







在雷达系统、电子战、无线通信等领域中,对射频信号的处理能力直接决定了系统的性能上限。而随着技术的不断进步,射频直接采样架构(RF Direct Sampling)作为一种全新的射频架构,正在逐步成为射频系统设计中的关键技术,带来前所未有的高精度、低成本和效率提升。

什么是射频直接采样?
传统的射频架构中,射频信号的处理往往依赖于多级的下变频组件,就是将高频的射频信号先通过滤波器、混频器等模拟电路降低到较低的中频(IF)或基带频率,然后再进行模数转换(ADC)。
这种方法的缺点是电路复杂度高、成本高、功耗大,且引入了额外的失真与噪声来源。
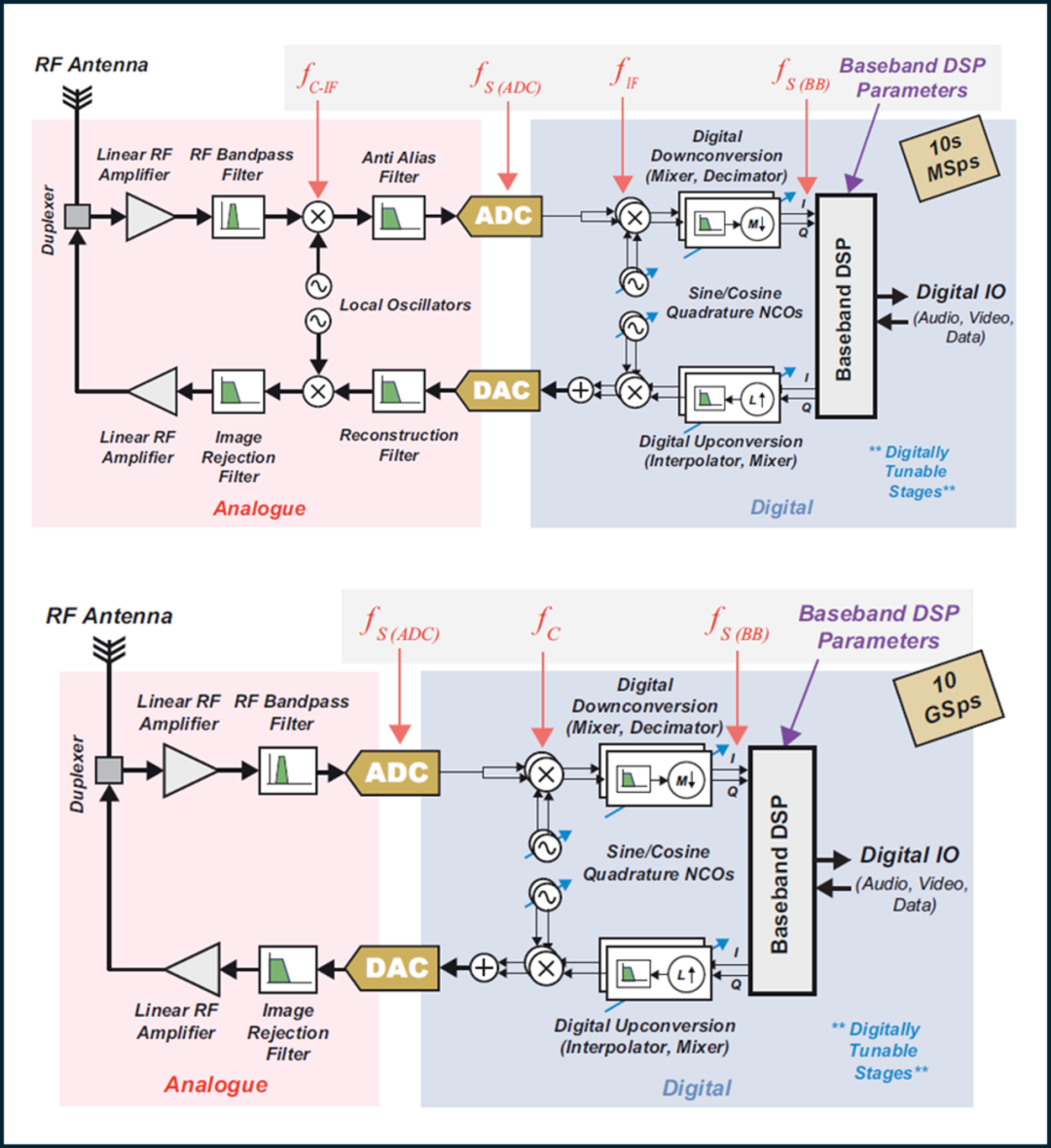
图1:数字中频采样架构(上)与射频直接采样(下)架构
而射频直接采样架构的出现,则直接打破了这一传统框架,实现了从射频前端到数字域的直接转换。
在射频直接采样架构中,射频信号首先会经过低噪声放大器(LNA)和滤波器(Filter)后,然后直接进入高速模数转换器(ADC)进行采样,极大地简化了系统结构,降低了成本,提升了精度。
直接采样的成本优势
硬件架构的简化,最为直接的改变就是硬件成本的降低。
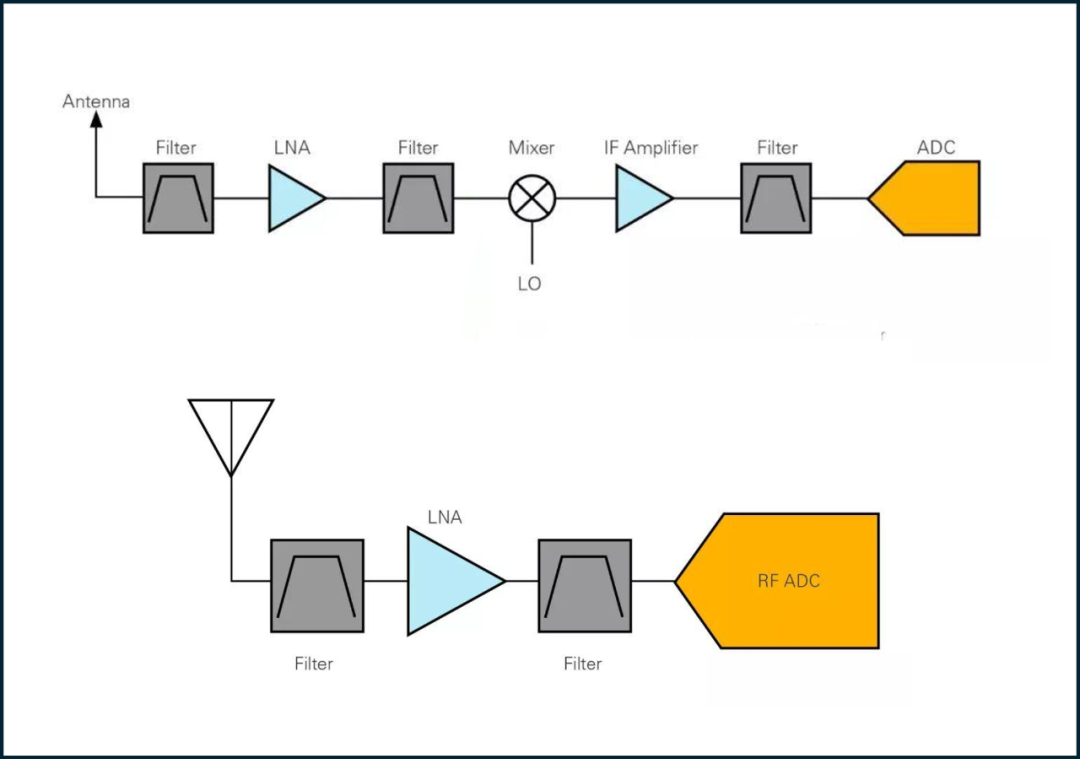
图2:超外差架构接收器(上)与射频直接采样接收器(下)的组成
可以通过两种架构的构成看到,射频直接采样架构由于不需要模拟频率转换,直接对高频射频信号进行采样,从而显著减少了系统所需的元件数量,比如混频器、本地振荡器(LO)等关键组件。
