结果与value_layer进行矩阵乘法,得到[batch_size,seq_len,seq_len,head_size]
context_layer = torch.matmul(attention_probs, value_layer)
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
# 将attention concat 成[batch_size,seq_len,all_head_size]
context_layer = context_layer.view(*new_context_layer_shape)
outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
return outputs
如果没读懂,可以留言,谢谢。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









