





本文翻译自Nature上刊载的论文Human-level Concept Learning through Probabilistic Program Induction
人类对新概念的学习能够从一个简单示例推广,而机器学习算法通常需要数万的样本才能达到同样的准确度。人类也能比算法更丰富地运用学到的概念——如行为,想象和解释。本文提出一种能够在一大类简单视觉概念上(字母的手写字符)具有同样能力的计算模型。这个模型将概念表示为在贝叶斯准则下对样本解释最好的简单规划。极具挑战的一次分类任务上达到了人类的水平,同时击败近来的深度学习方法。本文也做了几个“视觉图灵测试”来探测模型的推广能力,很多案例上都表现地与人类相差无几。
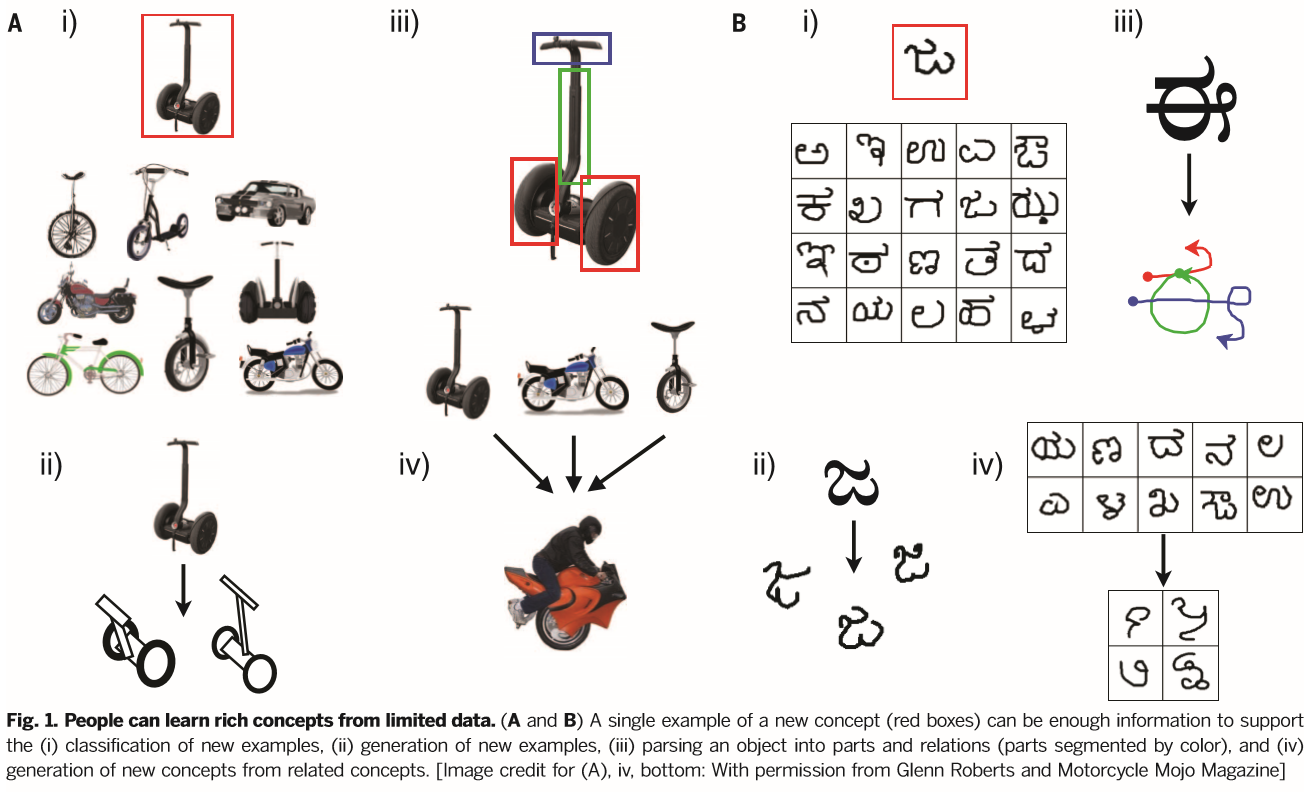
尽管人工智能与机器学习进展巨大,但人类的两方面的概念知识并未包含。首先,对大多数的自然或人为的有趣的分类,人类可以从仅仅少数的例子中就学到概念,而标准的机器学习算法中却需要数万的例子才能达到相同的表现。例如,人类对新事物二轮车(Fig. 1A)仅需看到一个例子就能抓住这个概念的边界,就连小孩都能通过“一次学习”做有意义的推广。相反,许多领先的机器学习方法都是数据饥渴的,尤其是在物体和语音识别基准上取得表现出新水准的“深度学习”模型。其次,人类比学习更丰富的表达,甚至简单的概念(Fig. 1B),在大范围的函数内使用它们,包括(Fig. 1 ii)创造新的标本,(Fig.1 iii)将物体解析为部分和联系,和(Fig. 1 iv)基于已有物体的分类创造新的抽象分类。相反,最好的分类器也不会有这些额外的极少研究且需特定算法的功能。挑战在于解释着两方面的人类水平的概念学习:人类是怎样少数的例子中学习的?人类是怎样这种抽象、丰富与弹性的表达的?当将两者结合起来时就会面临更大的挑战:怎样成功地从如此稀疏的数据中学习并创造如此丰富的表达?对任何学习理论而言,要获得好的推广准则,模型越复杂,需要数据越多而不是越少,通常性能的区别在于新或旧的样本。然而,人们驾驭这种平衡似乎十分敏捷,从稀疏的数据学习丰富的概念并泛化地很好。