要知道在常规的超外差射频系统中,变频相关器件(混频器和本地振荡器等)的成本可能会占到整个射频系统硬件成本的一半甚至更高。射频直接采样架构由于不需要在模拟电路进行变频,所以系统整体的硬件成本能够实现大幅度的下降。
此外,由于变频器件的减少和硬件结构的简化,系统的故障率和使用成本也将大幅下降。并且,工程师也不再需要对复杂的变频器件进行测试和调试,相对应的高精度仪器的采购/租赁成本、人工调试成本都会大幅减少,从而缩减整个系统的开发成本和周期。
直接采样的高精度优势
射频直接采样架构由于不需要变频,所以能够在射频前端省略掉大量的模拟电路元件。对于复杂的射频系统来说,这种改变可能会减少几个甚至十几个模拟电路原件,而原本这些有源器件都会产生大量的噪声、谐波和杂散,给之后的数字信号处理带来很多阻碍。
这种“数字化尽早”的策略不仅简化了硬件设计,还减少了模拟电路带来的非理想效应,如相位噪声、本振泄漏、杂散和谐波、群时延失真等,提升了系统的整体性能。
此外,射频直接采样架构还能够捕获更宽频带内的信号细节,减少了信号在模拟处理过程中的损失和畸变,同时具备出色的无杂散动态范围(SFDR)、噪声系数(NF)和低失真特性,能够更准确地还原原始信号,为后续的数字信号处理(DSP)提供更高精度、高质量的数据源。

如何实现射频直接采样?
射频直接采样的最大限制是高速、高分辨率转换器的发展(模数转换器ADC与数模转换器DAC),在近年来转换器技术得到快速发展之前,由于转换器采样率和分辨率的限制,直接采样架构其实并不实用。
而随着超高速、高分辨率转换器的不断涌现,射频直接采样技术目前已能在L波段(1~2 GHz)、S波段(2~4GHz)、C波段(4~8GHz)和X波段(8~12GHz)实现极高的瞬时带宽数字化,使其已经能够满足雷达与电子战系统、无线通信等领域对高速、高精度数据处理的迫切需求。
