







趁着现在有空再写一篇吧,以后忙起来可能就更新得慢了。
前面我们讨论了回归问题,下面我们来说一说分类问题。
Logistic function
先从最简单的二值分类(binary classification)问题说起,也就是说y只能取1或者0两个值,其中,0称为负类别(negative class),1称为正类别(positive class),也可以分别用“-”号和“+”号表示。
如果我们任性一点,忽略y是离散值的事实,直接用线性回归来预测,我们会发现一些问题。最直观的就是,如果模型的预测值大于1或小于0将会没有意义,因为y只能取1和0两个值。
于是我们想,能不能找一个函数,它的输出值就在0和1之间呢?的确可以。我们可以选择
这里 g(z)=11+e−z 被称为 logistic function或者叫 sigmoid function,它的函数图像是这样的:
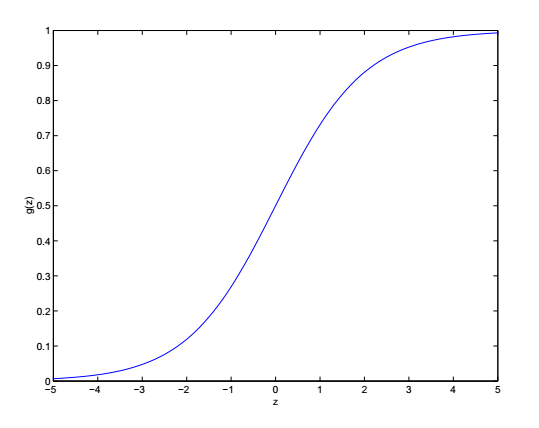
当z趋近于正无穷时函数值趋近于1,当z趋近于负无穷时函数值趋近于0。
我们可能要问了,函数值在0和1之间的函数肯定不止这一个,我们选别的行不行?当然可以,但logistic function有很多好处,这在后面我们会慢慢体会到。我们先来推一遍它的导数:
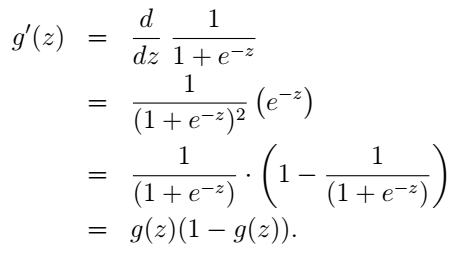
OK,有了它的导数,在后面的计算中我们就可以直接拿来用啦。
参数学习
现在我们有了这个模型,就可以考虑怎么通过训练样本学习出参数
θ
了。很自然的,我们的第一个想法就是和线性回归一样,令它的代价函数为
J(θ)=12∑mi=1(hθ(x(i))−y(i))2
,然后最小化J。但很不幸,上次我们的代价函数一猜就中,这次可没那么好运咯,哪儿能回回都给你蒙对呢是吧,哈哈。为什么不行呢?还记得我们之前提到过的局部最小值的问题吗?对于logistic function,这样的代价函数是非凸的,存在多个局部极小值,所以它并不是一个好的选择。那怎么办呢?我们不是曾从概率角度解释了线性回归的代价函数么?(不知道的同学请看这里)可不可以参考这个思路呢?那我们就来试一试吧。
首先我们假设:
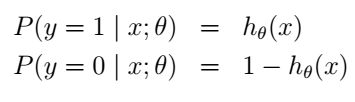
这个很合理吧。我们还可以把它写得更紧凑一点:
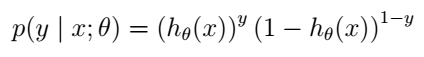
如果m个训练样本是相互独立的,那么似然函数依然是单个样本的乘积: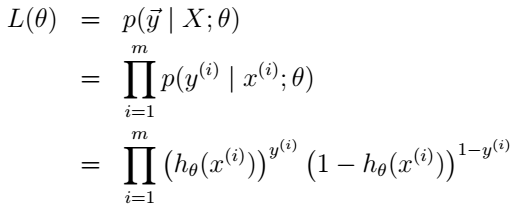
和前面一样,我们选择最大化对数似然函数:
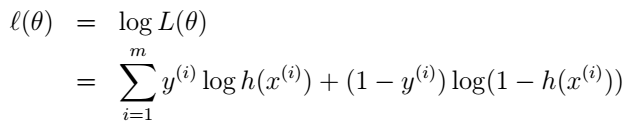
那我们怎么最大化它呢?你又一次站在了山坡上,不过这次你不是去谷底了,你要征服高山,你要上山顶了。所以,我们还是要沿着高度变化最快的方向走,不过这次是沿着梯度的方向,而不是梯度的反方向了。好,那我们就来求它的偏微分吧,我们直接采用stochastic gradient ascent(注意,这里是梯度上升啦),也就是每次更新时只考虑一个样本:
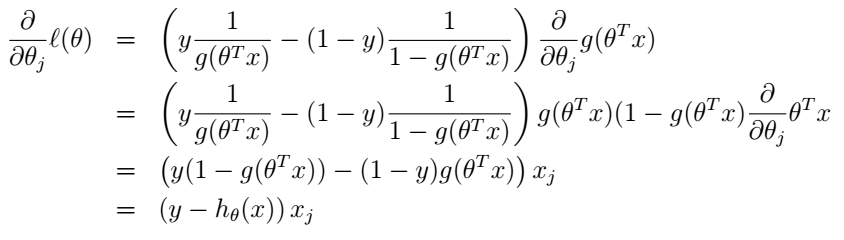
在上式中,我们直接使用了g(z)的导数,也就是前面推过的结论。因此我们的更新规则就是:
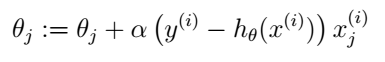
诶?有没有发现什么?这个式子怎么长得和LMS更新规则那么像?的确是,但它们并不是同样的算法,因为这里的h已经是
θTx(i)
的一个非线性函数了。但为什么我们用了不同的算法却得到了相似的更新规则呢?这是巧合吗?听说不是,后面我们再一起研究吧!^_^















 4560
4560











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