本文引入贝叶斯规划学习(Bayesian Program Learning,BPL)框架,能够从仅仅一个样本中学习到一大类视觉概念,并且用与人类几无差别的方法推广。概念表示为简单的概率规划——即用抽象语言描述的结构化过程所表达的概率生成模型。这个框架将复合性、因果性和学习这三种在过去几十年分别在认知科学与机器学习中影响巨大的概念结合在了一起。就规划而言,丰富的概念简单的原语建立起来。它们的概率语义(不像其他概率模型)以结构的过程的形式处理噪音并支持创造性的推理,而这种结构过程能自然地抓住现实世界产生类别样例过程的抽象的“因果“结构。学习通过构造贝叶斯准则下最好地解释样例的规划来进行;通过发展层次先验来”学习怎样学习“,而这种先验允许先前的经验及其相关概念来易于新概念的学习。这些先验表示学到的归纳的偏好,这些偏好抽象出保持给定领域内概念种类(或标记)的关键规律和变化维度。总之,BPL能通过重使用存在样本的片段、获取现实世界多尺度生成模型过程中的因果和复合关系来构造新的规划。
除了发展上述方法的梗概外,我们直接比较了人类、BPL和其他计算方法在一个有五种挑战性的概念学习任务集上的表现(Fig. 1B)。这些任务使用Omniglot中简单的视觉概念,这些概念是我们收集的一个包含了来自50种书写体系的1623个书写字符样本的数据集(Fig. 2)。图片和笔画都在在线提供材料的Section S1详细描述了。手写非常适宜用来在相对平等的基础上来比较人类和机器学习:它们都是认知自然的并经常作为比较学习算法的基准。机器学习算法通常是在每个类别经过数十万的训练数据之后评估,而我们使用最具挑战性的方式来评估这些分类、解析(Fig. 1B, iii)和生成(Fig. 1B, ii)的任务:一个概念仅用一个样本。我们也探究了让人和计算模型生成新的概念(Fig. 1B, iv)这样更具创造性的任务。我们将BPL与三种深度学习模型、一种经典模式识别算法和几种这个模型的毁损版——大量的比较用来隔离模型每个成分的功能(替代模型的描述见Section S4)。我们与两类深度卷积网络(现在领先的物体识别算法的代表)和一种层次网络(HD)模型 (一种我们需要更加生成的任务和专门的一次学习的概率模型)作比较。

