







0. 前言
- 相关资料:
- 论文基本信息
- 领域:行为识别
- 作者单位:南京大学&商汤研究院
- 发表时间:2020.5,ICLR 2021
- 一句话总结:提出了一种新的block结构,在BottleNeck的非skip分支中添加了仅处理时间维度信息的自适应卷积结构。
1. 要解决什么问题
- 深度学习领域,视频相关研究比图像相关研究少/慢一些。
- 视频相比于图像,其主要区别在于,除了要考虑空间特征,还需要考虑时间特征。
- 在行为识别领域,要解决的主要问题就是 高效提取视频的时空特征,这也就是本文的目标。
- 现在提取视频特征的主流方法是使用3D卷积,但3D卷积存在针对性差、计算量高的缺陷。
- 对3D卷积的优化主要集中在两个研究方向:
- 基于2D卷积的时间特征提取模块。
- 设计专门用于时间特征提取的模块(而不是向3D卷积那么粗糙的方法)。
2. 用了什么方法
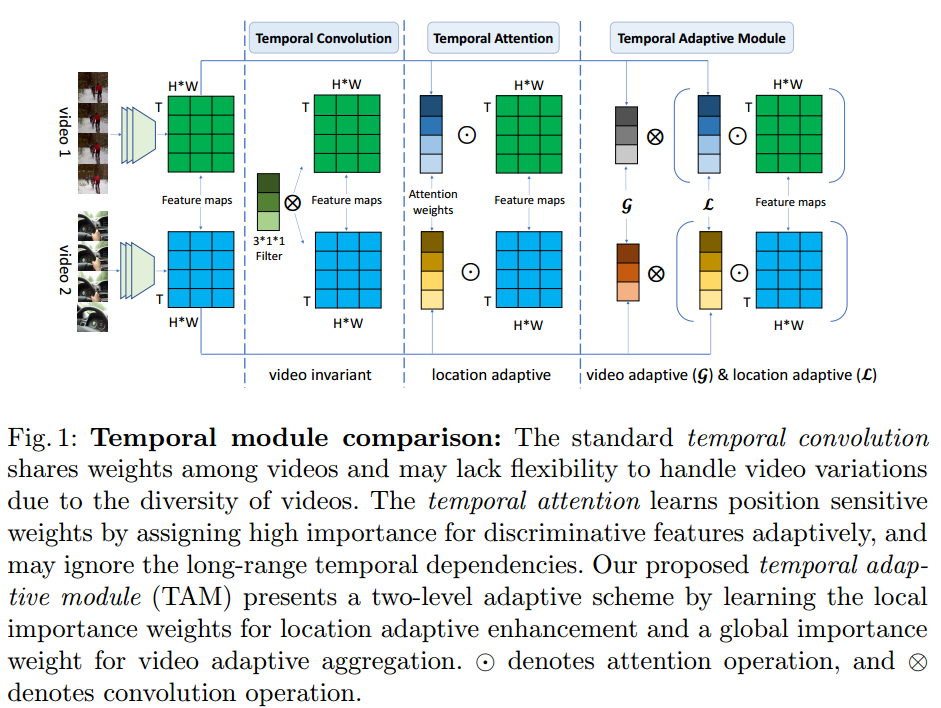
- 提出了一种新的时间自适应结构(temporal adaptive module,TAM)。
- 这种模块的关键在于,对于不同的视频有不同的处理,adaptive temporal kernels。(这种说法很有意思)
- 在看了下面的网络结构后发现,在TAM模块内,卷积核会改变,特征图也做了处理。