下面我们就从接收链路中的ADC和发射链路中的DAC,简单介绍一下射频直接采样的具体实现方式与技术原理。
ADC:欠采样与混叠
采样是将模拟信号转换为数字信号的两个步骤之一(另一个步骤是量化)。而根据奈奎斯特采样定理,在进行模拟/数字信号的转换过程中,当采样频率fs.max大于信号中最高频率fmax的2倍时(fs.max>2*fmax),采样之后的数字信号可以完整地保留原始信号中的信息。但实际上,目前的高性能ADC的采样频率往往达不到目标信号频率的两倍。
那么,当采样频率 fs.max < 2*fmax时,ADC就会因为欠采样而出现信号混叠的现象,导致信号频率会被搬移到较低的频域。
正常来说,工程师一般会极力避免出现混叠现象。但在射频直接采样中,我们却可以巧妙的利用混叠现象,故意将目标信号折叠到第一奈奎斯特区,从而实现用较低的采样频率对高频带通信号进行采样,大幅节省系统的成本、功耗、PCB 面积及模拟前端设计复杂度。
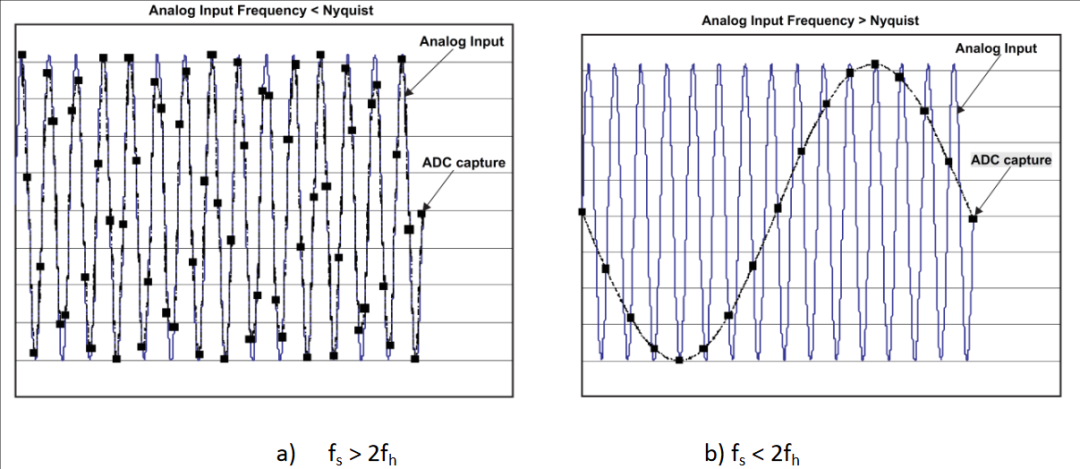
图3:当用低于信号频率的采样频率采样时得到了一个“低频”信号
并且由于混叠的频率是完全可预测的,所以工程师可以针对性的定义奈奎斯特区,将感兴趣的信号完全包含在一个奈奎斯特区内,避免因混叠成分的叠加而被破坏。这个过程中需要使用到滤波器将不感兴趣的频段过滤掉,同时去掉了多余的噪声,最后再将信号送入ADC的输入端。
经过巧妙的设计,ADC就可以实现对高频射频信号的精准采样。以立思方自研的中频模块IC2784为例,其可以对高达8GHz射频信号进行直接采样,瞬时带宽可以达到1.2GHz。