贝叶斯规划学习(BPL)
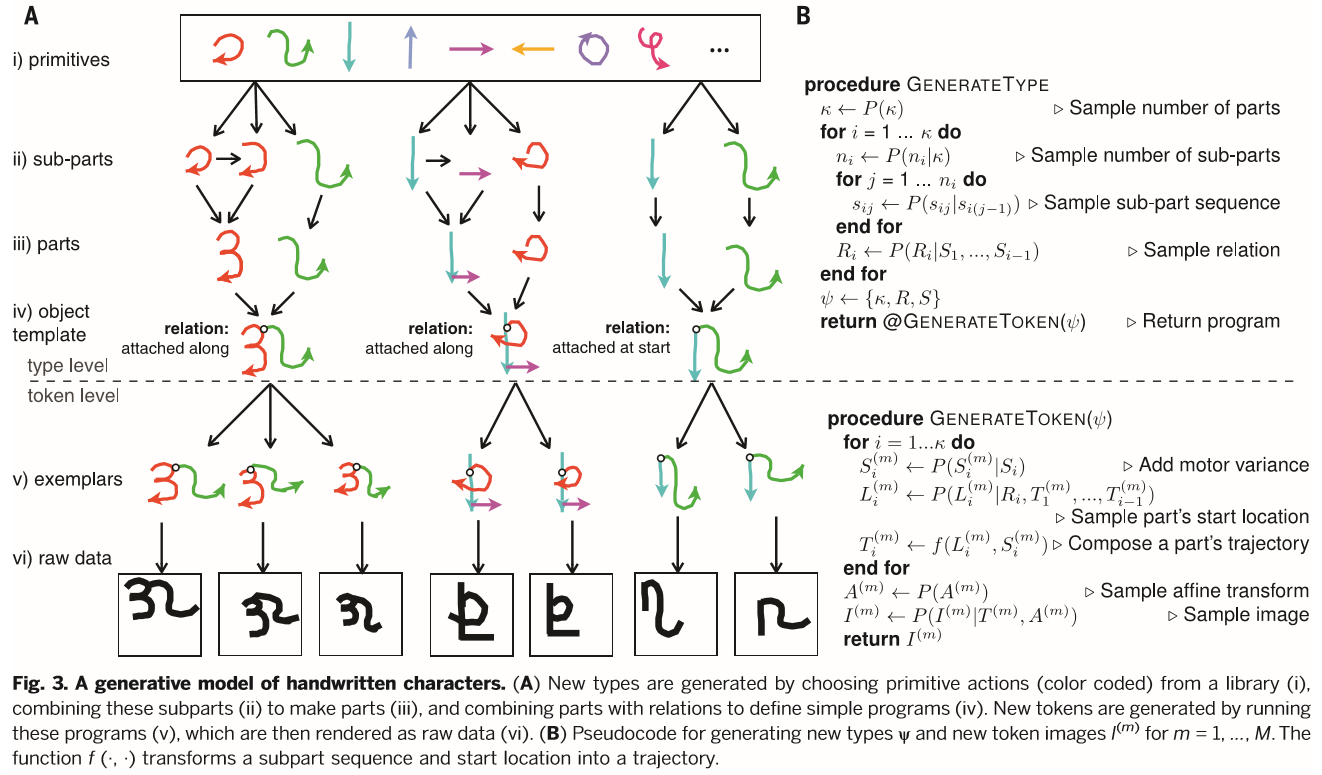
BPL方法学习简单随机的规划来表达概念,从部件(Fig. 3A, iii)、子部件(Fig. 3A, ii)和空间关系(Fig. 3A, iv)复合地构建。BPL定义了一种能通过以新方式组合部件与子部件来尝试新类型概念的生成式模型。每种类型也表达为一个生成式模型,这种低层生成模型又产生概念的新样本(或标记)(Fig. 3A, v),使BPL成为一个生成模型的生成模型。最后一步实施原始数据形式的标记层变量(Fig. 3A, vi)。类型
Ψ
——
M
种标记的集合
类型 P(Ψ) 和标记 P(θ(m)|Ψ) 的生成由Fig. 3B中的伪代码描述并在Section S2中与图片模型 P(I(m)|θ(m)) 一起有详述。源代码在网上可以下载。模型通过调整每个条件概率到来自30个字母的背景字符集来学习怎样学习,利用图片和笔画数据,这个图片集也同样用来预先训练供选择的深度学习模型。任何产生数据或这个集合中的字符在随后的评估任务都不会再被使用,只向模型提供新字符的原始图片。
手写字符类 Ψ 是部件、子部件和关系的抽象模式,反映手写过程的 因果结构,字符部件 Si 是由按下笔开始至提起笔终结的笔画(Fig. 3A, iii),而子部件 si1,…,sin 则是更原始的由笔的简短停顿所间隔的移动(Fig. 3A, ii)。要创建一个新字符类型,从背景集测量到的它们的经验分布,首先模型尝试部件数目 κ 和子部件数目 ni ,对每个部件都有 i=1,…,κ 。然后,一个部件 Si 的模板就通过对子部件抽样而构建得到,而子部件则来自一个从背景集学习到的离散原语的行为集(Fig. 3A, i),因而后来的行为则取决于前面的。接着,部件通过对每个子部件尝试控制点和尺度系数成为基础是系数化的曲线(样条)。最后,部件概略地被放置使得原点独立的、在起点、在终点或与前面的部件一起。