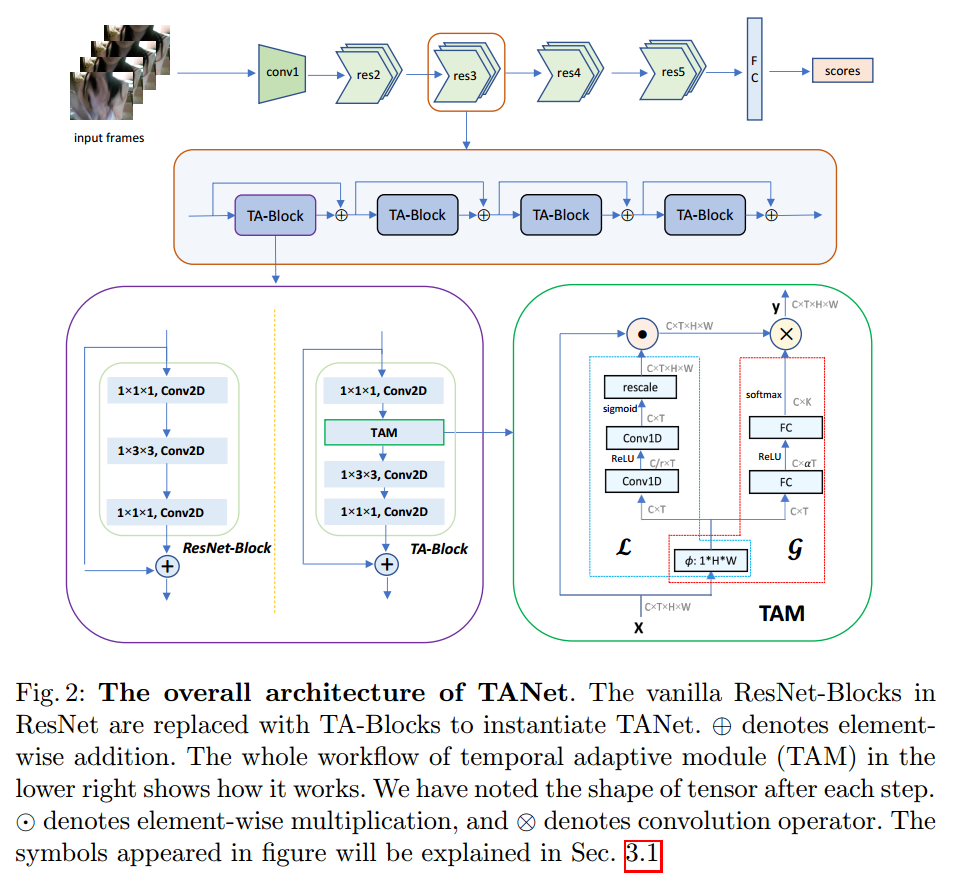
- TAM模块结构示意图如下(这张图TAM并不直观,还是下面一张图显示的TAM直观):
- TANet结构示意图如下:
- local branch 用于提取短期信息,global branch用于提取长期信息。
- 其实看源码更好。
3. 效果如何
-
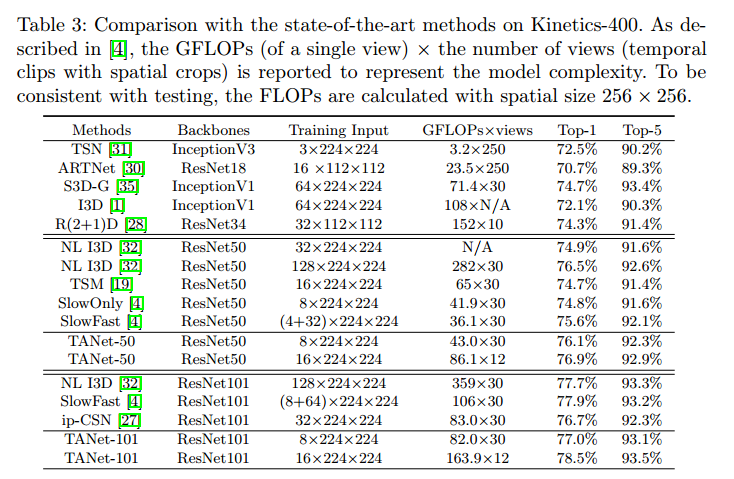
在 Kinetics-400 上达到SOTA
-
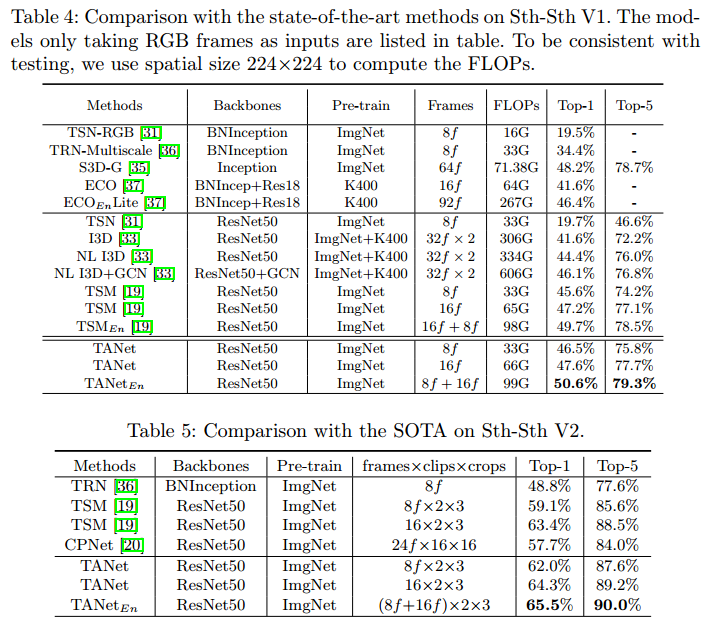
在Something-Something上也到SOTA
4. 还存在什么问题
- 说是在同样FLOPs下性能更好,但测试基础是ResNet。
- 等代码开源了之后想尝试下在MobileNet等网络上是否有效果。
- 浏览了源码
- 完全基于TSN/TSM的源码改写的,改的内容非常少,要在mmaction2中复现应该非常容易。
- 提供了两类主干网络, resnet 和 bninception,但预训练模型只有R50的。















 330
330











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