DAC:插值与数字信号处理
同接收链路类似,发射链路中输出的射频信号频率,也与DAC的采样频率息息相关。常规模式下,输出信号的最大频率仅为DAC采样频率的一半。而要想输出更大高频率范围的信号,就需要应用到DAC中的插值和数字信号处理技术。
通过DAC插值将输入的低采样率信号转换成高采样率信号,再利用DAC内部的时钟倍频数字混频器和插值滤波器,实现异相插值、补零等插值处理。最终使得DAC在第二、第三甚至第四奈奎斯特区内重构RF载波,同时仍保持出色的动态范围。
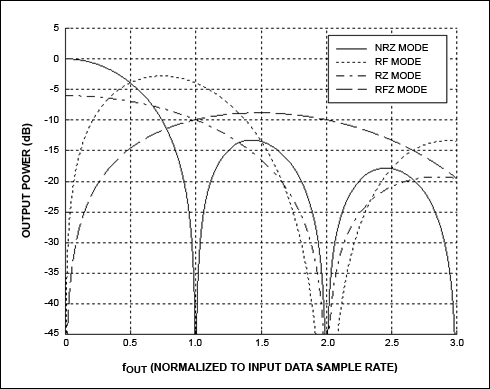
图4:DAC在各种工作模式下的归一化频率响应
以立思方自研的中频模块IC2784为例,可以直接生成最高7.5GHz的输出射频信号。


立思方的射频直接采样方案
目前,立思方已能够为用户提供完整的射频直接采样方案,应用于包括实时频谱分析、落盘回放、仿真雷达、目标模拟等射频系统中。大幅简化系统的硬件架构,并降低系统建设成本。
在方案中,除了高采样率、高分辨率的PXIe中频模块外,还会使用到PXIe射频直采调理模块IC8222,该模块的功能主要是对射频信号进行滤波和功率控制(增益和衰减)、保障系统整体的性能和效率。
可以预见的是,未来在雷达和电子战领域,由于成本的大幅降低以及灵活性的巨大提升,将使得经过前端简化的射频直接采样架构逐渐成为替代常规超外差架构的理想选择,为用户带来更加高效、便捷、可靠的解决方案。

















 9694
9694

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