字符标记 θ(m) 通过执行部件、关系与墨水从笔中流出到纸上的模型而得到。首先,马达噪声被添加到了控制点和子部件的尺度来创造标记层次的笔画轨迹 S(m) 。然后,轨迹的精确起始位置 L(m) 从原理图抽样而得,而原理图则由它与前一个笔画的关系 Ri 所提供。接着,抽样得全局的转换,包括仿射包 A(m) 和适应的易于概率推断的噪声参数。最后,一个二值图像 I(m) 由一个随机生成的渲染函数创建,用灰度墨水来给笔画轨迹划线,将像素值解释为独立伯努利概率。
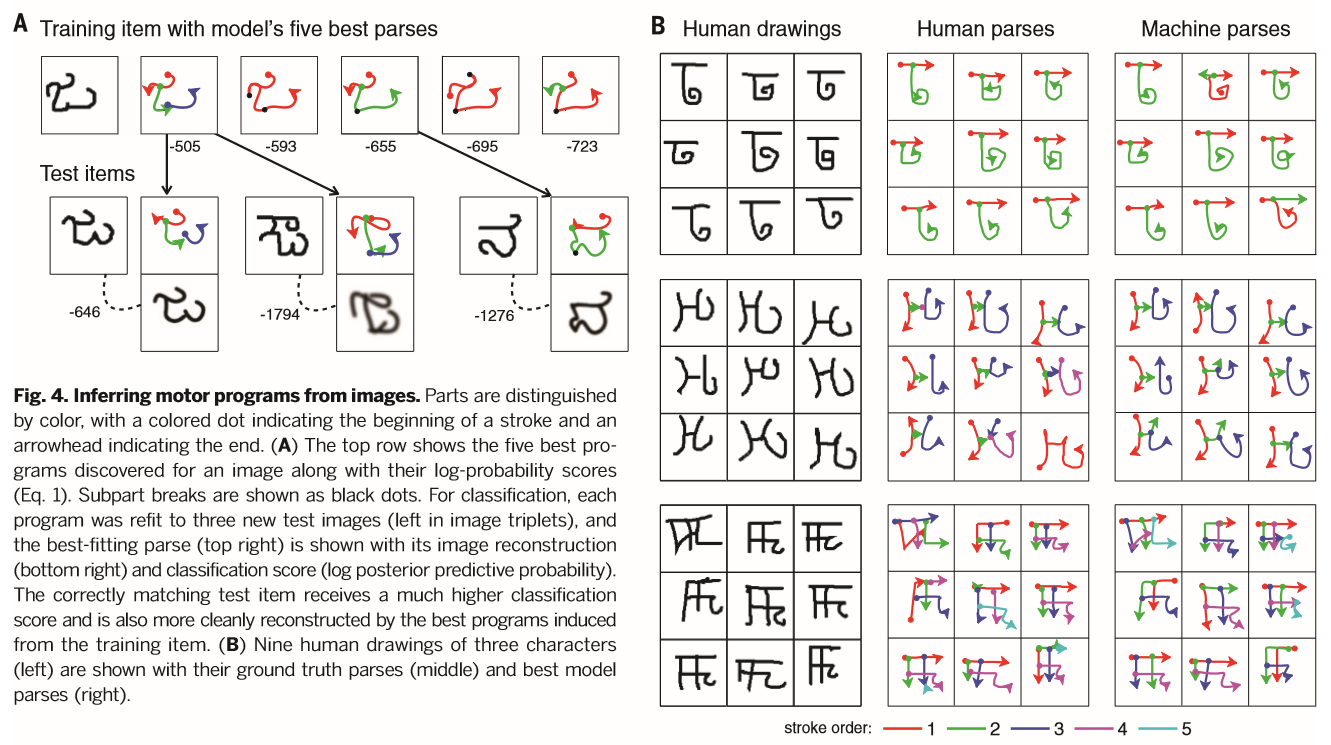
后验推断要求搜索可能产生原始图像 I(m) 的规划的庞大组合空间。我们的策略是使用快速自底向上的方法来得到许多候选解析。最有希望的候选者通过使用连续优化和局部搜索来提取,形成后验分布 P(Ψ,θ(m)|I(m)) 的离散估计(Section S3)。Figure 4A展示了一张图片 I(1) 发掘的规划集和怎样重适应它们到不同的测试图片 I(2) 来计算分数 logP(I(2)|I(1)) (对数后验预测概率),分数越高表明它们越有可能属于同一类。当至少有一个部件与关系集合能成功地解释训练和测试图像时就会得到高分,不违背学到的类内可变性模型的软约束。Figure 4B在一些字符上将模型的最优得分解析与地面实况人解析进行比较。
结果
人类,BPL以及供选择的模型在5个概念学习任务上一起比较,这些任务测试从少数示例中不同形式的推广能力。所有活动的实验都通过亚马逊Mechanical Turk上运行,测试的过程在Section S5详述。主要的结果总结为Fig. 6,另外的毁损分析与控制在Section S6中报告。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









