






贝叶斯决策论
贝叶斯决策轮是基于贝叶斯理论的决策方法。先来说一下贝叶斯公式。
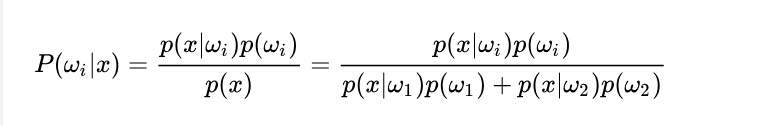
如果先验概率给出,并且知道了条件概率,那么就可以通过贝叶斯公式求出后验概率。并根据这个概率得到一个最优决策,谓之贝叶斯决策。
如果先验概率P(0),P(1)已知,条件概率P(x|1)和P(x|0)也已知,可以计算得到无条件概率:P(x)=P(0)P(x|0)+P(1)P(x|1);后验概率P(0|x)= P(0)P(x|0)/P(x),P(1|x)=P(1)P(X|1)/P(x),如果P(0|x)>P(1|x),判决为0,反之判决为1,如果相等,选谁都一样,此之谓”贝叶斯决策最优“。
如果先验概率P(0),P(1)已知,条件概率P(x|1)和P(x|0)也已知,可以计算得到无条件概率:P(x)=P(0)P(x|0)+P(1)P(x|1);后验概率P(0|x)= P(0)P(x|0)/P(x),P(1|x)=P(1)P(X|1)/P(x),如果P(0|x)>P(1|x),判决为0,反之判决为1,如果相等,选谁都一样,此之谓”贝叶斯决策最优“。
虽然贝叶斯得到的结果是最优的,但是却不常用。因为贝叶斯决策中假设比较强,实际操作起来并不容易:
我们无法获得真实的先验概率等其他计算要件,需要通过统计学方法进行估计,存在一定的误差。
很多条件概率也不能求出来,因为有些问题所涉及到的条件太多了。综上所述,直接利用贝叶斯理论进行后验概率估算是不大实用的。但对于理论上计算边界(bound),尤其是误差的上界比较有意义。
朴素贝叶斯分类器
朴素贝叶斯分类的基础也是贝叶斯公式,特别之处在于朴素。啥意思呢??它是英文单词 naive 翻译过来的,意思就是简单的,朴素的。(它哪里简单呢,后面会看到的:它假设一个事件的各个属性之间是相互独立的,这样简化了计算过程;这个假设在现实中不太可能成立,但是,研究表明对很多分类结果的准确性影响不大。)
基于贝叶斯公式来估计后验概率P( c | x )的主要困难在于:类条件概率P( x | c )是所有属性上的联合概率,难以从有限的训练样本直接估计而得。因此朴素贝叶斯分类器采用了“属性条件独立性假设”:对已知类别,假设所有属性相互独立。也就是说,假设每个属性独立的对分类结果发生影响。
基于属性独立性假设,后验概率P( c | x )可写为
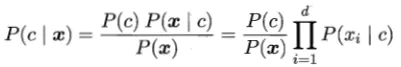
显然朴素贝叶斯分类器的训练过程就是基于训练集D来估计类先验概率P( c ),并为每个属性估计条件概率P( x|c )。
由于对所有类别来说P( x )相同,因此贝叶斯判定准则有
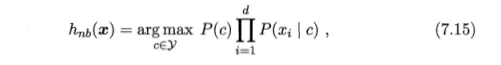

半朴素贝叶斯分类器
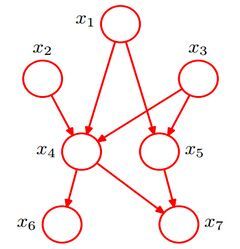
朴素贝叶斯的“属性条件独立性假设"在现实生活中往往很难成立。由此有了半朴素贝叶斯分类器,适当考虑一部分属性之间的相互依赖关系。“独依赖估计” (One-Dependent Estimator ,简称 ODE)是半朴素贝叶斯分类器最常用的一种策略。"独依赖"就是假设每个属性在类别之外最多仅依赖于一个其他属性,即

问题转化为确定每个属性的父属性。
假设有一个“超父”属性,是所有属性的父属性。图b中X1是超父属性。这个叫做SPODE (Super-Parent ODE)方法。

TAN算法类似于最大带权生成树,将属性作为节点构建树,节点之间的连线表示两者之间的关系。



贝叶斯网络
贝叶斯网络(Bayesian network),又称信念网络(Belief Network),或有向无环图模型(directed acyclic graphical model),是一种概率图模型,于1985年由Judea Pearl首先提出。它是一种模拟人类推理过程中因果关系的不确定性处理模型,其网络拓朴结构是一个有向无环图(DAG)。
贝叶斯网络的有向无环图中的节点表示随机变量{X1,X2,…,Xn}
它们可以是可观察到的变量,或隐变量、未知参数等。认为有因果关系(或非条件独立)的变量或命题则用箭头来连接。若两个节点间以一个单箭头连接在一起,表示其中一个节点是“因(parents)”,另一个是“果(children)”,两节点就会产生一个条件概率值。
例如,假设节点E直接影响到节点H,即E→H,则用从E指向H的箭头建立结点E到结点H的有向弧(E,H),权值(即连接强度)用条件概率P(H|E)来表示,如下图所示:

简言之,把某个研究系统中涉及的随机变量,根据是否条件独立绘制在一个有向图中,就形成了贝叶斯网络。其主要用来描述随机变量之间的条件依赖,用圈表示随机变量(random variables),用箭头表示条件依赖(conditional dependencies)。
此外,对于任意的随机变量,其联合概率可由各自的局部条件概率分布相乘而得出:
P(x1,…,xk)=P(xk|x1,…,xk−1)…P(x2|x1)P(x1)
EM算法
EM算法是一种迭代优化策略,由于它的计算方法中每一次迭代都分两步,其中一个为期望步(E步),另一个为极大步(M步),所以算法被称为EM算法(Expectation Maximization Algorithm)。EM算法受到缺失思想影响,最初是为了解决数据缺失情况下的参数估计问题。其基本思想是:首先根据己经给出的观测数据,估计出模型参数的值;然后再依据上一步估计出的参数值估计缺失数据的值,再根据估计出的缺失数据加上之前己经观测到的数据重新再对参数值进行估计,然后反复迭代,直至最后收敛,迭代结束。
介绍EM算法首先需要了解:极大似然估计和Jensen不等式。
初始化分布参数θ; 重复E、M步骤直到收敛:
E步骤:根据参数θ初始值或上一次迭代所得参数值来计算出隐性变量的后验概率(即隐性变量的期望),作为隐性变量的现估计值。
M步骤:将似然函数最大化以获得新的参数值。
优点:算法简单,稳定上升的步骤能非常可靠地找到“最优的收敛值 。
缺点:对初始值敏感,EM算法需要初始化参数θ,而参数θ的选择直接影响收敛效率以及能否得到全局最优解。
EM算法应用于:
K-means聚类:E步骤为聚类过程,M步骤为更新类簇中心。
GMM(高斯混合模型)。















 2972
2972











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









